Как: количество счетчиков только с помощью google таблиц функция count — 2020
Содержание:
Синтаксис
Синтаксис функции COUNT в MariaDB:
SELECT COUNT(aggregate_expression) FROM tables ;
Или синтаксис для функции COUNT при группировке результатов по одному или нескольким столбцам:
SELECT expression1, expression2, .. expression_n, COUNT(aggregate_expression) FROM tables GROUP BY expression1, expression2, .. expression_n;
Параметры или аргументы
- expression1, expression2, .. expression_n
- Выражения, которые не заключены в функцию COUNT и должны быть включены в предложение GROUP BY в конце SQL запроса.
- aggregate_expression
- Это столбец или выражение, чьи ненулевые значения будут учитываться.
- tables
- Таблицы, из которых вы хотите получить записи. В предложении FROM должна быть указана хотя бы одна таблица.
- WHERE conditions
- Необязательный. Это условия, которые должны быть соблюдены для выбора записей.
Предложение HAVING
В предложении HAVING определяется условие, которое применяется к группе строк. Таким образом, это предложение имеет такой же смысл для групп строк, что и предложение WHERE для содержимого соответствующей таблицы. Синтаксис предложения HAVING следующий:
Здесь параметр condition представляет условие и содержит агрегатные функции или константы.
Использование предложения HAVING совместно с агрегатной функцией COUNT(*) показано в примере ниже:
В этом примере посредством предложения GROUP BY система группирует все строки по значениям столбца ProjectNumber. После этого подсчитывается количество строк в каждой группе и выбираются группы, содержащие менее четырех строк (три или меньше).
Предложение HAVING можно также использовать без агрегатных функций, как это показано в примере ниже:
В этом примере происходит группирование строк таблицы Works_on по должности и устранение тех должностей, которые не начинаются с буквы «К».
Предложение HAVING можно также использовать без предложения GROUP BY, хотя это не является распространенной практикой. В таком случае все строки таблицы возвращаются в одной группе.
Example — Using GROUP BY with the COUNT Function
In some cases, you will be required to use the GROUP BY clause with the COUNT function. This happens when you have columns listed in the SELECT statement that are not part of the COUNT function. Let’s explore this further.
Again, using the employees table populated with the following data:
| employee_number | last_name | first_name | salary | dept_id |
|---|---|---|---|---|
| 1001 | Smith | John | 62000 | 500 |
| 1002 | Anderson | Jane | 57500 | 500 |
| 1003 | Everest | Brad | 71000 | 501 |
| 1004 | Horvath | Jack | 42000 | 501 |
Enter the following SQL statement:
Try It
SELECT dept_id, COUNT(*) AS total FROM employees WHERE salary > 50000 GROUP BY dept_id;
There will be 2 records selected. These are the results that you should see:
| dept_id | total |
|---|---|
| 500 | 2 |
| 501 | 1 |
Пример — выбор отдельных полей из нескольких табли
Вы также можете использовать SQL оператор SELECT для извлечения полей из нескольких таблиц. В этом примере у нас есть таблица orders со следующими данными:
| order_id | customer_id | order_date |
|---|---|---|
| 1 | 7000 | 2019/06/18 |
| 2 | 5000 | 2019/06/18 |
| 3 | 8000 | 2019/06/19 |
| 4 | 4000 | 2019/06/20 |
| 5 | NULL | 2019/07/01 |
И таблица с именем customers со следующими данными:
| customer_id | first_name | last_name | favorite_website |
|---|---|---|---|
| 4000 | Justin | Bieber | google.com |
| 5000 | Selena | Gomez | bing.com |
| 6000 | Mila | Kunis | yahoo.com |
| 7000 | Tom | Cruise | oracle.com |
| 8000 | Johnny | Depp | NULL |
| 9000 | Russell | Crowe | google.com |
Теперь давайте выберем столбцы из таблиц orders и customer. Введите следующий запрос SELECT.
PgSQL
SELECT orders.order_id,
customers.last_name
FROM orders
INNER JOIN customers
ON orders.customer_id = customers.customer_id
WHERE orders.order_id <> 1
ORDER BY orders.order_id;
|
1 2 3 4 5 6 7 |
SELECTorders.order_id, customers.last_name FROMorders INNER JOINcustomers ONorders.customer_id=customers.customer_id WHEREorders.order_id<>1 ORDERBYorders.order_id; |
Будет выбрано 3 записи. Вот результаты, которые вы должны получить.
| order_id | last_name |
|---|---|
| 2 | Gomez |
| 3 | Depp |
| 4 | Bieber |
Этот пример SELECT объединяет две таблицы, чтобы дать нам набор результатов, который отображает order_id из таблицы orders и last_name из таблицы customers. Каждый раз, когда мы используем столбец в операторе SELECT, мы добавляем к столбцу имя таблицы (например, orders.order_id) в случае, если есть какая-то двусмысленность относительно того, какой столбец к какой таблице принадлежит.
