Sed
Содержание:
Примеры использования sed
Теперь рассмотрим примеры sed Linux, чтобы у вас сложилась целостная картина об этой утилите. Давайте сначала выведем из файла стройки с пятой по десятую. Для этого воспользуемся командой -p. Мы используем опцию -n чтобы не выводить содержимое буфера шаблона на каждой итерации, а выводим только то, что нам надо. Если команда одна, то опцию -e можно опустить и писать без неё:

Или можно вывести весь файл, кроме строк с первой по двадцатую:

Здесь наоборот, опцию -n не указываем, чтобы выводилось всё, а с помощью команды d очищаем ненужное. Дальше рассмотрим замену в sed. Это самая частая функция, которая применяется вместе с этой утилитой. Заменим вхождения слова root на losst в том же файле и выведем всё в стандартный вывод:

Флаг g заменяет все вхождения, также можно использовать флаг i, чтобы сделать регулярное выражение sed не зависимым от регистра. Для команд можно задавать адреса. Например, давайте выполним замену 0 на 1000, но только в строках с первой по десятую:

Переходим ещё ближе к регулярным выражением, удалим все пустые строки или строи с комментариями из конфига Apache:

Под это регулярное выражение (адрес) подпадают все строки, которые начинаются с #, пустые, или начинаются с пробела, а за ним идет решетка. Регулярные выражения можно использовать и при замене. Например, заменим все вхождения p в начале строки на losst_p:

Если вам надо записать результат замены в обратно в файл можно использовать стандартный оператор перенаправления вывода > или утилиту tee. Например:
Также можно использовать опцию -i, тогда утилита не будет выполнять изменения в переданном ей файле:

