Учебник по sqlite3 в python
Содержание:
Player Table
# Dimensionsplayer_table.shape(11060, 7)# player_table.info()Data columns (total 7 columns):id 11060 non-null int64player_api_id 11060 non-null int64player_name 11060 non-null objectplayer_fifa_api_id 11060 non-null int64birthday 11060 non-null objectheight 11060 non-null float64weight 11060 non-null int64dtypes: float64(1), int64(4), object(2)
Accessing the first 5 records of Player table
player_table.head()
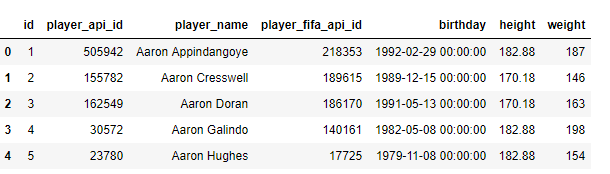
Now we have a pandas dataframe, and we can easily work with this to get desired information e.g:
Finding all the players with height > 150 cm.
height_150 = pd.read_sql_query("SELECT * FROM Player WHERE height >= 150 ", con)
Similarly you can explore all the other tables further to get other meaningful insights. Please find the code in the Jupyter notebook below. The code is self explanatory.
Conclusion
In this tutorial, we have seen how easy it is to to get started with SQLite database operations via Python. The module is very simple to use and comes in very handy when dealing with large data systems. I hope you found this article useful. Let me know if you have any doubt or suggestion in the comment section below.
Version Control
If you are reading this on GitHub or some other Git repository or service,
then you are looking at a mirror. The names of check-ins and
other artifacts in a Git mirror are different from the official
names for those objects. The offical names for check-ins are
found in a footer on the check-in comment for authorized mirrors.
The official check-in name can also be seen in the file
in the root of the tree. Always use the official name, not the
Git-name, when communicating about an SQLite check-in.
If you pulled your SQLite source code from a secondary source and want to
verify its integrity, there are hints on how to do that in the
section below.
Connecting to or creating a database¶
Database objects are constructed by passing in either a path to a file on disk or an existing SQLite3 database connection:
from sqlite_utils import Database
db = Database("my_database.db")
This will create if it does not already exist.
If you want to recreate a database from scratch (first removing the existing file from disk if it already exists) you can use the argument:
db = Database("my_database.db", recreate=True)
Instead of a file path you can pass in an existing SQLite connection:
import sqlite3
db = Database(sqlite3.connect("my_database.db"))
If you want to create an in-memory database, you can do so like this:
db = Database(memory=True)
Tables are accessed using the indexing operator, like so:
table = db"my_table"
If the table does not yet exist, it will be created the first time you attempt to insert or upsert data into it.
You can also access tables using the method like so:
table = db.table("my_table")
Python sqlite3 模块 API
以下是重要的 sqlite3 模块程序,可以满足您在 Python 程序中使用 SQLite 数据库的需求。如果您需要了解更多细节,请查看 Python sqlite3 模块的官方文档。
| 序号 | API & 描述 |
|---|---|
| 1 |
sqlite3.connect(database )
该 API 打开一个到 SQLite 数据库文件 database 的链接。您可以使用 «:memory:» 来在 RAM 中打开一个到 database 的数据库连接,而不是在磁盘上打开。如果数据库成功打开,则返回一个连接对象。 当一个数据库被多个连接访问,且其中一个修改了数据库,此时 SQLite 数据库被锁定,直到事务提交。timeout 参数表示连接等待锁定的持续时间,直到发生异常断开连接。timeout 参数默认是 5.0(5 秒)。 如果给定的数据库名称 filename 不存在,则该调用将创建一个数据库。如果您不想在当前目录中创建数据库,那么您可以指定带有路径的文件名,这样您就能在任意地方创建数据库。 |
| 2 |
connection.cursor()
该例程创建一个 cursor,将在 Python 数据库编程中用到。该方法接受一个单一的可选的参数 cursorClass。如果提供了该参数,则它必须是一个扩展自 sqlite3.Cursor 的自定义的 cursor 类。 |
| 3 |
cursor.execute(sql )
