Облачное хранилище: нужна 100% совместимость с amazon s3 api
Содержание:
- S3 и Linux
- Составная загрузка (Multipart Upload)
- Драки, танчики и не только
- Из чего складывается стоимость услуги
- Как подключиться к S3 хранилищу
- Прокачиваем софт
- Организуем файловое хранилище
- Особенности интерфейса
- Уникальность решения — 100% гарантия совместимости с Amazon S3 API
- О надежности и безопасности нашего облака
- AWS и совместимые с ним российские облачные хранилища для бизнеса
- Поддерживаемые методы
S3 и Linux
Теперь пару слов о том, как я делаю бэкап со своих линуксовых серверов. По
мне лучше всего подходит консольный s3-клиентs3cmd. В Ubuntu он входит
в стандартный репозитарий, поэтому устанавливается через менеджер пакетов: . Для того чтобы настроить клиент, ввести пару
ключей, пароль для шифрования, а также указать другие параметры работы с
облаком, необходимо запустить конфигуратор: .
Настройщик проверит соединение, и если они правильные, предложит сохранить их в
конфигурационный файл. Теперь можно приступать к работе. Классно, что в режиме
бэкапа s3cmd очень сильно напоминает rsync, поэтому запускается похожим образом:
Ключ -«-acl-private» означает, что доступ к файлам будет только у нас. С
помощью «—bucket-location=EU» мы указываем регион (в данном случае Европу, а
точнее Ирландию). Опция «—guess-mime-type» обозначает, что MIME-тип содержимого
будет подбираться автоматически, исходя из расширения файла. А чтобы файлы сами
удалились из S3-хранилища, если они исчезают в локальной папке, используется
ключ «—delete-removed». Итак, бэкапы есть. Что надо сделать, чтобы данные
восстановить из резервной копии? Достаточно одной команды:
Чтобы просо посмотреть, что хранится в bucket’е, достаточно ключа ls:
Тут я учитываю, что bucket с именем xakep у нас уже есть. Но если его
необходимо создать, то это опять же очень легко реализуется через s3tools:
Добавляем команду на бэкап в cron и наслаждаемся самым надежным бэкапом,
который только можно представить. Кто сказал, что использовать облачные
технологии сложно и под силу только разработчикам? Пфф, чепуха.
Составная загрузка (Multipart Upload)
Особенность при загрузке объектов.
Составная загрузка позволяет загружать отдельный объект как набор частей.
Примечание: при работе с S3 при Multipart-загрузке больших объектов все загруженные сегменты не собираются в финале в единый объект, а складируются в соседний контейнер с таким же именем и суффиксом .
Для загрузки больших (размер варьируется) объектов по частям используют этот API.
Загрузка выполняется в три этапа.
Инициализация
- Если объект уже существует, то он удаляется.
- Создается контейнер с именем текущего, к нему добавляется суффикс . Далее там будут храниться сегменты загруженного объекта.
- Генерируется uploadId.
- В контейнере с сегментами создаётся мета-объект , который будет хранить Content-Type и все пользовательские метаданные до финализации.
Финализация
- Делается листинг всех объектов по префиксу и сравнивается с листингом, который пришел от клиента.
- Считается суммарный размер объекта и суммируются хэши.
- Создаётся манифест, который будет находиться по пути загружаемого multipart-объекта.
- Из созданного ранее мета-объекта считывается Content-Type и пользовательские метаданные и записываются в манифест, а сам мета-объект затем удаляется.
Реализован данный метод с небольшим ограничением — в качестве разделителя можно использовать только .
Примечание: в бакетах видны контейнеры с сегментами.
Драки, танчики и не только
Втроем можно принимать участие в настоящих сражениях. Вниманию геймеров, предпочитающих коллективные игры масса бомберов, танковые баталии, гонки и драки. Многие из этих предложений устроены таким образом, что играть в них в одиночку получится не всегда, а вот дружной компанией запросто. Есть, конечно же, и такие, где в меню достаточно будет выбрать игру втроем. При этом у каждого будет свой персонаж, которым только он один будет управлять.
По сюжету во многих из подобных предложений побеждает сильнейший. Можно будет попробовать свою силу и сноровку в качестве борцов сумо, но учтите, что это всего лишь игра, и двоим из троих друзей придется слететь с площадки, победителем станет только один. Однако с учетом того, что в виртуальном мире падать не больно, а саму игру всегда можно начать заново шансы стать победителями становятся равными у всех участников. В военных баталиях на троих своя прелесть. Некоторые из них с пошаговым управлением, а есть и такие, в которых все трое смогут управлять выбранными объектами одновременно. В любом случае сражение предстоит интересное.