Если надо сохранить оригинальный файл, достаточно передать опции -i в параметре расширение для файла резервной копии.
Usage
Substitution command
The following example shows a typical, and the most common, use of sed: substitution. This usage was indeed the original motivation for sed:
sed 's/regexp/replacement/g' inputFileName > outputFileName
In some versions of sed, the expression must be preceded by to indicate that an expression follows. The stands for substitute, while the stands for global, which means that all matching occurrences in the line would be replaced. The regular expression (i.e. pattern) to be searched is placed after the first delimiting symbol (slash here) and the replacement follows the second symbol. Slash () is the conventional symbol, originating in the character for «search» in ed, but any other could be used to make syntax more readable if it does not occur in the pattern or replacement; this is useful to avoid «leaning toothpick syndrome».
The substitution command, which originates in search-and-replace in ed, implements simple parsing and templating. The provides both pattern matching and saving text via sub-expressions, while the can be either literal text, or a format string containing the characters for «entire match» or the special escape sequences through for the nth saved sub-expression. For example, replaces all occurrences of «cat» or «dog» with «cats» or «dogs», without duplicating an existing «s»: is the 1st (and only) saved sub-expression in the regexp, and in the format string substitutes this into the output.
Other sed commands
Besides substitution, other forms of simple processing are possible, using some 25 sed commands. For example, the following uses the d command to delete lines that are either blank or only contain spaces:
sed '/^ *$/d' inputFileName
This example uses some of the following regular expression metacharacters (sed supports the full range of regular expressions):
- The caret () matches the beginning of the line.
- The dollar sign () matches the end of the line.
- The asterisk () matches zero or more occurrences of the previous character.
- The () matches one or more occurrence(s) of the previous character.
- The question mark () matches zero or one occurrence of the previous character.
- The dot () matches exactly one character.
Complex sed constructs are possible, allowing it to serve as a simple, but highly specialised, programming language. Flow of control, for example, can be managed by the use of a label (a colon followed by a string) and the branch instruction . An instruction followed by a valid label name will move processing to the block following that label.
sed used as a filter
Under Unix, sed is often used as a filter in a pipeline:
generateData | sed 's/x/y/g'
That is, a program such as «generateData» generates data, and then sed makes the small change of replacing x with y. For example:
$ echo xyz xyz | sed 's/x/y/g' yyz yyz
File-based sed scripts
It is often useful to put several sed commands, one command per line, into a script file such as , and then use the option to run the commands (such as ) from the file:
sed -f subst.sed inputFileName > outputFileName
Any number of commands may be placed into the script file, and using a script file also avoids problems with shell escaping or substitutions.
Such a script file may be made directly executable from the command line by prepending it with a «shebang line» containing the sed command and assigning the executable permission to the file. For example, a file can be created with contents:
#!/bin/sed -f s/x/y/g
The file may then be made executable by the current user with the command:
chmod u+x subst.sed
The file may then be executed directly from the command line:
subst.sed inputFileName > outputFileName
In-place editing
The option, introduced in GNU sed, allows in-place editing of files (actually, a temporary output file is created in the background, and then the original file is replaced by the temporary file). For example:
sed -i 's/abc/def/' fileName
Формат команд редактирования
Скриптовый файл состоит из набора команд:
- ] команда
по одной в каждой строке.
Адреса это либо номера строк, либо специальные символы, либо регулярное выражение:
$ — последняя строканачало~N — Каждая N-я строка, начиная с номера начало/регулярное_выражение/ — строки, попадающие под регулярное_выражение
Примеры:
- 1~2 — Каждая вторая строка
- /REGEXP/ — все строки, в которых встречается /REGEXP/
- 10,20 — строки с 10-й по 20-ю
