Команда sort в linux
Содержание:
Sort() и sorted() в Python
В Python вы можете отсортировать список, используя встроенный метод list.sort() или встроенную функцию sorted().
Функция sorted() создает новый отсортированный список, в то время как метод list.sort() сортирует список на месте. Если вы хотите сохранить, несортированный список использовать функцию sorted(). Другое отличие состоит в том, что функция sorted() работает с любым повторяемым объектом.
Синтаксис sort()и sorted()следующий:
list.sort(key=function, reverse=Boolean)
sorted(iterable, key=function, reverse=Boolean)
Необязательные ключевые аргументы key и reverse имеют следующее значение:
- key – Функция, которая принимает один аргумент и преобразует его перед сравнением. Функция должна возвращать одно значение, которое используется для сравнения сортировки.
- reverse – Значение реверса может быть либо либо, True либо False. Значением по умолчанию является True. Когда для этого аргумента установлено значение false, список сортируется в обратном порядке.
Элементы списка сравниваются с помощью оператора < (меньше чем) и сортируются по возрастанию. Оператор < не поддерживает сравнения строки в целое число, так что если у вас есть список , содержащие строки и целые числа, то операция сортировки не удастся.
В следующем примере показано, как отсортировать список строк в алфавитном порядке:
directions =
directions.sort()
print('Sorted list:', directions)
Sorted list:
Если вы хотите сохранить исходный список без изменений, используйте функцию sorted():
directions =
sorted_directions = sorted(directions)
print('Sorted list:', sorted_directions)
Sorted list:
Чтобы отсортировать список в обратном (нисходящем) порядке, установите аргумент reverse в True:
directions =
directions.sort(reverse=True)
print('Sorted list:', directions)
Sorted list:
Возможность автоупорядочивания
Ключевое слово АВТОУПОРЯДОЧИВАНИЕ позволяет включить режим автоматического формирования полей для упорядочивания результатов запроса.
Мы сейчас познакомимся с этой возможностью подробно, но сразу хочется оговориться, что фирма «1С» в своих не советует использовать её без необходимости (о причинах этого мы поговорим ).
Итак, поехали.
Прежде всего, ключевое слово АВТОУПОРЯДОЧИВАНИЕ может быть расположено в запросе сразу за или вместо секции УПОРЯДОЧИТЬ ПО:
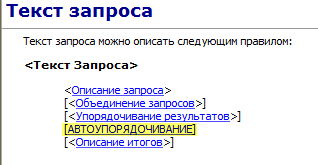
Автоупорядочивание работает по следующим принципам:
Случай #1
Если в запросе:
есть секция УПОРЯДОЧИТЬ ПО
Тогда ссылка на каждую таблицу в этой секции будут заменена полями, по которым по умолчанию сортируется эта таблица.
Для таблиц справочников полями сортировки по умолчанию являются код и наименование, выбор из которых осуществляется в соответствии с настройками справочника в конфигураторе:
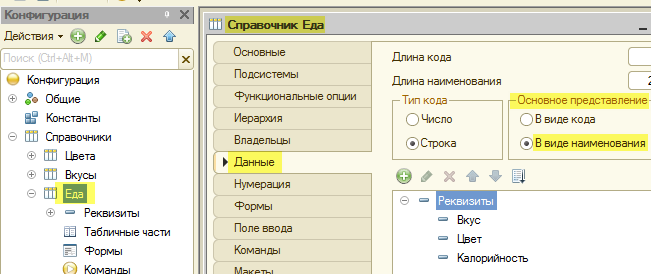
Для таблиц документов полем сортировки по умолчанию является дата документа.
Рассмотрим пример:
ВЫБРАТЬ
Наименование
ИЗ
Справочник.Клиенты
УПОРЯДОЧИТЬ ПО
ЛюбимыйЦвет
АВТОУПОРЯДОЧИВАНИЕ
|
Так как поле сортировки ЛюбимыйЦвет имеет тип Справочник.Цвета, в настройках которого основным представлением выбрано поле Наименование, то этот запрос эквивалентен:
ВЫБРАТЬ
Наименование
ИЗ
Справочник.Клиенты
УПОРЯДОЧИТЬ ПО
ЛюбимыйЦвет.Наименование
|
Случай #2
Если в запросе:
- отсутствует секция УПОРЯДОЧИТЬ ПО
- но есть секция ИТОГИ ПО (её мы будем проходить позже)
В этом случае результат запроса будет упорядочен по полям итогов (в той же последовательности).