Кстати, если сражаетесь в закрытом пространстве, то не забудьте учесть, что рикошет никто не отменял. Пули от стен отскакивают здесь с завидным постоянством, а это означает, что нужно быть предельно внимательными. Втроем в некоторых играх можно сражаться сообща, но есть и такие предложения на троих, где самой лучшей станет только одна единица боевой техники. Победа в таком случае будет присуждена одному игроку.
В играх на 3, как нигде в другом месте, присутствует дух соревнования. Особенно это ощутимо во время виртуального ралли. Ехать на бешеной скорости всегда интересно, но если знаешь, что одновременно с тобой до финишной черты мечтает добраться еще два друга, азарт сразу возрастает. Вот где можно оттачивать свое мастерство в управлении, вот где можно доказать, что ты лучший.
В общем, втроем можно все. Можно в крутых разборках участие принять, можно просто погонять друг за другом отстреливаясь и собирая по полю виртуальное оружие для улучшения собственных характеристик. Принять участие во всевозможных соревнованиях тоже можно запросто. Какую бы из игр для троих вы не выбрали, за ней обязательно последует другая, ведь вместе всегда интереснее и веселее.
Из чего складывается стоимость услуги
Основными параметрами, от которых зависит стоимость услуги являются:
Объем хранимых данных. Как правило, цена указывается за 1 ГБ данных и часто стоимость 1 ГБ зависит от общего арендуемого объема хранилища — чем больше данных вы храните, тем дешевле стоимость 1 ГБ. Цена меняется, как правило, в определенном диапазоне, например, до 1 ТБ стоимость может быть p1,43 за гигабайт, а в диапазоне от 1 до 10 ТБ — уже p1,33.
Объем исходящего трафика. Здесь также тарификация происходит за каждый гигабайт, а стоимость зависит от общего потребленного трафика за месяц. Цена изменяется в рамках определенных поставщиком услуги диапазонов, например, до 10 ТБ стоимость за 1 ГБ трафика составит p1,02, тогда как свыше 10 ТБ и до 90 ТБ стоимость за гигабайт будет p0,92.
Количество и тип запросов к API. Выделяют два типа запросов: «PUT, META, LIST, POST, COPY и другие» и «GET и другие». Запросы тарифицируются пакетами по 1 тыс. и 10 тыс. запросов.
Тип хранения: горячее или холодное. Под холодным подразумевается хранение данных, обращение к которым происходит редко. Как правило, к такой категории относят архивы и различные резервные копии систем и приложений. Горячими данными называют объекты, обращение к которым происходит достаточно часто.
Как подключиться к S3 хранилищу

Стоит отметить, что объектные хранилища не предназначены для обработки данных внутри себя, поскольку здесь может быть выполнена операция размещения либо получения объектов
Важно понимать, что с такими хранилищами взаимодействуют не сами пользователи, а приложения или отдельные системы, а основой API выступает протокол HTTP
Для того, чтобы выполнить подключение к S3 хранилищу, можно воспользоваться несколькими способами. Какой из них окажется удобным, решать вам. Приведем пример наиболее часто используемых вариантов:
S3Browser
Программа S3Browser позволяет подключиться к хранилищу по протоколу S3, скачать ее можно с официального сайта компании. Процедура стандартная: необходимо задать имя аккаунту, выбрать тип подключения S3 Compatible Storage, указать адрес подключения, ID ключа доступа, значение секретного ключа и активировать в случае необходимости опцию шифрования данных при подключении. Все. После чего можно работать с хранилищем.

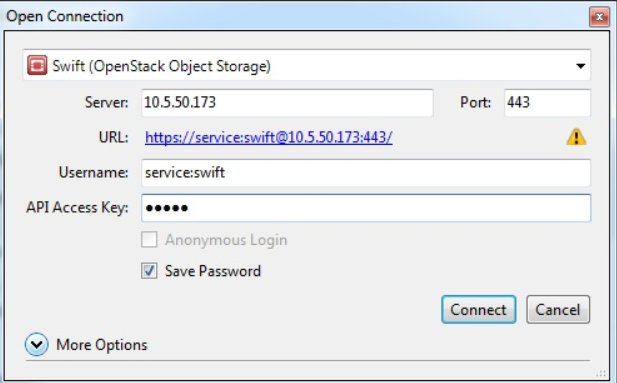
Swift API
Подключиться к S3 хранилищу можно с помощью Swift API через программу Cyberduck, скачав ее предварительно с официального сайта разработчика. После установки и запуска приложения, необходимо выполнить новое подключение. Для этого нужно указать, что вы подключаетесь к объектному хранилищу Swift (OpenStack Object Storage), задать название сервера, номер порта 443, ключ доступа и пароль.
