Python multiprocessing example
Содержание:
- Стандартная библиотека
- Implementing the Multiprocessing Function
- Multiprocessing in the Real World
- Conclusion
- Learning more
- Sharing Data Between Processes — Shared Memory
- Multiprocessing Manager
- Странности, которые не странности
- Waiting for Processes¶
- Integration with async
- Band-aids and workarounds
- Why pay for a powerful CPU if you can’t use all of it?
- How to Create Threads in Python?
- How to Achieve Multithreading in Python3?
- ООП
- Best practices and tips¶
- Переменные и данные
- How to Create Multithreading in Python3?
- Why do we need to Use Multi-Processing? How it’s different from Multi-Threading?
- What is GIL? Why it’s important?
- Methodology
- The mystery is solved
- The «interpreters» Module
- Multiprocessing Value and Lock
- Python Multiprocessing
Стандартная библиотека
Обычно стандартная библиотека питона включает отличные решения типовых проблем, однако стоит подходить критически, ибо хватает и странностей. Правда бывает и так, что то, что на первый взгляд кажется странным, в итоге оказывается наилучшим решением, просто нужно знать все условия (см. далее про range), но всё же есть и странности.
Например, идущий в комплекте модуль для модульного тестирования unittest не имеет никакого отношения к питону и попахивает джавой, поэтому, как : «Eveybody is using py.test …». Хотя вполне интересный, пусть и не всегда подходящий модуль doctest идёт в стандартной поставке.
Идущий в поставке модуль urllib не имеет такого прекрасного интерфейса как стронний модуль requests.
Та же история с модулем для разбора параметров коммандной строки — идущий в комплекте argparse это демонстрация ООП головного мозга, а модуль docopt кажется просто шикарным решением — предельная самодокументируемость! Хотя, по слухам, несмотря на docopt и для click остаётся ниша.
С отладчиком также — как я понял идущий в комплекте pdb мало кто использует, альтернатив много, но похоже основная масса разработчиков используется ipdb, который, с моей точки зрения удобнее всего использовать через модуль-обёртку debug.
Она позволяет вместо просто написать , также она добавляет модуль see для удобной инспекции объектов.
На замену стандартному модулю сериализации pickle делают dill, тут кстати стоит запомнить, что эти модули не подходят для обмена данными в внешними системами т.к. восстанавливать произвольные объекты полученные из неконтролируемого источника небезопасно, для таких случаев есть json (для REST) и gRPC (для RPC).
На замену стандартному модулю обработкти регулярных выражений re делают модуль regex со всякими дополнительными плюшками, вроде классов символов аля .
Кстати, что-то не попалось для питона весёлого отладчика для регексов похожего на перловый.
Вот другой пример — человек сделал свой модуль in-place, чтобы пофиксить кривизну и неполноту API стандартного модуля fileinput в части in place редактирования файлов.
Implementing the Multiprocessing Function
Inside of the multiprocessing function, we can create a shared memory array:
Now we have to define a child-function inside of that will calculate an individual row of the data.This is so that we can pass a function when we create our processes later.
Again, these are the same useless calculations performed as a computing test.
Now, for each row in the fake data, we can create a new and start it:
And finally, after all the processes have been started, we can them, and return the data:
As a recap, here is the full function with multiprocessing implemented:
Now it’s time to evaluate our improvement.
Running…
…prints approximately 6 seconds.
That’s quite an improvement!
And if we have a look at the CPU usage log while running the function…
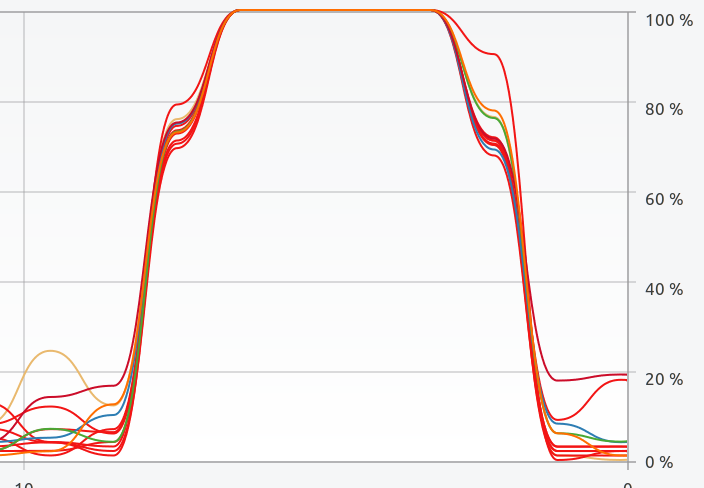
All cores are being used to their maximum extent
That looks a lot better!