Если вы хотите выбрать все поля из таблицы orders, а затем поле last_name из таблицы клиентов, Введите следующий запрос SELECT.
PgSQL
SELECT orders.*,
customers.last_name
FROM orders
INNER JOIN customers
ON orders.customer_id = customers.customer_id
WHERE orders.order_id <> 1
ORDER BY orders.order_id;
|
1 2 3 4 5 6 7 |
SELECTorders.*, customers.last_name FROMorders INNER JOINcustomers ONorders.customer_id=customers.customer_id WHEREorders.order_id<>1 ORDERBYorders.order_id; |
Будет выбрано 3 записи. Вот результаты, которые вы должны получить.
| order_id | customer_id | order_date | last_name |
|---|---|---|---|
| 2 | 5000 | 2019/06/18 | Gomez |
| 3 | 8000 | 2019/06/19 | Depp |
| 4 | 4000 | 2019/06/20 | Bieber |
В этом примере мы используем orders.*, чтобы показать, что мы хотим выбрать все поля из таблицы orders, а затем мы выбираем поле last_name из таблицы customers.
Использование Bulk (множественного) SQL в динамическом SQL
SQL Bulk связывает целые коллекции, а не только отдельные элементы. Этот метод повышает производительность за счет минимизации количества переключений контекста между механизмами PL/SQL и SQL. Вы можете использовать один оператор вместо цикла, который выдает оператор SQL на каждой итерации.
Используя следующие команды, предложения и атрибут курсора, ваши приложения могут создавать объемные операторы SQL, а затем выполнять их динамически во время выполнения:
- BULK FETCH предложение
- BULK EXECUTE IMMEDIATE предложение
- FORALL предложение
- COLLECT INTO выражение
- RETURNING INTO выражение
- %BULK_ROWCOUNT атрибут курсора
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
GROUP BY – группировка данных
| DepartmentID | PositionCount | EmplCount | SalaryAmount | SalaryAvg |
|---|---|---|---|---|
| NULL | 1 | 2000 | 2000 | |
| 1 | 1 | 1 | 5000 | 5000 |
| 2 | 1 | 1 | 2500 | 2500 |
| 3 | 2 | 3 | 5000 | 1666.66666666667 |
| DepartmentID | PositionID | EmplCount | SalaryAmount |
|---|---|---|---|
| NULL | NULL | 1 | 2000 |
| 2 | 1 | 1 | 2500 |
| 1 | 2 | 1 | 5000 |
| 3 | 3 | 2 | 3000 |
| 3 | 4 | 1 | 2000 |
Давайте, теперь на этом примере, попробуем разобраться как работает GROUP BY
| DepartmentID | PositionID |
|---|---|
| NULL | NULL |
| 1 | 2 |
| 2 | 1 |
| 3 | 3 |
| 3 | 4 |
- Мы можем использовать только колонки, перечисленные в блоке GROUP BY
- Можно использовать выражения с полями из блока GROUP BY
- Можно использовать константы, т.к. они не влияют на результат группировки
- Все остальные поля (не перечисленные в блоке GROUP BY) можно использовать только с агрегатными функциями (COUNT, SUM, MIN, MAX, …)
- Не обязательно перечислять все колонки из блока GROUP BY в списке колонок SELECT
| Const1 | Const2 | ConstAndGroupField | ConstAndGroupFields | DepartmentID | EmplCount | SalaryAmount | MinID |
|---|---|---|---|---|---|---|---|
| Строка константа | 1 | Отдел № | Отдел №, Должность № | NULL | 1 | 2000 | 1005 |
| Строка константа | 1 | Отдел № 2 | Отдел № 2, Должность № 1 | 2 | 1 | 2500 | 1002 |
| Строка константа | 1 | Отдел № 1 | Отдел № 1, Должность № 2 | 1 | 1 | 5000 | 1000 |
| Строка константа | 1 | Отдел № 3 | Отдел № 3, Должность № 3 | 3 | 2 | 3000 | 1001 |
| Строка константа | 1 | Отдел № 3 | Отдел № 3, Должность № 4 | 3 | 1 | 2000 | 1003 |
| RangeName | EmplCount |
|---|---|
| 1979-1970 | 1 |
| 1989-1980 | 2 |
| не указано | 2 |
| ранее 1970 | 1 |
| Info | PositionCount | EmplCount | SalaryAmount | SalaryAvg |
|---|---|---|---|---|
| Администрация | 1 | 1 | 5000 | 5000 |
| Бухгалтерия | 1 | 1 | 2500 | 2500 |
| ИТ | 2 | 3 | 5000 | 1666.66666666667 |
| Прочие | 1 | 2000 | 2000 |
| DepartmentID | Бухгалтера | Директора | Программисты | Старшие программисты | Итого по отделу |