Прокачиваем софт
Единственный недостаток этой утилиты в том, что работает она только под
виндой. Зато в остальном это чрезвычайно мощный инструмент для работы с
S3-хранилищем.
Во-первых, тут есть вкладки: можно даже одновременно работать с разными
учетными записями на Amazon S3, если необходима такая возможность. Во-вторых,
программа не впадает в стопор, когда нужно залить на сервер многогигабайтный
файл (в S3Fox этого лучше не делать!). То же самое касается ситуации, когда в
облако требуется залить огромное количество файлов: все, будь то совсем
маленькие или очень большие, аккуратно встанут в очередь и будут передаваться на
сервера S3. В-третьих, CloudBerry Explorer поддерживает быстрое копирование и
перемещение объектов между аккаунтами и bucket’ами внутри Amazon S3. Т.е. не
надо сначала закачивать файлы себе, а потом опять заливать на сервер — все
происходит прозрачно внутри облака. Естественно, поддерживается переименование
объектов (почему ее нет в S3Fox, мне сложно понять). В-четвертых, ты можешь
расшарить объекты или даже целые «ведра» для других пользователей Amazon S3. С
помощью ACL-листов четко настраиваются все политики безопасности. Кстати, когда
создаешь ссылку, иногда очень полезно выбрать протокол BitTorrent (опция «generate
bittorent url). В этом случае файл из облака будет скачиваться через Torrent’ы.
Это очень классная фишка Amazon S3, которая пригодится, чтобы сэкономить трафик.
Пользователи при таком раскладе будут выкачивать объект не только из облака, но
и с компьютеров друг друга. Мало того, для любой сгенерированной ссылки можно
обозначить срок годности, после которого она будет невалидна
И что важно: при
всех плюсах CloudBerry Explorer остается бесплатным для всех пользователей.
Впрочем, разработчики знали, как можно заставить пользователей платить. В ее
старшем брате, за который просится $40, есть еще несколько умопомрачительных
фишек
Во-первых, это поддержка шифрования и версионности, которые предлагаются
Amazon S3. А, во-вторых, возможность использования Powershell-скриптов для
автоматизации практически любых задач. Попробуем автоматизировать закачку
содержимого c:\workdata\ в bucket «xakep», причем имя новой директории в облаке
будет генериться автоматически, исходя из текущей даты (2010_06_01 — такой
формат удобнее для сортировки):
Отличный способ выполнить умный бэкап. Впрочем, для резервного копирования в
облако S3 есть специализированные программы. Разработчики CloudBerry Explorer
предлагают очень простое и толковое, но, к сожалению, платное решение —
CloudBerry Online Backup. А лично я используюS3 Backup,
правда, и тут беда. Программа постепенно приближается к официальному релизу, и
разработчики грозятся сделать ее платной
Во время бэкапа важно помнить о
максимальном ограничении файла для S3 — 5 Гб. К счастью, обе утилиты могут
использовать компрессию так, чтобы уложиться в это ограничение
Организуем файловое хранилище
Все, теперь создаем новый аккаунт в S3Fox, вводим ключи — и, ву-а-ля,
соединение устанавливается. Выглядит S3Fox, как и любой файловой менеджер с
двумя панелями: с одной стороны локальные диски, с другой — облако. Если
попробовать переместить файл или папку, плагин скажет, что для этого
предварительно нужно создать bucket. Объект в облаке не может болтаться сам по
себе и обязательно должен быть привязан к одному из «ведер». Сам процесс
создания bucket мало чем отличается от создания каталога на локальном диске, о
правилах составления имени подскажет сам плагин. В целом надо использовать те
символы, которые могут быть в URL — как я уже сказал, имя «ведра» далее
используется для составления URL для доступа файла извне. Пробуем залить файл —
получилось. Выберем целую папку — нет проблем, файлы по очереди заливаются с
использованием очереди. Теперь посмотрим, доступны ли файлы извне. Через
контекстное меню какого-нибудь файла нажмем «Copy URL» и попробуем открыть
полученную ссылку в браузере (http://xakep.s3.amazonaws.com/xtoolz/scanner.zip).