One may ask if my CPU says it has 12 cores, why does the process only speed up 5–6 times?Many modern CPU architectures use hyper-threading, which means that although to my OS it appears that I have 12 cores; in reality, I only have half of that, while the other half is simulated.
You may also want to delete the shared memory file after the computations are finished so that no errors will be raised if you’re going to re-run your program.You can do that with:
SharedArray.delete('data')
Multiprocessing in the Real World
Let’s say we’re in a Kaggle competition with a ton of images we need to load. Understanding Clouds from Satellite Images, let’s say. Maybe we want to make a data-generator function that spits out a batch of 300 images, in form.
Assuming we had all of the image data in a folder named “train_images,” we would write a function something along the lines of…
The images in the dataset are 1400×2100 and in RGB
…to load the data.
- returns a list of everything in a directory, which in our case is the file names of all the images
- reads an image and automatically turns it into a Numpy array. You can read more about installing and using OpenCV on Wheels (cv2) here.
Of course, this function doesn’t return the labels for the images, and it gives you the same 300 images every time, so it’s not entirely practical, but that functionality is simple to add.
Then we can measure the time this function takes to compute using the same methods we had earlier, which for me is approximately 12–13 seconds.
That’s not good. If we are going to be doing this inside of a generator to pass to a prediction model, a lot of our time is going to be spent loading the images. We can’t keep all of the images loaded at once, as loading only ~300 1400×2100 images into Numpy arrays takes 20–25 GiB of RAM.
Using the skills we learned when multiprocessing our toy example, we can speed this function up a lot.
First, we can create a for our data:
Next, we do something a little different. Since we don’t have infinite CPU cores, creating more processes than we have cores will ultimately slow down the function. To resolve this, we can create , which will each have a set amount of images to load, .
You can change the number of workers to fit the specifications of your CPU.
After that, we can create a target function that each worker will compute; the function will take a starting index, , and the number of images to load, .
Then, we can start a new process for every worker, and assign it images to load.
gives us the index at which to start loading the next set of images.
And finally, we can each process, and return the data we generated.
As a quick recap, here is the full function we just wrote:
Now using the same method we’ve used before, we can time our function, which, for me, takes a bit less than 2 seconds.
If we would be doing this hundreds, or even thousands of times, saving 11 seconds per loading session equates to anywhere between, 18 minutes and 3 hours of saved time for 100 times and 1000 times respectively.
Conclusion
The example above is reflective of not only how beneficial multiprocessing can be, but of how important it is for us to optimize the calculations we do most frequently.
Learning more
My explanation here is of course somewhat simplified: for example, there is state other than threads that doesn’t copy.
Here are some additional resources:
- Read the Linux man page for to learn about other things it doesn’t copy.
- Rachel By The Bay’s post on why threads and processes don’t mix and a followup are where I originally learned about this problem—and I promptly forgot about it until I encountered a related issue in production code.
- Some mathematical analysis of your chances of getting eaten by a shark and a followup.
Stay safe, and watch out for sharks and bad interactions between threads and processes!
Before we understand how to share data between processes, let’s get familiar with the fundamentals of different processes.
Each Process will have its own share of resources, meaning the memory and CPU allocation are native to each process.
Every process will have it’s own memory or address space which is native to that process alone. So, data in these processes would be stored in these individual memories. Hence, sharing of objects would require some sort of communication between the processes.