|---|---|---|---|---|---|
| NULL | NULL | NULL | NULL | NULL | 2000 |
| 1 | NULL | 5000 | NULL | NULL | 5000 |
| 2 | 2500 | NULL | NULL | NULL | 2500 |
| 3 | NULL | NULL | 3000 | 2000 | 5000 |
| DepartmentID | Бухгалтера | Директора | Программисты | Старшие программисты | Итого по отделу |
|---|---|---|---|---|---|
| 1 | NULL | 5000 | NULL | NULL | 5000 |
| 3 | NULL | NULL | 1500 | NULL | 1500 |
| 2 | 2500 | NULL | NULL | NULL | 2500 |
| 3 | NULL | NULL | NULL | 2000 | 2000 |
| 3 | NULL | NULL | 1500 | NULL | 1500 |
| NULL | NULL | NULL | NULL | NULL | 2000 |
| DepartmentID | Бухгалтера | Директора | Программисты | Старшие программисты | Итого по отделу |
|---|---|---|---|---|---|
| NULL | 2000 | ||||
| 1 | 5000 | 5000 | |||
| 2 | 2500 | 2500 | |||
| 3 | 3000 | 2000 | 5000 |
- вывести названия департаментов вместо их идентификаторов, например, добавив выражение CASE обрабатывающее DepartmentID в блоке SELECT
- добавьте сортировку по имени отдела при помощи ORDER BY
Introduction to SQL COUNT function
The SQL COUNT function is an aggregate function that returns the number of rows returned by a query. You can use the COUNT function in the SELECT statement to get the number of employees, the number of employees in each department, the number of employees who hold a specific job, etc.
The following illustrates the syntax of the SQL COUNT function:
The result of the COUNT function depends on the argument that you pass to it.
- By default, the COUNT function uses the ALL keyword whether you specify it or not. The ALL keyword means that all items in the group are considered including the duplicate values. For example, if you have a group (1, 2, 3, 3, 4, 4) and apply the COUNT function, the result is 6.
- If you specify the DISTINCT keyword explicitly, only unique non-null values are considered. The COUNT function returns 4 if you apply it to the group (1,2,3,3,4,4).
Another form of the COUNT function that accepts an asterisk (*) as the argument is as follows:
The COUNT(*) function returns the number of rows in a table including the rows that contain the NULL values.
Использование динамического SQL с Bulk SQL
Массовое (множественное) связывание позволяет Oracle связать переменную в операторе SQL с коллекцией значений. Тип коллекции может быть любым типом коллекции Oracle/PLSQL (index-by table, nested table или varray). Элементы коллекции должны иметь тип данных SQL, такой как CHAR, DATE или NUMBER. Три оператора поддерживают динамическое массовое связывание: EXECUTE IMMEDIATE, FETCH и FORALL.
EXECUTE IMMEDIATE
- Вы можете использовать предложение BULK COLLECT INTO с оператором EXECUTE IMMEDIATE, чтобы хранить значения из каждого столбца набора результатов запроса в отдельной коллекции.
- Вы можете использовать предложение RETURNING BULK COLLECT INTO с оператором EXECUTE IMMEDIATE, чтобы сохранить результаты оператора INSERT, UPDATE или DELETE в наборе коллекций.
FETCH
Вы можете использовать предложение BULK COLLECT INTO с оператором FETCH для хранения значений из каждого столбца курсора в отдельной коллекции.
FORALL
- Вы можете совместить EXECUTE IMMEDIATE инструкцию с RETURNING BULK COLLECT INTO внутри инструкции FORALL. Вы можете хранить результаты всех операторов INSERT, UPDATE или DELETE в наборе коллекций.
- Вы можете передать индексированные элементы коллекции в инструкцию EXECUTE IMMEDIATE через предложение USING.
- Вы не можете объединить индексированные элементы непосредственно в строковый аргумент для EXECUTE IMMEDIATE; например, вы не можете создать коллекцию имен таблиц и написать оператор FORALL, где каждая итерация применяется к другой таблице.