Облом:
Доступ запрещен. Необходимо опять же через контекстное меню изменить права
доступа («Edit ACL») и сделать файл доступным для всех — после этого все сразу
заработает. S3Fox позволяет выполнять все элементарные действия с файлами и даже
поддерживает простейшую синхронизацию каталогов. Еще один плюс в том, что плагин
кроссплатформенный и может быть установлен к браузеру под любой ОС. С другой
стороны, когда начинаешь работать с Amazon S3 более плотно, приходит понимание,
что функционала у плагина недостаточно. Каково было мое удивление, когда я хотел
переименовать файл, а такой возможности… не оказалось. Нет и поддержки более
дешевого хранилища RRS, о котором мы говорили. В общем, с этого момента я стал
использовать инструмент посерьезнее —CloudBerry Explorer.
Особенности интерфейса
Несмотря на то, что в целом технологии объектного хранилища развиваются уже более 20 лет, до сих пор нет какого-то одного общепринятого стандарта интерфейса. Но за это время довольно прочно закрепилась тройка самых популярных интерфейсов:
S3 API. В данном случае S3 переводится как Simple Storage Service. Данный интерфейс принадлежит облачному провайдеру Amazon.
Object Storage API или Swift API. Данный интерфейс принадлежит компании OpenStack. Это некоммерческая организация, занимающаяся разработкой технологий облачных услуг.
CDMI, разработанный Storage Networking Industry Association (SNIA).
Уникальность решения — 100% гарантия совместимости с Amazon S3 API
Представленные в России объектные хранилища, как правило, создаются на базе решений Ceph или Swift с коннекторами для S3 API и не обеспечивают полной поддержки S3 API. Для пользователей это может означать:
- Проблема совместимости приложений (приложение написано с учетом полного набора команд S3, а хранилище, например, поддерживает половину).
- Ограниченную функциональность.
Поэтому при разработке своего объектного облачного хранилища мы обратили особое внимание именно на полноту поддержки S3 API, то есть на совместимость и функциональность решения. Полная совместимость с Amazon Simple Storage Service (S3) API — одна из главных особенностей облачного решения для хранения данных Техносерв Cloud
Поддержка стандартов подключения к облачным хранилищам (API облака) значительно упрощает интеграцию систем заказчика с облачной платформой (см. Рис. 4)
Полная совместимость с Amazon Simple Storage Service (S3) API — одна из главных особенностей облачного решения для хранения данных Техносерв Cloud. Поддержка стандартов подключения к облачным хранилищам (API облака) значительно упрощает интеграцию систем заказчика с облачной платформой (см. Рис. 4).
Полнофункциональная поддержка S3 API гарантирует совместимость с различным программным обеспечением. S3 API поддерживается большим количеством приложений, в частности, практически всеми системами резервного копирования (кроме Veeam) и системами управления контентом (например, 1С-Битрикс или WordPress). Доступен также комплекс средств разработки приложений для любых платформ и на любых языках.
Между тем, многие системы хранения данных большого объема в облаке работают через коннекторы S3 и поддерживают только часть операций, что создает риски для работоспособности всей системы. Например, решения на базе CEPH с коннектором S3, обладают «средней совместимостью» по операциям.
Рис. 4. Поскольку хранилище Техносерв Cloud на 100% совместимо по протоколам с AWS S3, «переезд» из S3 на эту платформу очень прост. Достаточно в приложении заменить адрес сервера и ввести новый ключ.
Ядро облачного хранилища Техносерв Cloud не только построено с использованием технологий S3, но и поддерживает полный спектр команд S3 API, включая расширенные, такие как управление ACL (правами доступа), аутентификация V4SIG (современный протокол авторизации Amazon), полноценное управление версиями, многопоточная загрузка и др.
Так, если решения на базе CEPH предлагают ограниченную поддержку команд S3 API, то решение от «Техносерв» поддерживает практически весь «корпоративный набор». Это означает минимум проблем для заказчика при организации резервного копирования или развертывании других приложений, высокую совместимость с облаком Amazon сейчас и в будущем.
О надежности и безопасности нашего облака
Мы долго и упорно прорабатывали эту важную тему. Отличительные черты Техносерв Cloud – высокая надежность и безопасность. Надежность хранения данных составляет «восемь девяток» (99,999999%), что примерно в 100 раз выше, чем при классической системе хранения с RAID 6 (см. Рис. 6).
Рис. 6. В основе облачного решения «Техносерв» — программно-определяемое хранилище (SDS), в котором отсутствует единая точка отказа и предусматривается полное резервирование всех компонентов.