Если среди этих полей есть ссылки на таблицы, то они также будут заменены полями, по которым сортируются эти таблицы по умолчанию.
Случай #3
Если в запросе:
- отсутствует секция УПОРЯДОЧИТЬ ПО
- отсутствует секция ИТОГИ ПО
- но есть секция СГРУППИРОВАТЬ ПО (группировку мы проходили здесь)
В этом случае результат запроса будет упорядочен по полям группировки (в той же последовательности).
Если среди этих полей есть ссылки на таблицы, то они также будут заменены полями, по которым сортируются эти таблицы по умолчанию.
Рассмотрим пример:
ВЫБРАТЬ
Город,
СУММА(Количество)
ИЗ
Документ.ПрибытиеГостей
СГРУППИРОВАТЬ ПО
Город
АВТОУПОРЯДОЧИВАНИЕ
|
Так как поле группировки Город имеет тип Справочник.Города, в настройках которого основным представлением выбрано поле Наименование, то этот запрос эквивалентен:
ВЫБРАТЬ
Город,
СУММА(Количество)
ИЗ
Документ.ПрибытиеГостей
СГРУППИРОВАТЬ ПО
Город
УПОРЯДОЧИТЬ ПО
Город.Наименование
|
Случай #4
Наконец, если в запросе:
- отсутствует секция УПОРЯДОЧИТЬ ПО
- отсутствует секция ИТОГИ ПО
- отсутствует секция СГРУППИРОВАТЬ ПО
В этом случае результат запроса будет упорядочен по полям сортировки по умолчанию для таблиц, из которых выбираются данные, в порядке их появления в запросе.
Рассмотрим пример:
ВЫБРАТЬ
Код,
Наименование
ИЗ
Справочник.Еда
АВТОУПОРЯДОЧИВАНИЕ
|
Так как данные выбираются из справочника Еда, в настройках которого основным представлением выбрано поле Наименование, то этот запрос будет эквивалентен:
ВЫБРАТЬ
Код,
Наименование
ИЗ
Справочник.Еда
УПОРЯДОЧИТЬ ПО
Наименование
|
Анализ[править]
В первом алгоритме первые два цикла работают за и , соответственно; двойной цикл за . Алгоритм имеет линейную временную трудоёмкость . Используемая дополнительная память равна .
Второй алгоритм состоит из двух проходов по массиву размера и одного прохода по массиву размера .
Его трудоемкость, таким образом, равна . На практике сортировку подсчетом имеет смысл применять, если , поэтому можно считать время работы алгоритма равным .
Как и в обычной сортировке подсчетом, требуется дополнительной памяти — на хранение массива размера и массива размера .
Алгоритм работает за линейное время, но является псевдополиномиальным.
Сортировка сложных объектов[править]
Сортировка целых чисел за линейное время это хорошо, но недостаточно. Иногда бывает очень желательно применить быстрый алгоритм для упорядочивания набора каких-либо «сложных» данных. Под «сложными объектами» здесь подразумеваются структуры, содержащие в себе несколько полей. Одно из них мы выделим и назовем ключом, сортировка будет идти именно по нему (предполагается, что значения, принимаемые ключом — целые числа в диапазоне от до ).
Мы не сможем использовать здесь в точности тот же алгоритм, что и для сортировки подсчетом обычных целых чисел, потому что в наборе могут быть различные структуры, имеющие одинаковые ключи. Существует два способа справиться с этой проблемой — использовать списки для хранения структур в отсортированном массиве или заранее посчитать количество структур с одинаковыми ключами для каждого значения ключа.
Описаниеправить
Исходная последовательность из структур хранится в массиве , а отсортированная — в массиве того же размера. Кроме того, используется вспомогательный массив с индексами от до .
Идея алгоритма состоит в предварительном подсчете количества элементов с различными ключами в исходном массиве и разделении результирующего массива на части соответствующей длины (будем называть их блоками). Затем при повторном проходе исходного массива каждый его элемент копируется в специально отведенный его ключу блок, в первую свободную ячейку. Это осуществляется с помощью массива индексов , в котором хранятся индексы начала блоков для различных ключей. — индекс в результирующем массиве, соответствующий первому элементу блока для ключа .