Примеры динамический SQL с предложением BULK COLLECT INTO
Вы можете связать определенные переменные в динамическом запросе, используя предложение BULK COLLECT INTO. Как показано в следующем примере, вы можете использовать это предложение в массовом выражении FETCH или в массовом выражении EXECUTE IMMEDIATE:
Oracle PL/SQL
DECLARE
TYPE EmpCurTyp IS REF CURSOR;
TYPE NumList IS TABLE OF NUMBER;
TYPE NameList IS TABLE OF VARCHAR2(15);
emp_cv EmpCurTyp;
empnos NumList;
enames NameList;
sals NumList;
BEGIN
OPEN emp_cv FOR ‘SELECT empno, ename FROM emp’;
FETCH emp_cv BULK COLLECT INTO empnos, enames;
CLOSE emp_cv;
EXECUTE IMMEDIATE ‘SELECT sal FROM emp’
BULK COLLECT INTO sals;
END;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
DECLARE TYPEEmpCurTypISREFCURSOR; TYPENumListISTABLEOFNUMBER; TYPENameListISTABLEOFVARCHAR2(15); emp_cvEmpCurTyp; empnosNumList; enamesNameList; salsNumList; OPENemp_cvFOR’SELECT empno, ename FROM emp’; FETCHemp_cvBULKCOLLECTINTOempnos,enames; CLOSEemp_cv; EXECUTEIMMEDIATE’SELECT sal FROM emp’ BULKCOLLECTINTOsals; END; |
Пример динамический SQL с предложением RETURNING BULK COLLECT INTO
Только операторы INSERT, UPDATE и DELETE могут иметь выходные переменные связывания. Вы массово связываете их в EXECUTE IMMEDIATE с предложением RETURNING BULK COLLECT INTO. Например:
Oracle PL/SQL
DECLARE
TYPE NameList IS TABLE OF VARCHAR2(15);
enames NameList;
bonus_amt NUMBER := 500;
sql_stmt VARCHAR(200);
BEGIN
sql_stmt := ‘UPDATE emp SET bonus = :1 RETURNING ename INTO :2’;
EXECUTE IMMEDIATE sql_stmt
USING bonus_amt RETURNING BULK COLLECT INTO enames;
END;
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE TYPENameListISTABLEOFVARCHAR2(15); enamesNameList; bonus_amtNUMBER:=500; sql_stmtVARCHAR(200); sql_stmt:=’UPDATE emp SET bonus = :1 RETURNING ename INTO :2′; EXECUTEIMMEDIATEsql_stmt USINGbonus_amtRETURNINGBULKCOLLECTINTOenames; END; |
Пример динамический SQL внутри оператора FORALL
Чтобы связать входные переменные в операторе SQL, вы можете использовать оператор FORALL и предложение USING, как показано ниже. Оператор SQL не может быть запросом. Например:
Oracle PL/SQL
DECLARE
TYPE NumList IS TABLE OF NUMBER;
TYPE NameList IS TABLE OF VARCHAR2(15);
empnos NumList;
enames NameList;
BEGIN
empnos := NumList(1,2,3,4,5);
FORALL i IN 1..5
EXECUTE IMMEDIATE
‘UPDATE emp SET sal = sal * 1.1 WHERE empno = :1
RETURNING ename INTO :2’
USING empnos(i) RETURNING BULK COLLECT INTO enames;
…
END;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DECLARE TYPENumListISTABLEOFNUMBER; TYPENameListISTABLEOFVARCHAR2(15); empnosNumList; enamesNameList; empnos:=NumList(1,2,3,4,5); FORALLiIN1..5 EXECUTEIMMEDIATE ‘UPDATE emp SET sal = sal * 1.1 WHERE empno = :1 RETURNING ename INTO :2′ USINGempnos(i)RETURNINGBULKCOLLECTINTOenames; … END; |
Примеры:
Некоторые примеры динамического SQL
Oracle PL/SQL
DECLARE
sql_stmt VARCHAR2(200);
plsql_block VARCHAR2(500);
emp_id NUMBER(4) := 7566;
salary NUMBER(7,2);
dept_id NUMBER(2) := 50;
dept_name VARCHAR2(14) := ‘PERSONNEL’;
location VARCHAR2(13) := ‘DALLAS’;
emp_rec emp%ROWTYPE;
BEGIN
—EXECUTE IMMEDIATE c SQL предложением
EXECUTE IMMEDIATE ‘CREATE TABLE bonus (id NUMBER, amt NUMBER)’;
—присвоим sql_stmt строковое SQL предложение с заполнителями :1, :2, :3
sql_stmt := ‘INSERT INTO dept VALUES (:1, :2, :3)’;
—запустим EXECUTE IMMEDIATE с sql_stmt используя аргументы связывания dept_id, dept_name, location
EXECUTE IMMEDIATE sql_stmt USING dept_id, dept_name, location;
—присвоим sql_stmt SQL предложение с заполнителем :id
sql_stmt := ‘SELECT * FROM emp WHERE empno = :id’;
—запустим EXECUTE IMMEDIATE с sql_stmt используя аргумент связывания emp_id и сохраним результат в emp_rec
EXECUTE IMMEDIATE sql_stmt INTO emp_rec USING emp_id;