- 10,+10 — строки с 10-й по 20-ю
- 5,~N — строки начиная с 5-й и до первой, кратной N
- 5,/REGEXP/ — строки, содержащие /REGEXP/, после 5-й(не включая 5-ю)
- Если адрес не указан, обрабатываются все строки.
- Если указан один адрес — обрабатывается соответствующая строка
- Если указаны два адреса, то выбираются строки в заданном интервале.
- !команда — выполняется команда, для строк, которые небыли выбраны по адресам.
Синтаксис команды awk
Сначала надо понять как работает утилита. Она читает документ по одной строке за раз, выполняет указанные вами действия и выводит результат на стандартный вывод. Одна из самых частых задач, для которых используется awk — это выборка одной из колонок. Все параметры awk находятся в кавычках, а действие, которое надо выполнить — в фигурных скобках. Вот основной её синтаксис:
$ awk опции ‘условие {действие}’
$ awk опции ‘условие {действие} условие {действие}’
С помощью действия можно выполнять преобразования с обрабатываемой строкой. Об этом мы поговорим позже, а сейчас давайте рассмотрим опции утилиты:
- -F, —field-separator — разделитель полей, используется для разбиения текста на колонки;
- -f, —file — прочитать данные не из стандартного вывода, а из файла;
- -v, —assign — присвоить значение переменной, например foo=bar;
- -b, —characters-as-bytes — считать все символы однобайтовыми;
- -d, —dump-variables — вывести значения всех переменных awk по умолчанию;
- -D, —debug — режим отладки, позволяет вводить команды интерактивно с клавиатуры;
- -e, —source — выполнить указанный код на языке awk;
- -o, —pretty-print — вывести результат работы программы в файл;
- -V, —version — вывести версию утилиты.
Это далеко не все опции awk, однако их вам будет достаточно на первое время. Теперь перечислим несколько функций-действий, которые вы можете использовать:
- print(строка) — вывод чего либо в стандартный поток вывода;
- printf(строка) — форматированный вывод в стандартный поток вывода;
- system(команда) — выполняет команду в системе;
- length(строка) — возвращает длину строки;
- substr(строка, старт, количество) — обрезает строку и возвращает результат;
- tolower(строка) — переводит строку в нижний регистр;
- toupper(строка) — переводить строку в верхний регистр.
Функций намного больше, но чтобы не загромождать статью я привел только те, которые мы будем использовать сегодня, а также ещё несколько для чтобы вы могли оценить масштаб возможностей утилиты.
В функциях-действиях можно использовать различные переменные и операторы, вот несколько из них:
- FNR — номер обрабатываемой строки в файле;
- FS — разделитель полей;
- NF — количество колонок в данной строке;
- NR — общее количество строк в обрабатываемом тексте;
- RS — разделитель строк, по умолчанию символ новой строки;
- $ — ссылка на колонку по номеру.
Кроме этих переменных, есть и другие, а также можно объявлять свои.
Условие позволяет обрабатывать только те строки, в которых содержатся нужные нам данные, его можно использовать в качестве фильтра, как grep. А ещё условие позволяет выполнять определенные блоки кода awk для начала и конца файла, для этого вместо регулярного выражения используйте директивы BEGIN (начало) и END (конец). Там ещё есть очень много всего, но на сегодня пожалуй достаточно. Теперь давайте перейдем к примерам.
Применение grep в Linux
Одна из более полезных и многофункциональных команд в терминале Linux – бригада «grep». Grep – это акроним, какой расшифровывается как «global regular expression print» (то имеется, «искать везде соответствующие постоянному выражению строки и выводить их»).
Это значит, что grep возможно использовать для того, чтобы проглядеть, соответствуют ли вводимые данные заданным шаблонам. В простенькой форме grep используется для розыска совпадений буквенных шаблонов в текстовом файле. Это значивает, что если команда grep приобретает слово для поиска, она будет выводить каждую сохраняющую это слово строку файла.
Назначение grep — поиск строк согласно условию, изображенному регулярным выражением. Существуют изменения классического grep — egrep, fgrep, rgrep. Все они отточены под конкретные цели, при этом способности grep перекрывают весь функционал. Самым несложным примером использования команды представляется вывод строки, удовлетворяющей шаблону, из файла. Пример мы хотим найти строку, сохраняющую ‘user’ в файле /etc/mysql/my.cnf. Для этого воспользуемся последующей командой:
Grep сможет просто искать конкретное словечко:
Или строку, но в таком варианте её нужно заключать в кавычки:
В добавление альтернативами программы являются egrep и fgrep, которые являются тем же самым, что и, соответственно, grep -E и grep -F. Варианты egrep и fgrep являются устаревшими, но работают для обратной совместимости. Вместо устаревших вариантов рекомендуется использовать grep -E и grep –F.
Команда grep сопоставляет строки исходных файлов с шаблоном, этим базовым регулярным выражением. Если файлы не указаны, используется стандартный ввод. Как как обычно каждая успешно сопоставленная строка копируется на стандартный вывод; если исходных файлов чуть-чуть, перед найденной строкой выдается имя файла. В качестве шаблонов воспринимаются базовые непрерывные выражения (выражения, имеющие своими значениями цепочки символов, и использующие ограниченный комплекс алфавитно-цифровых и специальных символов).
Примеры
Для первого примера, заменим каждое вхождение «пример» на «тест» в файле «dokument».
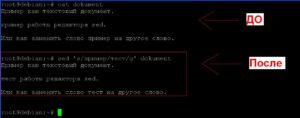
Дополним команду таким образом, чтобы менялось не только слово «пример», но и это же слово написанное с большой буквы. Для этого будем использовать специальные символы «\|».
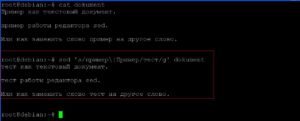
Заменим два фрагмента текста: «документ» на «файл»; «как» на «не». Так как у нас несколько фрагментов текстов, будем использовать ключ «-е».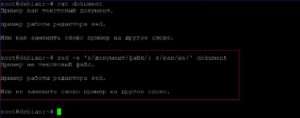
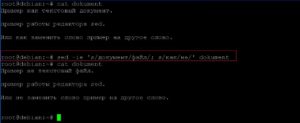
Теперь сохраним все изменения в файл. Для это будем использовать ключ «-i» редактирования файла на месте.
Удалим все пробелы в начале каждой строки слева.
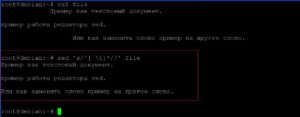
Теперь удалим все пропуски в конце строки.
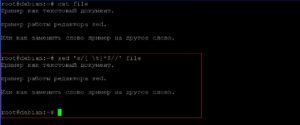
Удаление последней строки.
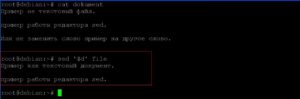
Добавление восьми пробелов в новый файл слева от текстовой информации. Будем использовать перенаправление вывода «>»
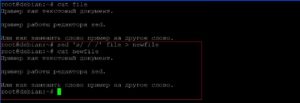
Выведение строк c 3 по 5 файла «newfile».
Выведение всего файла «newfile», кроме строк 3-5.
Удалим все пустые строки и сохраним эти изменения в файле.
Утилита «sed» является весьма гибким и максимально удобным инструментом, позволяющим сделать с текстом многие вещи. Такая команда отличается сложностью в усвоении, но дает решить множество задач.
I. Sed Substitution Delimiter
As we discussed in our previous post, we can use the different delimiters such as @ % | ; : in sed substitute command.
Let us first create path.txt file that will be used in all the examples mentioned below.
$ cat path.txt /usr/kbos/bin:/usr/local/bin:/usr/jbin:/usr/bin:/usr/sas/bin /usr/local/sbin:/sbin:/bin/:/usr/sbin:/usr/bin:/opt/omni/bin: /opt/omni/lbin:/opt/omni/sbin:/root/bin
Example 1 – sed @ delimiter: Substitute /opt/omni/lbin to /opt/tools/bin
When you substitute a path name which has ‘/’, you can use @ as a delimiter instead of ‘/’. In the sed example below, in the last line of the input file, /opt/omni/lbin was changed to /opt/tools/bin.
$ sed 's@/opt/omni/lbin@/opt/tools/bin@g' path.txt /usr/kbos/bin:/usr/local/bin:/usr/jbin/:/usr/bin:/usr/sas/bin /usr/local/sbin:/sbin:/bin/:/usr/sbin:/usr/bin:/opt/omni/bin: /opt/tools/bin:/opt/omni/sbin:/root/bin
Example 2 – sed / delimiter: Substitute /opt/omni/lbin to /opt/tools/bin
When you should use ‘/’ in path name related substitution, you have to escape ‘/’ in the substitution data as shown below. In this sed example, the delimiter ‘/’ was escaped in the REGEXP and REPLACEMENT part.
$ sed 's/\/opt\/omni\/lbin/\/opt\/tools\/bin/g' path.txt /usr/kbos/bin:/usr/local/bin:/usr/jbin/:/usr/bin:/usr/sas/bin /usr/local/sbin:/sbin:/bin/:/usr/sbin:/usr/bin:/opt/omni/bin: /opt/tools/bin:/opt/omni/sbin:/root/bin
Цикл выполнения
sed работает с двумя буферами данных: основным и вспомогательным. Изначально оба буфера пусты.
Работа с этими буферами осуществляется при помощи команд:\\`h’, `H’, `x’, `g’, `G’ `D’ h — Заменить содержимое вспомогательного буфера содержимым основногоH — Добавить новую строку к вспомогательному буферу и затем добавить содержимое основного буфера к содержимому вспомогательногоx — Поменять содержимое обоих буферов местамиg — Заменить содержимое основного буфера содержимым вспомогательногоG — Добавить новую строку к основному буферу и затем добавить содержимое вспомогательного буфера к содержимому основногоD — Удалить текст основного буфера до следующего символа перевода строкиN — Добавить новую строку к основному буферу, затем добавить туда следующую обрабатываемую строкуP — Вывести содержимое основного буфера до следующего символа перевода строки.