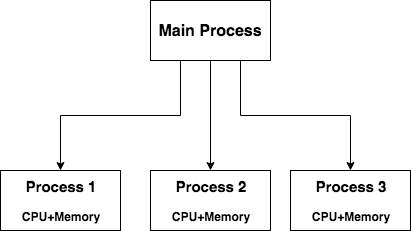
To share data between these processes, some sort of communication must exist between the processes. This is where the concept of Inter Process Communication (IPC) comes into play.
We would require a common storage area or shared memory to access these objects from the different launched processes.
The Multiprocessing Module provides some objects designed specifically to share data between processes. Some of these methods are described below.
Note: If your processes don’t require a lot of CPU Power but involve a lot of common shared variables, then threading module is recommended in this case.
Multiprocessing Manager
A Multiprocessing manager maintains an independent server process where in these python objects are held.
Multiprocessing Library also provides the Manager class which gives access to more synchronization objects to use between processes.
The Manager object supports types such as lists, dict, Array, Queue, Value etc.
When to use Multiprocessing Manager ?
- When there is a requirement to use synchronization objects such as lists, dict etc.
- If the processes are running across a network and require data sharing then the multiprocessing manager is a good fit.
Below example shows how to use a Manager List in a pool of workers
Странности, которые не странности
На первый взгляд мне показалось странным, что тип range не включает правую границу, но потом добрый человек мне неучу где мне нужно поучиться и оказалось, что всё вполне логично.
Отдельная большая тема это округления (хотя это проблема общая практически для всех языков программирования), помимо того, что округление используется какое угодно кроме того, что все изучали в школьном курсе математики, так на это ещё накладываются проблемы преставления чисел с плавющей точкой, отсылаю к подробной статье.
Грубо говоря вместо привычного, по школьному курсу математики, округления по алгоритма используется алгоритм , которые уменьшает вероятность искажений при статистическом анализе и поэтому рекомендуется стандартом IEEE 754.
Также я не мог понять почему , а потом, другой добрый человек, , что это неизбежно следует из самого математического определения, по которому, остаток не может быть отрицательным, что и приводит к такому необычному поведению для отрицательных чисел.
ACHTUNG! Теперь это опять странность и я ничего не понимаю, см. сей .
Waiting for Processes¶
To wait until a process has completed its work and exited, use the
join() method.
import multiprocessing
import time
import sys
def daemon():
print 'Starting:', multiprocessing.current_process().name
time.sleep(2)
print 'Exiting :', multiprocessing.current_process().name
def non_daemon():
print 'Starting:', multiprocessing.current_process().name
print 'Exiting :', multiprocessing.current_process().name
if __name__ == '__main__'
d = multiprocessing.Process(name='daemon', target=daemon)
d.daemon = True
n = multiprocessing.Process(name='non-daemon', target=non_daemon)
n.daemon = False
d.start()
time.sleep(1)
n.start()
d.join()
n.join()
Since the main process waits for the daemon to exit using
join(), the “Exiting” message is printed this time.
$ python multiprocessing_daemon_join.py Starting: non-daemon Exiting : non-daemon Starting: daemon Exiting : daemon
By default, join() blocks indefinitely. It is also possible to
pass a timeout argument (a float representing the number of seconds to
wait for the process to become inactive). If the process does not
complete within the timeout period, join() returns anyway.
import multiprocessing
import time
import sys
def daemon():
print 'Starting:', multiprocessing.current_process().name
time.sleep(2)
print 'Exiting :', multiprocessing.current_process().name
def non_daemon():
print 'Starting:', multiprocessing.current_process().name
print 'Exiting :', multiprocessing.current_process().name
if __name__ == '__main__'
d = multiprocessing.Process(name='daemon', target=daemon)
d.daemon = True
n = multiprocessing.Process(name='non-daemon', target=non_daemon)
n.daemon = False
d.start()
n.start()
d.join(1)
print 'd.is_alive()', d.is_alive()
n.join()
Since the timeout passed is less than the amount of time the daemon
sleeps, the process is still “alive” after join() returns.