—присвоим plsql_block запуск анонимного блока с подпрограммой raise_salary пакета emp_pkg с заполнителями :id, :amt
plsql_block := ‘BEGIN emp_pkg.raise_salary(:id, :amt); END;’;
—запустим EXECUTE IMMEDIATE с plsql_block используя аргументы связывания :id, :amt
EXECUTE IMMEDIATE plsql_block USING 7788, 500;
—присвоим sql_stmt SQL предложение с заполнителем :1, :2
sql_stmt := ‘UPDATE emp SET sal = 2000 WHERE empno = :1 RETURNING sal INTO :2’;
—запустим EXECUTE IMMEDIATE с sql_stmt используя аргументы связывания emp_id, salary
EXECUTE IMMEDIATE sql_stmt USING emp_id RETURNING INTO salary;
—EXECUTE IMMEDIATE c SQL предложение с заполнителем :num и аргументом связывания dept_id
EXECUTE IMMEDIATE ‘DELETE FROM dept WHERE deptno = :num’ USING dept_id;
—EXECUTE IMMEDIATE c SQL предложением
EXECUTE IMMEDIATE ‘ALTER SESSION SET SQL_TRACE TRUE’;
END;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
DECLARE sql_stmtVARCHAR2(200); plsql_blockVARCHAR2(500); emp_idNUMBER(4):=7566; salaryNUMBER(7,2); dept_idNUMBER(2):=50; dept_nameVARCHAR2(14):=’PERSONNEL’; locationVARCHAR2(13):=’DALLAS’; emp_recemp%ROWTYPE; EXECUTEIMMEDIATE’CREATE TABLE bonus (id NUMBER, amt NUMBER)’; sql_stmt:=’INSERT INTO dept VALUES (:1, :2, :3)’; EXECUTEIMMEDIATEsql_stmtUSINGdept_id,dept_name,location; sql_stmt:=’SELECT * FROM emp WHERE empno = :id’; EXECUTEIMMEDIATEsql_stmtINTOemp_recUSINGemp_id; plsql_block:=’BEGIN emp_pkg.raise_salary(:id, :amt); END;’; EXECUTEIMMEDIATEplsql_blockUSING7788,500; sql_stmt:=’UPDATE emp SET sal = 2000 WHERE empno = :1 RETURNING sal INTO :2′; EXECUTEIMMEDIATEsql_stmtUSINGemp_idRETURNINGINTOsalary; EXECUTEIMMEDIATE’DELETE FROM dept WHERE deptno = :num’USINGdept_id; EXECUTEIMMEDIATE’ALTER SESSION SET SQL_TRACE TRUE’; END; |
Пример процедуры динамического SQL, которая принимает имя таблицы и предложение WHERE
В этом примере автономная процедура принимает имя таблицы базы данных и необязательное условие предложения WHERE. Если вы пропустите условие, процедура удалит все строки из таблицы. В противном случае процедура удаляет только те строки, которые соответствуют условию.
Oracle PL/SQL
CREATE OR REPLACE PROCEDURE delete_rows (
table_name IN VARCHAR2,
condition IN VARCHAR2 DEFAULT NULL) AS
where_clause VARCHAR2(100) := ‘ WHERE ‘ || condition;
BEGIN
IF condition IS NULL THEN where_clause := NULL; END IF;
EXECUTE IMMEDIATE ‘DELETE FROM ‘ || table_name || where_clause;
END;
|
1 2 3 4 5 6 7 8 |
CREATEORREPLACEPROCEDUREdelete_rows( table_nameINVARCHAR2, conditionINVARCHAR2DEFAULTNULL)AS
where_clauseVARCHAR2(100):=’ WHERE ‘||condition; IFconditionISNULLTHENwhere_clause:=NULL;ENDIF; EXECUTEIMMEDIATE’DELETE FROM ‘||table_name||where_clause; END; |
Пример — использование GROUP BY
Наконец, давайте посмотрим, как использовать оператор GROUP BY с функцией COUNT в MariaDB. Если вы возвращаете столбцы, которые не инкапсулированы в функции COUNT, вы должны использовать предложение GROUP BY. Например:
PgSQL
SELECT site_id, COUNT(*) AS «Number of pages per site»
FROM pages
WHERE site_name in (‘Google.com’, ‘Yandex.com’)
GROUP BY site_id;
|
1 2 3 4 |
SELECTsite_id,COUNT(*)AS»Number of pages per site» FROMpages WHEREsite_namein(‘Google.com’,’Yandex.com’) GROUP BYsite_id; |
В этом примере функции COUNT мы должны использовать предложение GROUP BY, поскольку поле site_id не инкапсулировано в функцию COUNT. Поэтому столбец site_id должен быть указан в разделе GROUP BY в конце SQL запроса.
TIP: Performance Tuning with the COUNT Function
Since the COUNT function will return the same results regardless of what NOT NULL field(s) you include as the COUNT function parameters (ie: within the parentheses), you can use to get better performance. Now the database engine will not have to fetch any data fields, instead it will just retrieve the integer value of 1.