该例程执行一个 SQL 语句。该 SQL 语句可以被参数化(即使用占位符代替 SQL 文本)。sqlite3 模块支持两种类型的占位符:问号和命名占位符(命名样式)。 例如:cursor.execute(«insert into people values (?, ?)», (who, age)) |
| 4 |
connection.execute(sql )
该例程是上面执行的由光标(cursor)对象提供的方法的快捷方式,它通过调用光标(cursor)方法创建了一个中间的光标对象,然后通过给定的参数调用光标的 execute 方法。 |
| 5 |
cursor.executemany(sql, seq_of_parameters)
该例程对 seq_of_parameters 中的所有参数或映射执行一个 SQL 命令。 |
| 6 |
connection.executemany(sql)
该例程是一个由调用光标(cursor)方法创建的中间的光标对象的快捷方式,然后通过给定的参数调用光标的 executemany 方法。 |
| 7 |
cursor.executescript(sql_script)
该例程一旦接收到脚本,会执行多个 SQL 语句。它首先执行 COMMIT 语句,然后执行作为参数传入的 SQL 脚本。所有的 SQL 语句应该用分号 ; 分隔。 |
| 8 |
connection.executescript(sql_script)
该例程是一个由调用光标(cursor)方法创建的中间的光标对象的快捷方式,然后通过给定的参数调用光标的 executescript 方法。 |
| 9 |
connection.total_changes()
该例程返回自数据库连接打开以来被修改、插入或删除的数据库总行数。 |
| 10 |
connection.commit()
该方法提交当前的事务。如果您未调用该方法,那么自您上一次调用 commit() 以来所做的任何动作对其他数据库连接来说是不可见的。 |
| 11 |
connection.rollback()
该方法回滚自上一次调用 commit() 以来对数据库所做的更改。 |
| 12 |
connection.close()
该方法关闭数据库连接。请注意,这不会自动调用 commit()。如果您之前未调用 commit() 方法,就直接关闭数据库连接,您所做的所有更改将全部丢失! |
| 13 |
cursor.fetchone()
该方法获取查询结果集中的下一行,返回一个单一的序列,当没有更多可用的数据时,则返回 None。 |
| 14 |
cursor.fetchmany()
该方法获取查询结果集中的下一行组,返回一个列表。当没有更多的可用的行时,则返回一个空的列表。该方法尝试获取由 size 参数指定的尽可能多的行。 |
| 15 |
cursor.fetchall()
该例程获取查询结果集中所有(剩余)的行,返回一个列表。当没有可用的行时,则返回一个空的列表。 |
Python SQLite Connection
This section lets you know how to create an SQLite database and connect to it through python using the sqlite3 module.
To establish a connection to SQLite, you need to specify the database name you want to connect. If you specify the database file name that already presents on disk, it will connect to it. But if your specified SQLite database file does not exist, SQLite creates a new database for you.
You need to follow the following steps to connect to SQLite
- Use the method of a sqlite3 module and pass the database name as an argument.
- Create a cursor object using the connection object returned by the connect method to execute SQLite queries from Python.
- Close the Cursor object and SQLite database connection object when work is done.
- Catch database exception if any that may occur during this connection process.
The following Python program creates a new database file “SQLite_Python.db” and prints the SQLite version details.
You should get the following output after connecting to SQLite from Python.
Database created and Successfully Connected to SQLite SQLite Database Version is: The SQLite connection is closed
Understand the SQLite connection Code in detail
import sqlite3
This line imports the sqlite3 module in our program. Using the classes and methods defined in the sqlite3 module we can communicate with the SQLite database.
sqlite3.connect()
- Using the method we can create a connection to the SQLite database. This method returns the SQLite Connection Object.
- The connection object is not thread-safe. the sqlite3 module doesn’t allow sharing connections between threads. If you still try to do so, you will get an exception at runtime.
- The method accepts various arguments. In our example, we passed the database name argument to connect.
cursor = sqliteConnection.cursor()
- Using a connection object we can create a cursor object which allows us to execute SQLite command/queries through Python.
- We can create as many cursors as we want from a single connection object. Like connection object, this cursor object is also not thread-safe. the sqlite3 module doesn’t allow sharing cursors between threads. If you still try to do so, you will get an exception at runtime.