Чтобы обеспечить избыточность при хранении, каждый файл разбивается на определенное количество частей. По умолчанию используется Erasure Coding 5+3. Это означает, что любой объект (файл) распределяется на восемь узлов (серверов), причем для сохранения целостности файла достаточно любых пяти частей (см. Рис. 7). Таким образом, данные остаются доступными даже при полной одновременной потере любых трех серверов. EC 5+3 обеспечивает надежность 99,999999% (8 девяток). Возможны также варианты EC 4+4 или любой репликации от 2 до N.
Рис. 7. Использование Erasure Coding для повышения надежности хранения.
Наконец, размещается облачное хранилище Техносерв Cloud на площадке с высоким уровнем доступности — в дата-центре Tier III компании DataPro. Этот ЦОД имеет два сертификата Uptime Institute – «Desing» и «Constructed Facility». В России только четыре дата-центра имеют подобную сертификацию.
Уровень Tier III дает возможность проведения ремонтных работ (включая замену компонентов системы, добавление и удаление вышедшего из строя оборудования) без остановки дата-центра. Инженерные системы однократно зарезервированы, есть несколько каналов распределения электропитания и охлаждения, два независимых ввода электропитания от разных подстанций, собственная трансформаторная подстанция, два независимых маршрута ВОЛС.
Гарантированный SLA предусматривает доступность услуги на уровне 99,95 %, то есть не более 21 мин простоя в месяц. Плюс, круглосуточная линия технической поддержки с квалифицированными инженерами.
Предусматривается также резервирование сетевой архитектуры (см. Рис. 8) и компонентов серверов. Резервируются блоки питания, процессоры, сетевые интерфейсы, диски ОС, устройства хранения (согласно архитектуре SDS).
Рис. 8. Резервирование сетевой архитектуры для обеспечения высокой доступности.
Безопасности облачного хранилища мы также уделили особое внимание. Шифрование при передаче и хранении данных (с возможностью шифрования на стороне хранилища ключом клиента), детальная настройка прав доступа, занесение в журнал всех операций с файлами обеспечивают надежную защиту информации клиентов
Кроме того, в целях информационной безопасности проводится регулярный кадровый мониторинг. Сотрудники службы эксплуатации облачной платформы Техносерв Cloud проходят тщательную проверку перед приемом на работу (включая проверку на полиграфе). Такой сервис можно использовать для самых ответственных задач.
AWS и совместимые с ним российские облачные хранилища для бизнеса
| Провайдер | Название сервиса | Описание |
| 1cloud | Cloud Object Storage | Облачное объектное хранилище для резервного копирования, архивных данных, раздачи статического контента сайта, данных веб-приложений, систем видеонаблюдения, обмена корпоративными документами. Для подключения приложений и интеграции с информационными системами можно использовать S3 или OpenStack Swift API. |
| «Техносерв» | Техносерв Cloud | Услуга помогает сократить затраты на создание и техническое обслуживание инфраструктуры, повысить гибкость бизнес-процессов и обеспечить круглосуточный доступ к данным через интернет, выделенный канал связи. Облачное объектное хранилище совместимо с хранилищем Amazon Web Services, полностью поддерживает протокол доступа S3 API. |
| Mail.Ru Group | Mail.Ru Cloud Solutions | Разработчики использовали опыт управления собственной ИТ-инфраструктурой с миллионами пользователей, чтобы создать облачные сервисы без ограничений скорости загрузки и выгрузки файла с высоким уровнем безопасности. Поддерживается стандартный S3-совместимый протокол, шифрование данных по SSL. |
| cloud4y | MultiStore | Облачное хранилище MultiStore позволяет создать логические разделы в одной системе хранения данных таким образом, что неавторизованные пользователи не могут получить доступ к информации в защищенном виртуальном разделе. Оно также позволяет переносить виртуальные разделы между СХД и позиционируется как легко управляемый и мощный инструмент аварийного восстановления системы. |
| Selectel | Cloud Storage | Облачное хранилище для веб-приложений, хранения архивов, резервного копирования и раздачи статического контента с оплатой за хранение, запросы к API и скачивание данных из хранилища. Вне зависимости от объема данных и уровня пиковой нагрузки сохраняется быстрый доступ к контенту. Количество и объем файлов не ограничены. Возможно подключение собственного или стороннего приложения через API OpenStack Swift. Предлагает управление пользователями, доменами, сертификатами через API. Есть ряд готовых плагинов и интеграций с CMS, CRM и другими сервисами. Более 200 000 серверов по всему миру образуют CDN для ускорения работы сайтов и доставки контента. |