For example, instead of entering this statement:
Try It
SELECT dept_id, COUNT(*) AS total FROM employees WHERE salary > 50000 GROUP BY dept_id;
You could replace with to get better performance:
Try It
SELECT dept_id, COUNT(1) AS total FROM employees WHERE salary > 50000 GROUP BY dept_id;
Групповые операции в запросах Access
Сегодня поговорим на тему «Групповые операции в запросах Access». Групповые операции в запросах Access позволяют выделить группы записей с одинаковыми значениями в указанных полях и вычислить итоговые данные для каждой из групп по другим полям, используя одну из статистических функций. Статистические функции применимы, прежде всего, к полям с типом данных Числовой, Денежный, Дата/время. В Access предусматривается девять статистических функций:
- Sum — сумма значений некоторого поля для группы;
- Avg — среднее от всех значений поля в группе;
- Max, Min — максимальное, минимальное значение поля в группе;
- Count — число значений поля в группе без учета пустых значений;
- StDev — среднеквадратичное отклонение от среднего значения поля в группе;
- Var — дисперсия значений поля в группе;
- First и Last — значение поля из первой или последней записи в группе.
Результат запроса с использованием групповых операций содержит по одной записи для каждой группы. В запрос, прежде всего, включаются поля, по которым производится группировка, и поля, для которых выполняются статистические функции. Кроме этих полей в запрос могут включаться поля, по которым задаются условия отбора. Рассмотрим конструирование однотабличного запроса с групповой операцией на примере таблицы ПОСТАВКА_ПЛАН.
Запрос с функцией Sum
Задача. Определите, какое суммарное количество каждого из товаров должно быть поставлено покупателям по договорам. Все данные о запланированном к по-ставке количестве товара указаны в таблице ПОСТАВКА_ПЛАН.
- Создайте в режиме конструктора запрос на выборку из таблицы ПОСТАВКА_ПЛАН.
- Из списка таблицы перетащите в бланк запроса поле КОД_ТОВ ― код товара. По этому полю будет производиться группировка записей таблицы.
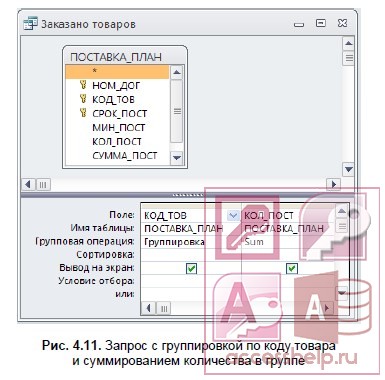
- Перетащите в бланк запроса поле КОЛ_ПОСТ, по которому будет подсчитываться суммарное количество каждого из товаров, заказанных во всех договорах.
- Выполните команду Итоги (Totals) из группы Показать или скрыть (Show/Hide). В бланке запроса появится новая строка Групповая операция (Total) со значением Группировка (Group By) в обоих полях запроса.
- В столбце КОЛ_ПОСТ замените слово Группировка (Group By) на функцию Sum. Для этого вызовите список и выберите эту функцию. Бланк запроса примет вид, показанный на рис. 4.11.
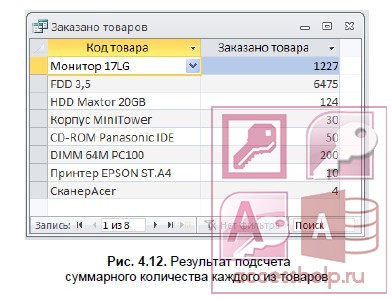
- Для отображения результата запроса (рис. 4.12) щелкните на кнопке Выполнить (Run) в группе Результаты (Results).
- Замените подпись поля Sum-КОЛ_ПОСТ на Заказано товаров. Для этого перейдите в режим конструктора, в бланке запроса установите курсор мыши на поле КОЛ_ПОСТ и нажмите правую кнопку. В контекстном меню выберите Свойства (Properties). В окне Свойства поля (Field Properties) введите в строке Подпись (Caption) — Заказано товаров. Для открытия окна свойств может быть выполнена команда Страница свойств (Property Sheet) в группе Показать или скрыть (Show/Hide).
- Сохраните запрос под именем Заказано товаров.
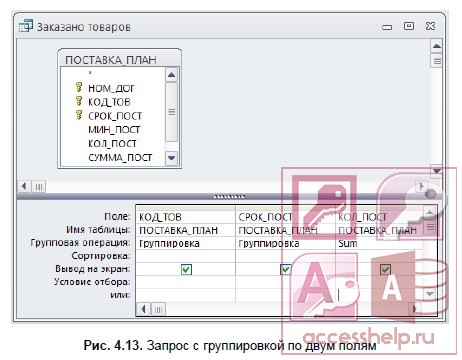
- Чтобы подсчитать количество товаров, заказанных в каждом месяце, выполните группировку по двум полям: КОД_ТОВ и СРОК_ПОСТ, в котором хранится месяц поставки (рис. 4.13).