Integration with async
Per Antoine Pitrou :
Has any thought been given to how FIFOs could integrate with async code driven by an event loop (e.g. asyncio)? I think the model of executing several asyncio (or Tornado) applications each in their own subinterpreter may prove quite interesting to reconcile multi- core concurrency with ease of programming. That would require the FIFOs to be able to synchronize on something an event loop can wait on (probably a file descriptor?).
A possible solution is to provide async implementations of the blocking
channel methods (recv(), and send()). However,
the basic functionality of subinterpreters does not depend on async and
can be added later.
Alternately, «readiness callbacks» could be used to simplify use in
async scenarios. This would mean adding an optional callback
(kw-only) parameter to the recv_nowait() and send_nowait()
channel methods. The callback would be called once the object was sent
or received (respectively).
Band-aids and workarounds
There are some workarounds that could make this a little better.
For module state, the library could have its configuration reset when child processes are started by .
However, this doesn’t solve the problem for all the other Python modules and libraries that set some sort of module-level global state.
Every single library that does this would need to fix itself to work with .
For threads, locks could be set back to released state when is called (Python has a ticket for this.)
Unfortunately this doesn’t solve the problem with locks created by C libraries, it would only address locks created directly by Python.
And it doesn’t address the fact that those locks don’t really make sense anymore in the child process, whether or not they’ve been released.
Luckily, there is a better, easier solution.
Why pay for a powerful CPU if you can’t use all of it?
Sebastian TheilerFollow
Oct 2, 2019 · 6 min read
That’s a lot of money to be spending on a CPU. And if you can’t utilize it to its fullest extent, why even have it?
Multiprocessing lets us use our CPUs to their fullest extent. Instead of running programs line-by-line, we can run multiple segments of code at once, or the same segments of code multiple times in parallel. And when we do this, we can split it among multiple cores in our CPU, meaning that can compute calculations much faster.
And luckily for us, Python has a built-in multiprocessing library.
The main feature of the library is the class. When we instantiate , we pass it two arguments. , the function we want it to compute, and , the arguments we want to pass to that target function.
import multiprocessingprocess = multiprocessing.Process(target=func, args=(x, y, z))
After we instantiate the class, we can start it with the method.
process.start()
On Unix-based operating systems, i.e., Linux, macOS, etc., when a process finishes but has not been joined, it becomes a zombie process. We can resolve this with .
How to Create Threads in Python?
Firstly import module called then we have to define a function which does something that targets the function by using variable
Let’s get started:
import threadingdef new(): for x in range(6): print("Child Thread Here!!")t1=Thread(target=new)
By using start() function we begin the thread also we used because if we don’t use join() then it executes the main function first, so by using join it means “wait for a thread/process to complete” then after it goes to the main function.
t1.start()t1.join()print("Main Thread Here!!")
How to Achieve Multithreading in Python3?
Multithreading in Python can be achieved by importing the module but before importing the module you have to install this module in your respective IDE.
import threadingfrom queue import Queueimport time
ООП
ООП в питоне сделано весьма интересно (одни чего стоят) и это большая тема, однако сапиенс знакомый с ООП вполне может нагуглить всё (или найти на хабре), что ему захочется, поэтому нет смысла повторяться, хотя стоит оговорить, что питон следует немного другой философии — считается, что программист умнее машины и не является вредителем (UPD: подробнее), поэтому в питоне по умолчанию нет привычных по другим языкам модификаторов доступа: private методы реализуются добавлением двойного подчёркивания (что в рантайме изменяет имя метода не позволяя случайно его использовать), а protected одним подчёркиванием (что не делает ничего, это просто соглашение об именовании).
Те кто скучает по привычному функционалу могут поискать попытки привнести в питон такие возможности, мне нагуглилась пара вариантов (lang, python-access), но я их не тестировал и не изучал.
Единственный минус стандартных классов — шаблонный код во всяких дандер методах, лично мне нравится библиотека attrs, она значительно более питоническая.
Стоит упомянуть, что так в питоне всё объекты, включая функции и классы, то классы можно создавать динамически (без использования ) функцией .
Также стоит почитать про (на хабре) и дескрипторы (хабр).