Пройдем по исходному массиву A и запишем в P количество структур, ключ которых равен i.
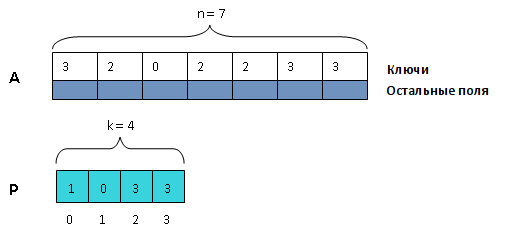
Мысленно разобьем массив B на k блоков, длина каждого из которых равна соответственно P, P, …, P.
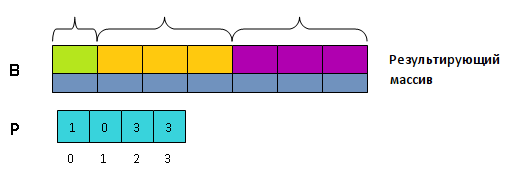
Теперь массив P нам больше не нужен. Превратим его в массив, хранящий в P сумму элементов от 0 до i-1 старого массива P.
Теперь «сдвинем» массив P на элемент вперед: в новом массиве P = 0, а для i \gt 0 P = P_{old}, где P_{old} — старый массив P. Это можно сделать за один проход по массиву P, причем одновременно с предыдущим шагом. После этого действия в массиве P будут хранится индексы массива B. P указывает на начало блока в B, соответствующего ключу key.
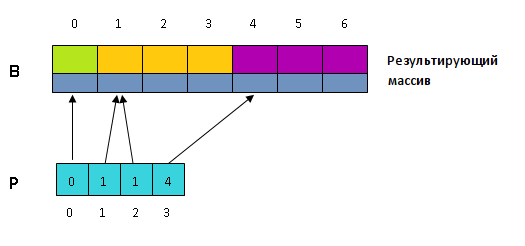
Произведем саму сортировку. Еще раз пройдем по исходному массиву A и для всех i \in будем помещать структуру A в массив B на место P.key], а затем увеличивать P.key] на 1. Здесь A.key — это ключ структуры, находящейся в массиве A на i-том месте.
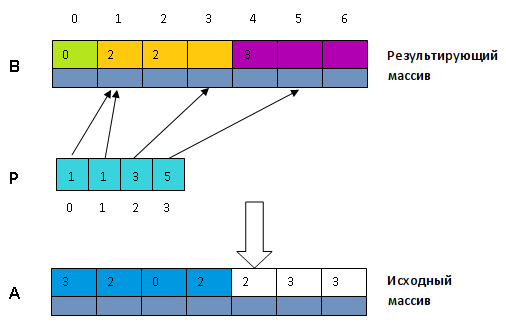
Таким образом после завершения алгоритма в будет содержаться исходная последовательность в отсортированном виде (так как блоки расположены по возрастанию соответствующих ключей).
Стоит также отметить, что эта сортировка является устойчивой, так как два элемента с одинаковыми ключами будут добавлены в том же порядке, в каком просматривались в исходном массиве . Благодаря этому свойству существует цифровая сортировка.
Псевдокодправить
Здесь и — массивы структур размера , с индексами от до .
— целочисленный массив размера , с индексами от до , где — количество различных ключей.
function complexCountingSort(A: int, B: int):
for i = 0 to k - 1
P = 0;
for i = 0 to length - 1
P.key] = P.key] + 1;
carry = 0;
for i = 0 to k - 1
temporary = P;
P = carry;
carry = carry + temporary;
for i = 0 to length - 1
B.key]] = A;
P.key] = P.key] + 1;
Здесь шаги 3 и 4 из описания объединены в один цикл.
Обратите внимание, что в последнем цикле инструкцией
B.key]] = A;
копируется структура целиком, а не только её ключ.
Сортировка
Последнее обновление: 31.10.2015
Для сортировки набора данных по возрастанию используется оператор orderby:
int[] numbers = { 3, 12, 4, 10, 34, 20, 55, -66, 77, 88, 4 };
var orderedNumbers = from i in numbers
orderby i
select i;
foreach (int i in orderedNumbers)
Console.WriteLine(i);
Оператор принимает критерий сортировки. В данном случае в качестве критерия выступает само число.