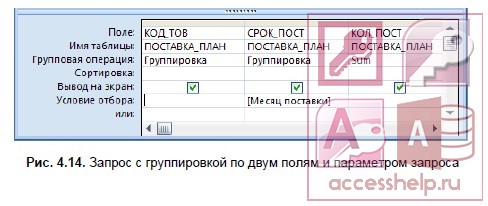
- Чтобы подсчитать количество товаров, заказанных в заданном месяце, предыдущий запрос дополните вводом параметра запроса в условие отбора (рис. 4.14).
Запрос с функцией Count
Задача. Определите, сколько раз отгружался товар по каждому из договоров. Факт отгрузки фиксируется в таблице НАКЛАДНАЯ.
Создайте запрос на выборку на основе таблицы НАКЛАДНАЯ.
Из списка полей таблицы НАКЛАДНАЯ перетащите в бланк запроса поле НОМ_ДОГ
По этому полю должна производиться группировка.
По сути, смысл задачи сводится к подсчету в таблице числа строк с одинаковым номером договора, поэтому неважно по какому полю будет вычисляться функция Count. Перетащите в бланк запроса любое поле, например опять НОМ_ДОГ.
Выполните команду Итоги (Totals) из группы Показать или скрыть (Show/Hide)
Замените слово Группировка (Group By) в одном из столбцов с именем НОМ_ДОГ на функцию Count. Бланк запроса примет вид, показанный на рис. 4.15.
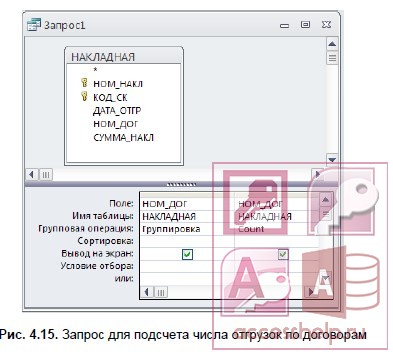
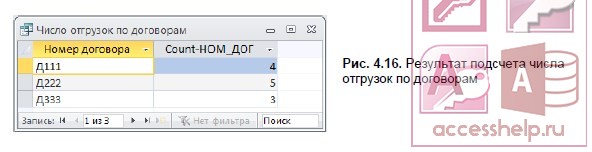
- Сохраните запрос под именем Число отгрузок по договорам. Выполните запрос. Результат запроса показан на рис. 4.16.
 Для закрепления смотрим видеоурок:
Для закрепления смотрим видеоурок:
Построение динамического запроса с помощью динамического SQL
Для обработки динамического многострочного запроса вы используете три оператора: OPEN-FOR, FETCH и CLOSE. Сначала вы открываете переменную курсора для многострочного запроса. Затем вы выбираете строки из набора результатов по одной за раз. Когда все строки обработаны, вы закрываете (CLOSE) курсорную переменную.
В следующем примере показано, как вы можете извлечь строки из результирующего набора динамического многострочного запроса в запись:
Oracle PL/SQL
DECLARE
TYPE EmpCurTyp IS REF CURSOR;
emp_cv EmpCurTyp;
emp_rec emp%ROWTYPE;
sql_stmt VARCHAR2(200);
my_job VARCHAR2(15) := ‘CLERK’;
BEGIN
sql_stmt := ‘SELECT * FROM emp WHERE job = :j’;
OPEN emp_cv FOR sql_stmt USING my_job;
LOOP
FETCH emp_cv INTO emp_rec;
EXIT WHEN emp_cv%NOTFOUND;
— запись процесса
END LOOP;
CLOSE emp_cv;
END;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
DECLARE TYPEEmpCurTypISREFCURSOR; emp_cvEmpCurTyp; emp_recemp%ROWTYPE; sql_stmtVARCHAR2(200); my_jobVARCHAR2(15):=’CLERK’; sql_stmt:=’SELECT * FROM emp WHERE job = :j’; OPENemp_cvFORsql_stmtUSINGmy_job; LOOP FETCHemp_cvINTOemp_rec; EXITWHENemp_cv%NOTFOUND; — запись процесса ENDLOOP; CLOSEemp_cv; END; |
Примеры динамического SQL для типов объектов и коллекций
Следующий пример иллюстрирует использование объектов и коллекций. Предположим, вы определили тип объекта Person и VARRAY тип Hobbies следующим образом:
Oracle PL/SQL
CREATE TYPE Person AS OBJECT (name VARCHAR2(25), age NUMBER);
CREATE TYPE Hobbies IS VARRAY(10) OF VARCHAR2(25);
|
1 2 |
CREATETYPEPersonASOBJECT(nameVARCHAR2(25),ageNUMBER); CREATETYPEHobbiesISVARRAY(10)OFVARCHAR2(25); |
Используя динамический SQL, вы можете создать пакет, который использует эти типы:
Oracle PL/SQL
—создать спецификацию пакета
CREATE OR REPLACE PACKAGE teams AS
PROCEDURE create_table (tab_name VARCHAR2);