After this, we created a SQLite query to get the database version.
cursor.execute()
- Using the cursor’s execute method we can execute a database operation or query from Python. The method takes an SQLite query as a parameter and returns the resultSet i.e. nothing but a database rows.
- We can retrieve query result from resultSet using cursor methods such as
- In our example, we are executing a query to fetch the SQLite version.
try-except-finally block: We placed all our code in the try-except block to catch the SQLite database exceptions and errors that may occur during this process.
- Using the class of sqlite3 module, we can handle any database error and exception that may occur while working with SQLite from Python.
- Using this approach we can make our application robust. The class helps us to understand the error in detail. It returns an error message and error code.
cursor.close() and connection.close()
It is always good practice to close the cursor and connection object once your work gets completed to avoid database issues.
Column Types¶
SQLite has native support for integer, floating point, and text
columns. Data of these types is converted automatically by
from Python’s representation to a value that can be
stored in the database, and back again, as needed. Integer values are
loaded from the database into int or long variables,
depending on the size of the value. Text is saved and retrieved as
unicode, unless the Connection text_factory
has been changed.
Although SQLite only supports a few data types internally,
includes facilities for defining custom types to allow
a Python application to store any type of data in a column.
Conversion for types beyond those supported by default is enabled in
the database connection using the detect_types flag. Use
PARSE_DECLTYPES is the column was declared using the desired
type when the table was defined.
import sqlite3
import sys
db_filename = 'todo.db'
sql = "select id, details, deadline from task"
def show_deadline(conn):
conn.row_factory = sqlite3.Row
cursor = conn.cursor()
cursor.execute(sql)
row = cursor.fetchone()
for col in 'id', 'details', 'deadline']:
print ' column:', col
print ' value :', rowcol
print ' type :', type(rowcol])
return
print 'Without type detection:'
with sqlite3.connect(db_filename) as conn
show_deadline(conn)
print '\nWith type detection:'
with sqlite3.connect(db_filename, detect_types=sqlite3.PARSE_DECLTYPES) as conn
show_deadline(conn)
provides converters for date and timestamp columns,
using date and from the
module to represent the values in Python. Both date-related
converters are enabled automatically when type-detection is turned on.
$ python sqlite3_date_types.py
Without type detection:
column: id
value : 1
type : <type 'int'>
column: details
value : write about select
type : <type 'unicode'>
column: deadline
value : 2010-10-03
type : <type 'unicode'>
With type detection:
column: id
value : 1
type : <type 'int'>
column: details
value : write about select
type : <type 'unicode'>
column: deadline
value : 2010-10-03
type : <type 'datetime.date'>
Custom Types
Two functions need to be registered to define a new type. The
adapter takes the Python object as input and returns a byte string
that can be stored in the database. The converter receives the
string from the database and returns a Python object. Use
register_adapter() to define an adapter function, and
register_converter() for a converter function.
import sqlite3
try
import cPickle as pickle
except
import pickle
db_filename = 'todo.db'
def adapter_func(obj):
"""Convert from in-memory to storage representation.
"""
print 'adapter_func(%s)\n' % obj
return pickle.dumps(obj)
def converter_func(data):
"""Convert from storage to in-memory representation.
"""
print 'converter_func(%r)\n' % data
return pickle.loads(data)
class MyObj(object):
def __init__(self, arg):
self.arg = arg
def __str__(self):
return 'MyObj(%r)' % self.arg
# Register the functions for manipulating the type.
sqlite3.register_adapter(MyObj, adapter_func)
sqlite3.register_converter("MyObj", converter_func)
# Create some objects to save. Use a list of tuples so we can pass
# this sequence directly to executemany().
to_save = (MyObj('this is a value to save'),),
(MyObj(42),),
with sqlite3.connect(db_filename, detect_types=sqlite3.PARSE_DECLTYPES) as conn
# Create a table with column of type "MyObj"
conn.execute("""
create table if not exists obj (
id integer primary key autoincrement not null,
data MyObj
)
""")
cursor = conn.cursor()
# Insert the objects into the database
cursor.executemany("insert into obj (data) values (?)", to_save)
# Query the database for the objects just saved
cursor.execute("select id, data from obj")
for obj_id, obj in cursor.fetchall():
print 'Retrieved', obj_id, obj, type(obj)
print
This example uses to save an object to a string that can
be stored in the database. This technique is useful for storing
arbitrary objects, but does not allow querying based on object
attributes. A real object-relational mapper such as SQLAlchemy
that stores attribute values in their own columns will be more useful
for large amounts of data.