Возьмем посложнее пример. Допустим, надо отсортировать выборку сложных объектов. Тогда в качестве критерия мы можем указать свойство класса объекта:
List<User> users = new List<User>()
{
new User { Name = "Tom", Age = 33 },
new User { Name = "Bob", Age = 30 },
new User { Name = "Tom", Age = 21 },
new User { Name = "Sam", Age = 43 }
};
var sortedUsers = from u in users
orderby u.Name
select u;
foreach (User u in sortedUsers)
Console.WriteLine(u.Name);
По умолчанию оператор производит сортировку по возрастанию. Однако с помощью ключевых слов ascending (сортировка
по возрастанию) и descending (сортировка по убыванию) можно явным образом указать направление сортировки:
var sortedUsers = from u in users
orderby u.Name descending
select u;
Вместо оператора orderby можно использовать методы расширения OrderBy:
int[] numbers = { 3, 12, 4, 10, 34, 20, 55, -66, 77, 88, 4 };
IEnumerable<int> sortedNumbers = numbers.OrderBy(i=>i);
List<User> users = new List<User>()
{
new User { Name = "Tom", Age = 33 },
new User { Name = "Bob", Age = 30 },
new User { Name = "Tom", Age = 21 },
new User { Name = "Sam", Age = 43 }
};
var sortedUsers = users.OrderBy(u=>u.Name);
Метод сортирует по возрастанию. Для сортировки по убыванию используется метод :
var sortedUsers = users.OrderByDescending(u=>u.Name);
Множественные критерии сортировки
В наборах сложных объектов иногда встает ситуация, когда надо отсортировать не по одному, а сразу по нескольким полям. Для этого в запросе LINQ все критерии
указываются в порядке приоритета через запятую:
List<User> users = new List<User>()
{
new User { Name = "Tom", Age = 33 },
new User { Name = "Bob", Age = 30 },
new User { Name = "Tom", Age = 21 },
new User { Name = "Sam", Age = 43 }
};
var result = from user in users
orderby user.Name, user.Age
select user;
foreach (User u in result)
Console.WriteLine($"{u.Name} - {u.Age}");
Результат программы:
Alice - 28 Bob - 30 Sam - 43 Tom - 21 Tom - 33
С помощью методов расширения то же самое можно сделать через метод ThenBy()(для сортировки по возрастанию) и ThenByDescending() (для сортировки по убыванию):
var result = users.OrderBy(u => u.Name).ThenBy(u => u.Age);
Результат будет аналогичен предыдущему.
НазадВперед
Сортировка деревом
Сортировка деревом за счёт дополнительной памяти быстро решает вопрос с добавлением очередного элемента в отсортированную часть массива. Причём в роли отсортированной части массива выступает бинарное дерево. Дерево формируется буквально на лету при переборе элементов.
Элемент сравнивается сначала с корнем, а потом и с более вложенными узлами по принципу: если элемент меньше чем узел — то спускаемся по левой ветке, если не меньше — то по правой. Построенное по такому правилу дерево затем можно легко обойти так, чтобы двигаться от узлов с меньшими значениями к узлам с большими значениями (и таким образом получить все элементы в возрастающем порядке).
Основная загвоздка сортировок вставками (затраты на вставку элемента на своё место в отсортированной части массива) здесь решена, построение происходит вполне оперативно. Во всяком случае для освобождения точки вставки не нужно медленно передвигать караваны элементов как в предыдущих алгоритмах. Казалось бы, вот она, наилучшая из сортировок вставками. Но есть проблема.
Когда получается красивая симметричная ёлочка (так называемое идеально сбалансированное дерево) как в анимации тремя абзацами выше, то вставка происходит быстро, поскольку дерево в этом случае имеет минимально возможную вложенность уровней. Но сбалансированная (или хотя бы близкая к таковой) структура из рандомного массива получается редко. И дерево, скорее всего, будет неидеальное и несбалансированное — с перекосами, заваленным горизонтом и избыточным количеством уровней.
Рандомный массив со значениями от 1 до 10. Элементы в таком порядке генерируют несбалансированное двоичное дерево:
Дерево мало построить, его ещё нужно обойти. Чем больше несбалансированности — тем сильнее будет буксовать алгоритм по обходу дерева. Тут как скажут звёзды, рандомный массив может породить как уродливую корягу (что более вероятно) так и древовидный фрактал.