| Экономия затрат на ИТ | Собственные СХД требуют постоянного обслуживания, а это означает, что компания должна иметь ИТ-персонал. Благодаря облачному хранилищу компании могут сэкономить много денег на обслуживании, так как их серверы и СХД находятся под контролем сторонних поставщиков. Благодаря аутсорсингу хранилищ данных компании экономят на капитальных и эксплуатационных расходах. Эти деньги можно использовать для развития и расширения бизнеса. |
| Гибкость бизнес-процессов | Согласно недавним опросам опросу, 79% респондентов уже частично работают вне своего офиса, а еще 60% перейдут на удаленную работу, если получат такую возможность. Облачные сервисы хранения обеспечивают такую гибкость для сотрудников. |
| Расширенные возможности коллективной работы | Сотрудникам часто приходится совместно работать над проектами и общаться с коллегами по всему миру. Облачные инструменты облегчают сотрудничество и управление документами. Они позволяют пользователям получать доступ к последним версиям любого документа. |
| Защита данных | Данные хранятся в нескольких местах и остаются доступными в случае аварий и сбоев. |
Поддерживаемые методы
Облачное хранилище поддерживает базовые методы для работы с HTTP API Amazon S3.
| Метод | Команда | Действие | Доступ |
|---|---|---|---|
| GET Service | GET / | Получение спискабакетов | Пользователь получает листинг только тех бакетов, к которым у него есть доступ на чтение и запись |
| DELETE Bucket | DELETE | Удаление бакета | Пользователь может удалить бакет, если он имеет доступ на чтение и запись |
| GET Bucket (List Objects) Version 1 | GET | Получение списка объектов в бакете | Пользователь может получить листинг объектов только того бакета, к которому он имеет доступ на чтение и запись |
| HEAD Bucket | HEAD | Получение статуса бакета | Пользователь может получить статус бакета, если у него есть доступ на чтение и запись |
| List Multipart Uploads | GET | Получение списка загружаемых multipart-объектов | Пользователь может получить листинг загружаемых multipart-объектов только того бакета, к которому он имеет доступ на чтение и запись |
| PUT Bucket | PUT | Создание бакета | Пользователь может создать бакет, если он имеет доступ на чтение и запись |
| Delete Multiple Objects | POST | Множественное удаление объектов в бакете | Пользователь может удалить несколько объектов, если он имеет доступ на чтение и запись в бакет |
| DELETE Object | DELETE | Удаление объекта | Пользователь может удалить объект, если он имеет доступ на чтение и запись в бакет |
| GET Object | GET | Получение объекта | Пользователь может получить объект, если он имеет доступ на чтение и запись |
| HEAD Object | HEAD | Получение метаданных объекта | Пользователь может получить метаданные объекта, если он имеет доступ на чтение и запись |
| PUT Object | PUT | Создание объекта | Пользователь может создать объект, если он имеет доступ на чтение и запись |
| PUT Object — Copy | PUT (x-amz-copy-source) | Копирование объекта | Пользователь может скопировать объект, если он имеет доступ на чтение и запись в бакет-источник |
| Initiate Multipart Upload | POST | Инициирование загрузки multipart-объекта | Пользователь может инициировать multipart upload, если он имеет доступ на чтение и запись |
| Complete Multipart Upload | POST | Финализация загрузки multipart-объекта | Пользователь может финализировать multipart upload, если он имеет доступ на чтение и запись |
| Abort Multipart Upload | DELETE | Отмена загрузки multipart-объекта | Пользователь может отменить загрузку multipart-объекта, если он имеет доступ на чтение и запись |
| List Parts | GET | Получение списка сегментов multipart-объекта | Пользователь может получить список сегментов, если он имеет доступ на чтение и запись |
| Upload Part | PUT | Загрузка части multipart-объекта | Пользователь может создать часть multipart-объекта, если он имеет доступ на чтение и запись |
| Upload Part — Copy | PUT (x-amz-copy-source) | Копирование части multipart-объекта | Пользователь может скопировать часть multipart-объекта, если он имеет доступ на чтение и запись в бакет-источник |
При копировании объекта самого в себя выполняется модификация метаданных объекта.
Удаляется каждый загруженный сегмент, затем и мета-объект.
В этом методе к имени бакета добавляется суффикс _s3multipartuploads, а путь к объекту заменяется на .