Особенность, которую стоит запомнить — атрибуты класса и объекта это не одно и тоже, в случае неизменяемых атрибутов это не вызывает проблем так как атрибуты «затеняются» (shadowing) — создаются автоматически атрибуты объекта с таким же именем, а вот в случае изменяемых атрибутов можно получить не совсем то, что ожидалось:
получаем:
как можно увидеть — изменяли , а изменился и в т.к. этот атрибут (в отличии от ) принадлежит не экземпляру, а классу.
Best practices and tips¶
Avoiding and fighting deadlocks
There are a lot of things that can go wrong when a new process is spawned, with
the most common cause of deadlocks being background threads. If there’s any
thread that holds a lock or imports a module, and is called, it’s very
likely that the subprocess will be in a corrupted state and will deadlock or
fail in a different way. Note that even if you don’t, Python built in
libraries do — no need to look further than .
is actually a very complex class, that
spawns multiple threads used to serialize, send and receive objects, and they
can cause aforementioned problems too. If you find yourself in such situation
try using a , that doesn’t
use any additional threads.
We’re trying our best to make it easy for you and ensure these deadlocks don’t
happen but some things are out of our control. If you have any issues you can’t
cope with for a while, try reaching out on forums, and we’ll see if it’s an
issue we can fix.
Reuse buffers passed through a Queue
Remember that each time you put a into a
, it has to be moved into shared memory.
If it’s already shared, it is a no-op, otherwise it will incur an additional
memory copy that can slow down the whole process. Even if you have a pool of
processes sending data to a single one, make it send the buffers back — this
is nearly free and will let you avoid a copy when sending next batch.
Asynchronous multiprocess training (e.g. Hogwild)
Using , it is possible to train a model
asynchronously, with parameters either shared all the time, or being
periodically synchronized. In the first case, we recommend sending over the whole
model object, while in the latter, we advise to only send the
.
We recommend using for passing all kinds
of PyTorch objects between processes. It is possible to e.g. inherit the tensors
and storages already in shared memory, when using the start method,
however it is very bug prone and should be used with care, and only by advanced
users. Queues, even though they’re sometimes a less elegant solution, will work
properly in all cases.
Warning
You should be careful about having global statements, that are not guarded
with an . If a different start method than
is used, they will be executed in all subprocesses.
Hogwild
A concrete Hogwild implementation can be found in the examples repository,
but to showcase the overall structure of the code, there’s also a minimal
example below as well:
import torch.multiprocessing as mp
from model import MyModel
def train(model):
# Construct data_loader, optimizer, etc.
for data, labels in data_loader
optimizer.zero_grad()
loss_fn(model(data), labels).backward()
optimizer.step() # This will update the shared parameters
if __name__ == '__main__'
num_processes = 4
model = MyModel()
# NOTE: this is required for the ``fork`` method to work
model.share_memory()
processes = []
for rank in range(num_processes):
p = mp.Process(target=train, args=(model,))
p.start()
processes.append(p)
for p in processes
p.join()
Переменные и данные
Переменные в питоне не хранят данные, а лишь ссылаются на них, а данные бывают изменяемые (мутабельные) и неизменяемые (иммутабельные).
Это приводит к различному поведению в зависимости от типа данных в практически идентичных ситуациях, например такой код:
приводит к тому, что переменные и ссылаются на различные данные, а такой:
нет, и остаются ссылками на один и тот же список (хотя как пример не очень удачный, но лучше я пока не придумал), что кстати в питоне можно проверить оператором (я уверен что создатель джавы навсегда лишился хорошего сна от стыда когда узнал про этот оператор в питоне).
Строки хотя и похожи на список являются иммутабельным типом данных, это значит, что саму строку изменить нельзя, можно лишь породить новую, но переменной можно присвоить другое значение, хотя исходные данные при этом не изменятся:
Кстати, о строках, из-за их иммутабельности конкатенация очень большого списка строк сложением или append’ом в цикле может быть не очень эффективной (зависит от рализации в конкретном компиляторе/версии), обычно для таких случаев рекомендуют использовать метод , который ведёт себя немного неожиданно:
Во-первых, строка у которой вызывается метод становиться разделителем, а не началом новой строки как можно было бы подумать, а во-вторых, передавать нужно список (итерируемый объект), а не отдельную строку ибо таковая тоже является итерируемым объектом и будет сджойнена посимвольно.