$ python sqlite3_custom_type.py
adapter_func(MyObj('this is a value to save'))
adapter_func(MyObj(42))
converter_func("ccopy_reg\n_reconstructor\np1\n(c__main__\nMyObj\np2\n
c__builtin__\nobject\np3\nNtRp4\n(dp5\nS'arg'\np6\nS'this is a value t
o save'\np7\nsb.")
converter_func("ccopy_reg\n_reconstructor\np1\n(c__main__\nMyObj\np2\n
c__builtin__\nobject\np3\nNtRp4\n(dp5\nS'arg'\np6\nI42\nsb.")
Retrieved 1 MyObj('this is a value to save') <class '__main__.MyObj'>
Retrieved 2 MyObj(42) <class '__main__.MyObj'>
有效使用 sqlite3¶
使用快捷方式
使用 对象的非标准 , 和 方法,可以更简洁地编写代码,因为不必显式创建(通常是多余的) 对象。相反, 对象是隐式创建的,这些快捷方法返回游标对象。这样,只需对 对象调用一次,就能直接执行 语句并遍历对象。
import sqlite3
persons =
("Hugo", "Boss"),
("Calvin", "Klein")
con = sqlite3.connect(":memory:")
# Create the table
con.execute("create table person(firstname, lastname)")
# Fill the table
con.executemany("insert into person(firstname, lastname) values (?, ?)", persons)
# Print the table contents
for row in con.execute("select firstname, lastname from person"):
print(row)
print("I just deleted", con.execute("delete from person").rowcount, "rows")
# close is not a shortcut method and it's not called automatically,
# so the connection object should be closed manually
con.close()
通过名称而不是索引访问索引
模块的一个有用功能是内置的 类,它被设计用作行对象的工厂。
该类的行装饰器可以用索引(如元组)和不区分大小写的名称访问:
import sqlite3
con = sqlite3.connect(":memory:")
con.row_factory = sqlite3.Row
cur = con.cursor()
cur.execute("select 'John' as name, 42 as age")
for row in cur
assert row == row"name"
assert row"name" == row"nAmE"
assert row1 == row"age"
assert row1 == row"AgE"
con.close()
SQLite3 Executemany (Bulk insert)
You can use the executemany statement to insert multiple rows at once.
Consider the following code:
import sqlite3
con = sqlite3.connect('mydatabase.db')
cursorObj = con.cursor()
cursorObj.execute('create table if not exists projects(id integer, name text)')
data =
cursorObj.executemany("INSERT INTO projects VALUES(?, ?)", data)
con.commit()
Here we created a table with two columns, and “data” has four values for each column. We pass the variable to the executemany() method along with the query.
Note that we have used the placeholder to pass the values.
The above code will generate the following result:

INSERT Operation
Following Python program shows how to create records in the COMPANY table created in the above example.
#!/usr/bin/python
import sqlite3
conn = sqlite3.connect('test.db')
print "Opened database successfully";
conn.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (1, 'Paul', 32, 'California', 20000.00 )");
conn.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (2, 'Allen', 25, 'Texas', 15000.00 )");
conn.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 )");
conn.execute("INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) \
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 )");
conn.commit()
print "Records created successfully";
conn.close()
When the above program is executed, it will create the given records in the COMPANY table and it will display the following two lines −
Opened database successfully Records created successfully
Exceptions¶
- exception
-
A subclass of .
- exception
-
The base class of the other exceptions in this module. It is a subclass
of .
- exception
-
Exception raised for errors that are related to the database.
- exception
-
Exception raised when the relational integrity of the database is affected,
e.g. a foreign key check fails. It is a subclass of .
- exception
-
Exception raised for programming errors, e.g. table not found or already
exists, syntax error in the SQL statement, wrong number of parameters
specified, etc. It is a subclass of .
- exception
-
Exception raised for errors that are related to the database’s operation
and not necessarily under the control of the programmer, e.g. an unexpected
disconnect occurs, the data source name is not found, a transaction could
not be processed, etc. It is a subclass of .