Значения элементов те же, но порядок другой. Генерируется сбалансированное двоичное дерево:На прекрасной сакуре Не хватает лепестка: Бинарное дерево из десятки.
Проблему несбалансированных деревьев решает сортировка выворачиванием, которая использует особую разновидность бинарного дерева поиска — splay tree. Это замечательное древо-трансформер, которое после каждой операции перестраивается в сбалансированное состояние. Про это будет отдельная статья. К тому времени подготовлю и реализации на Python как для Tree Sort, так и для Splay sort.
Ну чтож, мы кратенько прошлись по самым популярным сортировкам вставками. Простые вставки, Шелл и двоичное дерево мы все знаем ещё со школы. А теперь рассмотрим других представителей этого класса, не столь широко известных.
Вики / Wiki
—
Вставки / Insertion,Шелл / Shell,Дерево / Tree
Статьи серии:
Кто пользуется AlgoLab — рекомендую обновить файл. Я добавил в это приложение простые вставки с бинарным поиском и па́рные вставки. Также полностью переписал визуализацию для Шелла (в предыдущей версии там было не пойми что) и добавил подсветку родительской ветки при вставке элемента в бинарное дерево.
Сортировка данных по нескольким столбцам
Если нужно отсортировать информацию по разным условиям в разных столбцах, используется меню «Настраиваемый список». Там есть кнопка «Добавить уровень».
Данные в таблице будут отсортированы по нескольким параметрам. В одном столбце, например, по возрастанию. В другом («затем по…») – по алфавиту и т.д. В результате диапазон будет сформирован так, как задано сложной сортировкой.
Уровни можно добавлять, удалять, копировать, менять местами посредством кнопок «Вверх»-«Вниз».
Это самые простые способы сортировки данных в таблицах. Можно для этих целей применять формулы. Для этих целей подходят встроенные инструменты «НАИМЕНЬШИЙ», «СТРОКА», СЧЕТЕСЛИ».
Excel работает за вас
2 вариант
1. Какое понятие является синонимом понятия «систематизировать информацию»?
1) поиск
2) перевод текста на иностранный язык
3) группировать данные
4) накопление
2. Может ли компьютер упорядочить письма в электронной почте по фамилии отправителя?
1) да
2) нет
3. Можно ли сгруппировать письма в электронной почте по теме письма?
1) да
2) нет
4. Маша нашла свои фотографии. К какому виду обработки информации относится её действие?
1) поиск
2) систематизация
3) изменение формы представления
4) преобразование по заданным правилам
5. Маша рассчитала общую стоимость подарков для класса. К какому виду обработки информации относится действие Маши?
1) поиск
2) систематизация
3) изменение формы представления
4) преобразование по заданным правилам
6. Миша перевёл на немецкий язык слово «программа». К какому виду обработки информации относится действие Миши?
1) поиск
2) систематизация
3) изменение формы представления
4) преобразование по заданным правилам
7. Миша подготовил презентацию работы, используя рисунки и чертежи. К какому виду обработки информации относится действие Миши?
1) поиск
2) систематизация
3) изменение формы представления
4) преобразование по заданным правилам
8. На уроке геометрии решали задачу и нашли сторону треугольника по формуле с2 = а2 + b2. Было ли выполнено преобразование информации по заданным правилам?
1) да
2) нет
9. Зачем выполнять систематизацию информации?
1) для удобства восприятия информации
2) для удобства поиска информации
3) оба ответа верны
Ответы на тест по информатике Систематизация информации. Поиск информации. Изменение формы представления информации. Преобразование информации по заданным правилам для 5 класса1 вариант
1-4
2-1
3-2
4-2
5-1
6-4
7-3
8-1
9-12 вариант
1-3
2-1
3-1
4-1
5-4
6-3
7-3
8-1
9-3
Стабильность и сложность сортировки
Сортировка гарантировано стабильная. Когда несколько записей имеют одинаковый ключ их порядок всегда сохраняется.
>>> data =
>>> sorted(data, key=itemgetter(0))
|
1 |
>>>data=(‘red’,1),(‘blue’,1),(‘red’,2),(‘blue’,2) >>>sorted(data,key=itemgetter()) (‘blue’,1),(‘blue’,2),(‘red’,1),(‘red’,2) |
Заметьте что две записи с сохраняют исходный порядок, так что гарантировано впереди .