Так как переменные это ссылки, то вполне нормальным является желание сделать копию объекта, чтобы не ломать исходный объект, однако тут есть подводный камень — функция copy копирует только один уровень, что явно не то, что ожидается от функции с таким именем, поэтому используете .
Аналогичная проблема с копированием может возникать при умножении коллекции на скаляр, как разбиралось тут.
How to Create Multithreading in Python3?
import timeimport threadingdef calc_square(number): print("Calculate square numbers: ") for i in numbers: time.sleep(0.2) #artificial time-delay print('square: ', str(n*n))def calc_cude(number): print("Calculate cude numbers: ") for i in numbers: time.sleep(0.2) print('cube: ', str(n*n*n))arr = t = time.time()t1 = threading.Thread(target = cal_square,args=(arr,))t2 = threading.Thread(target = cal_cube,args=(arr,))# creating two threads here t1 & t2t1.start()t2.start()# starting threads here parallelly by usign start function.t1.join()# this will wait until the cal_square() function is finised.t2.join()# this will wait unit the cal_cube() function is finised.print("Successed!")
Why do we need to Use Multi-Processing? How it’s different from Multi-Threading?
Multi-Processing is different programs or processes are running on your computer. The process has there owned virtual memory or an address space now it can create multiple threads inside it.
If the processes have to communicate with each other they use inter-process communication techniques such as a file on the disk a shared memory(Queue) or a message pipe.
Multi-Threading lives within the same process. Threads will share address space they have their own instruction sets, each threads doing the specific tasks and they will be exhibiting their core they have their stack memory but the only thing they share is their space which means if you have global variable define in your program they can be accessed by the threads
What is GIL? Why it’s important?
GIL(Global Interpreter Lock).Python wasn’t designed considering that personal computers might have more than one core (shows you how old the language is), so the GIL is necessary because Python is not thread-safe and there is a globally enforced lock when accessing a Python object. What can we do?
Multiprocessing allows you to create programs that can run concurrently (bypassing the GIL) and use the entirety of your CPU core. The multiprocessing library gives each process its own Python interpreter and each their own GIL.
Because of this, the usual problems associated with threading (such as data corruption and deadlocks) are no longer an issue. Since the processes don’t share a memory, they can’t modify the same memory concurrently.
Methodology
Thread pools are created with 100 threads and process pools are created with 8 processes. The reason for this change in number of workers is because process performance wanes if there are many more processes than processing cores. Threads should behave the same way with almost no regard to their quantity, as long as it remains sane.
We will call an individual runner in the pools a «worker». Workers will run one unit of work at a time. Increasing numbers of tasks will be submitted to each pool and the amount of time the batches take to complete and memory space they use will be recorded. The analysis comes in when seeing how well the pools handle running these tasks and how well they can clean up after finishing some tasks.
The mystery is solved
Here’s why that original program is deadlocking—with their powers combined, the two problems with -only create a bigger, sharkier problem:
- Whenever the thread in the parent process writes a log messages, it adds it to a .
That involves acquiring a lock. - If the happens at the wrong time, the lock is copied in an acquired state.
- The child process copies the parent’s logging configuration—including the queue.
- Whenever the child process writes a log message, it tries to write it to the queue.
- That means acquiring the lock, but the lock is already acquired.
- The child process now waits for the lock to be released.
- The lock will never be released, because the thread that would release it wasn’t copied over by the .
In simplified form:
The «interpreters» Module
The interpreters module will
provide a high-level interface to subinterpreters and wrap a new
low-level _interpreters (in the same way as the threading
module). See the section for concrete usage and use cases.
Along with exposing the existing (in CPython) subinterpreter support,
the module will also provide a mechanism for sharing data between
interpreters. This mechanism centers around «channels», which are
similar to queues and pipes.
Note that objects are not shared between interpreters since they are
tied to the interpreter in which they were created. Instead, the
objects’ data is passed between interpreters. See the
section for more details about sharing between interpreters.