PROCEDURE insert_row (tab_name VARCHAR2, p Person, h Hobbies);
PROCEDURE print_table (tab_name VARCHAR2);
END;
—создать тело пакета
CREATE OR REPLACE PACKAGE BODY teams AS
PROCEDURE create_table (tab_name VARCHAR2) IS
BEGIN
EXECUTE IMMEDIATE ‘CREATE TABLE ‘ || tab_name ||
‘ (pers Person, hobbs Hobbies)’;
END;
PROCEDURE insert_row (
tab_name VARCHAR2,
p Person,
h Hobbies) IS
BEGIN
EXECUTE IMMEDIATE ‘INSERT INTO ‘ || tab_name ||
‘ VALUES (:1, :2)’ USING p, h;
END;
PROCEDURE print_table (tab_name VARCHAR2) IS
TYPE RefCurTyp IS REF CURSOR;
cv RefCurTyp;
p Person;
h Hobbies;
BEGIN
OPEN cv FOR ‘SELECT pers, hobbs FROM ‘ || tab_name;
LOOP
FETCH cv INTO p, h;
EXIT WHEN cv%NOTFOUND;
— print attributes of ‘p’ and elements of ‘h’
END LOOP;
CLOSE cv;
END;
END;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
—создать спецификацию пакета CREATEORREPLACEPACKAGEteamsAS PROCEDUREcreate_table(tab_nameVARCHAR2); PROCEDUREinsert_row(tab_nameVARCHAR2,pPerson,hHobbies); PROCEDUREprint_table(tab_nameVARCHAR2); END; CREATEORREPLACEPACKAGEBODYteamsAS PROCEDUREcreate_table(tab_nameVARCHAR2)IS BEGIN EXECUTEIMMEDIATE’CREATE TABLE ‘||tab_name|| ‘ (pers Person, hobbs Hobbies)’; END; PROCEDUREinsert_row( tab_nameVARCHAR2, pPerson, hHobbies)IS BEGIN EXECUTEIMMEDIATE’INSERT INTO ‘||tab_name|| ‘ VALUES (:1, :2)’USINGp,h; END; PROCEDUREprint_table(tab_nameVARCHAR2)IS TYPERefCurTypISREFCURSOR; cvRefCurTyp; pPerson; hHobbies; BEGIN OPENcvFOR’SELECT pers, hobbs FROM ‘||tab_name; LOOP FETCHcvINTOp,h; EXITWHENcv%NOTFOUND; — print attributes of ‘p’ and elements of ‘h’ ENDLOOP; CLOSEcv; END; END; |
Из анонимного блока вы можете вызвать процедуры из пакета TEAMS:
Oracle PL/SQL
DECLARE
team_name VARCHAR2(15);
BEGIN
team_name := ‘Notables’;
teams.create_table(team_name);
teams.insert_row(team_name, Person(‘John’, 31),
Hobbies(‘skiing’, ‘coin collecting’, ‘tennis’));
teams.insert_row(team_name, Person(‘Mary’, 28),
Hobbies(‘golf’, ‘quilting’, ‘rock climbing’));
teams.print_table(team_name);
END;
|
1 2 3 4 5 6 7 8 9 10 11 |
DECLARE team_nameVARCHAR2(15); team_name:=’Notables’; teams.create_table(team_name); teams.insert_row(team_name,Person(‘John’,31), Hobbies(‘skiing’,’coin collecting’,’tennis’)); teams.insert_row(team_name,Person(‘Mary’,28), Hobbies(‘golf’,’quilting’,’rock climbing’)); teams.print_table(team_name); END; |
Подведем итоги
| Конструкция/Блок | Порядок выполнения | Выполняемая функция |
|---|---|---|
| SELECT возвращаемые выражения | 4 | Возврат данных полученных запросом |
| FROM источник | В нашем случае это пока все строки таблицы | |
| WHERE условие выборки из источника | 1 | Отбираются только строки, проходящие по условию |
| GROUP BY выражения группировки | 2 | Создание групп по указанному выражению группировки. Расчет агрегированных значений по этим группам, используемых в SELECT либо HAVING блоках |
| HAVING фильтр по сгруппированным данным | 3 | Фильтрация, накладываемая на сгруппированные данные |
| ORDER BY выражение сортировки результата | 5 | Сортировка данных по указанному выражению |
| SalaryAmount |
|---|
| 5000 |
| SalaryAmount |
|---|
| 2000 |
| 2500 |
| 5000 |