Стабильность сортировки позволяет выполнять сложную сортировку по шагам. Например, для сортировки учеников по классу в возрастающем порядке и затем по возрасту в убывающем порядке. Сначала сортируем по возрасту и затем по классу:
>>> s = sorted(student_objects, key=attrgetter(‘age’)) # сортировка по вторичному ключу
>>> sorted(s, key=attrgetter(‘grade’), reverse=True) # сортировка по первичному ключу
|
1 |
>>>s=sorted(student_objects,key=attrgetter(‘age’))# сортировка по вторичному ключу >>>sorted(s,key=attrgetter(‘grade’),reverse=True)# сортировка по первичному ключу (‘dave’,’B’,10),(‘jane’,’B’,12),(‘john’,’A’,15) |
Эту возможность можно абстрагировать и обернуть в функцию которая принимает список и кортежи из полей и порядка сортировки:
>>> def multisort(xs, specs):
… for key, reverse in reversed(specs):
… xs.sort(key=attrgetter(key), reverse=reverse)
… return xs
>>> multisort(list(student_objects), ((‘grade’, True), (‘age’, False)))
|
1 |
>>>def multisort(xs,specs) …forkey,reverse inreversed(specs) …xs.sort(key=attrgetter(key),reverse=reverse) …returnxs >>>multisort(list(student_objects),((‘grade’,True),(‘age’,False))) (‘dave’,’B’,10),(‘jane’,’B’,12),(‘john’,’A’,15) |
Алгоритм Timsort, используемый в Python, эффективно производит множественные сортировки, так как использует существующий порядок в данных.
Классификация сортировок[править]
Время работыправить
Эту классификацию обычно считают самой важной. Оценивают худшее время алгоритма, среднее и лучшее
Лучшее время — минимальное время работы алгоритма на каком-либо наборе, обычно этим набором является тривиальный $\big $. Худшее время — наибольшее время.
У большинства алгоритмов временные оценки бывают $O(n \log n)$ и $O(n^2)$.
Памятьправить
Параметр сортировки, показывающий, сколько дополнительной памяти требуется алгоритму. Сюда входят и дополнительный массив, и переменные, и затраты на стек вызовов. Обычно затраты бывают $O(1)$, $O(\log n)$, $O(n)$.
Устойчивостьправить
Устойчивой сортировкой называется сортировка, не меняющая порядка объектов с одинаковыми ключами. Ключ — поле элемента, по которому мы производим сортировку.
Количество обменовправить
Количество обменов может быть важным параметром в случае, если объекты имеют большой размер. В таком случае при большом количестве обменов время алгоритма заметно увеличивается.
Детерминированностьправить
Алгоритм сортировки называется детерминированным, если каждая операция присваивания, обмена и т.д. не зависит от предыдущих.
Все сортирующие сети являются детерминированными.
Быстрая сортировка
Этот алгоритм также относится к алгоритмам «разделяй и властвуй». Его используют чаще других алгоритмов, описанных в этой статье. При правильной конфигурации он чрезвычайно эффективен и не требует дополнительной памяти, в отличие от сортировки слиянием. Массив разделяется на две части по разные стороны от опорного элемента. В процессе сортировки элементы меньше опорного помещаются перед ним, а равные или большие —позади.
Алгоритм
Быстрая сортировка начинается с разбиения списка и выбора одного из элементов в качестве опорного. А всё остальное передвигаем так, чтобы этот элемент встал на своё место. Все элементы меньше него перемещаются влево, а равные и большие элементы перемещаются вправо.
Реализация
Существует много вариаций данного метода. Способ разбиения массива, рассмотренный здесь, соответствует схеме Хоара (создателя данного алгоритма).
Время выполнения
В среднем время выполнения быстрой сортировки составляет O(n log n).
Обратите внимание, что алгоритм быстрой сортировки будет работать медленно, если опорный элемент равен наименьшему или наибольшему элементам списка. При таких условиях, в отличие от сортировок кучей и слиянием, обе из которых имеют в худшем случае время сортировки O(n log n), быстрая сортировка в худшем случае будет выполняться O(n²)