At first only the following types will be supported for sharing:
- None
- bytes
- str
- int
- PEP 554 channels
Multiprocessing Value and Lock
If you have a requirement to maintain and modify a shared variable between the processes, we can make use of the Value object from the module.
Syntax for creating a Value object is,
Commonly used typecodes are,
‘i’ — Integer
’d’ — Float
‘u’ — Unicode String
Let’s simulate an example where in we multiply and divide a number by 10 to finally arrive at the result 1.
Before lock:
As you can see above, the actual result obtained is different from the expected result of 1. This is because both the processes are accessing the same object which leads to a conflict of both processes modifying the value at the same time.
Let’s run the same example with Multiprocessing Lock.
Python Multiprocessing
Parallel processing is getting more attention nowadays. If you still don’t know about the parallel processing, learn from wikipedia.
As CPU manufacturers start adding more and more cores to their processors, creating parallel code is a great way to improve performance. Python introduced multiprocessing module to let us write parallel code.
To understand the main motivation of this module, we have to know some basics about parallel programming. After reading this article, we hope that, you would be able to gather some knowledge on this topic.
Python Multiprocessing Process, Queue and Locks
There are plenty of classes in python multiprocessing module for building a parallel program. Among them, three basic classes are , and . These classes will help you to build a parallel program.
But before describing about those, let us initiate this topic with simple code. To make a parallel program useful, you have to know how many cores are there in you pc. Python Multiprocessing module enables you to know that. The following simple code will print the number of cores in your pc.
The following output may vary for your pc. For me, number of cores is 8.

Python multiprocessing Process class
Python multiprocessing class is an abstraction that sets up another Python process, provides it to run code and a way for the parent application to control execution.
There are two important functions that belongs to the Process class – and function.
At first, we need to write a function, that will be run by the process. Then, we need to instantiate a process object.
If we create a process object, nothing will happen until we tell it to start processing via function. Then, the process will run and return its result. After that we tell the process to complete via function.
Without function call, process will remain idle and won’t terminate.
So if you create many processes and don’t terminate them, you may face scarcity of resources. Then you may need to kill them manually.
One important thing is, if you want to pass any argument through the process you need to use keyword argument. The following code will be helpful to understand the usage of Process class.
The output of the following code will be:
Python multiprocessing Queue class
You have basic knowledge about computer data-structure, you probably know about Queue.
Python Multiprocessing modules provides class that is exactly a First-In-First-Out data structure. They can store any pickle Python object (though simple ones are best) and are extremely useful for sharing data between processes.
Queues are specially useful when passed as a parameter to a Process’ target function to enable the Process to consume data. By using function we can insert data to then queue and using we can get items from queues. See the following code for a quick example.

Python multiprocessing Lock Class
The task of Lock class is quite simple. It allows code to claim lock so that no other process can execute the similar code until the lock has be released. So the task of Lock class is mainly two. One is to claim lock and other is to release the lock. To claim lock the, function is used and to release lock function is used.
Python multiprocessing example
In this Python multiprocessing example, we will merge all our knowledge together.
Suppose we have some tasks to accomplish. To get that task done, we will use several processes. So, we will maintain two queue. One will contain the tasks and the other will contain the log of completed task.
Then we instantiate the processes to complete the task. Note that the python Queue class is already synchronized. That means, we don’t need to use the Lock class to block multiple process to access the same queue object. That’s why, we don’t need to use Lock class in this case.
Below is the implementation where we are adding tasks to the queue, then creating processes and starting them, then using to complete the processes. Finally we are printing the log from the second queue.
Depending on the number of task, the code will take some time to show you the output. The output of the following code will vary from time to time.

Python multiprocessing Pool
Python multiprocessing Pool can be used for parallel execution of a function across multiple input values, distributing the input data across processes (data parallelism). Below is a simple Python multiprocessing Pool example.
Below image shows the output of the above program. Notice that pool size is 2, so two executions of function is happening in parallel. When one of the function processing finishes, it picks the next argument and so on.

So, that’s all for python multiprocessing module.
Reference: Official Documentation






