Работа с файлами ms word в python
Содержание:
- Пример использования всех основных функций
- Python Excel Automation
- Время учиться: дайджест бесплатных образовательных материалов от Mail.Ru Group
- workbook.set_properties()
- Formatting of the Dataframe output
- Эксперименты в песочнице
- How to Read Multiple Excel (xlsx) Files in Python
- Excel + Python
- Должен ли финансист использовать EXCEL?
- Добавление формул
- Основы синтаксиса
- Группирующие скобки (…) и match-объекты в питоне
- 1. Определения и классификация
- Диаграммы
- 2. Синтаксис
Пример использования всех основных функций
Тонкости экранирования в питоне ()
Так как символ в питоновских строках также необходимо экранировать, то в результате в шаблонах могут возникать конструкции вида . Первый слеш означает, что следующий за ним символ нужно оставить «как есть». Третий также. В результате с точки зрения питона означает просто два слеша . Теперь с точки зрения движка регулярных выражений, первый слеш экранирует второй. Тем самым как шаблон для регулярки означает просто текст . Для того, чтобы не было таких нагромождений слешей, перед открывающей кавычкой нужно поставить символ , что скажет питону «не рассматривай \ как экранирующий символ (кроме случаев экранирования открывающей кавычки)». Соответственно можно будет писать .
Использование дополнительных флагов в питоне
| Константа | Её смысл |
|---|---|
| По умолчанию , , , , , , , соответствуют все юникодные символы с соответствующим качеством. Например, соответствуют не только арабские цифры, но и вот такие: ٠١٢٣٤٥٦٧٨٩. ускоряет работу, если все соответствия лежат внутри ASCII. |
|
| Не различать заглавные и маленькие буквы. Работает медленнее, но иногда удобно |
|
| Специальные символы и соответствуют началу и концу каждой строки |
|
| По умолчанию символ конца строки не подходит под точку. С этим флагом точка — вообще любой символ |
Python Excel Automation
If you want to Read, Write and Manipulate(Copy, cut, paste, delete or search for an item etc) Excel files in Python with simple and practical examples I will suggest you to see this simple and to the point
Excel Openpyxl Course with examples about how to deal with MS Excel files in Python. This video course teaches efficiently how to manipulate excel files and automate tasks.
Everything you do in Microsoft Excel, can be automated with Python. So why not use the power of Python and make your life easy. You can make intelligent and thinking Excel sheets, bringing the power of logic and thinking of Python to Excel which is usually static, hence bringing flexibility in Excel and a number of opportunities.
Python excel relationship is flourishing with every day. First I want to ask a simple question:
What
if you get it automated: the task of reading data from excel file and
writing it into a text file, another excel file, an SPSS file, for data analysis or doing
data
analysis with Python Pandas on that data.
Most
of people who work in office usually have to deal with a spreadsheet
software. Ofcourse a spreadsheet is helpful for many purposes. Some of
the common tasks are writing sequential data in spreadsheet, like
writing names of employees, their salaries, and other details.
Sometimes we have to copy a particular data from one file to another
file. Your job might required going through hundreds of excel files,
for searching and sorting data, selecting a particular section of data,
cleaning it, and then presenting it in a different form. Manually done,
it may take days or weeks, but if you know how to deal with excel files
in python, you can write a simple code and all of this tedious boring
stuff will be done in seconds, in a most efficient manner, while you
taking a sip of coffee. Lovely idea, isn’t it? Yes ofcourse. So why not
read this tutorial and learn some valuable skills which help you in the
short run as well as in the long run, making your life less boring,
less hectic and more exiting. More often you dont have to write python
scripts or python code from scratch, it is always in abundance and
freely available, you just modify it according to your needs and thats
it! To take the above mentioned benefits and much much more, stay tuned
to this site and Master the skill of accessing excel with
python.
Python excel relationship is very beneficial for data analysis,
for people who do data mining and those who are involved in machine
learning. Most of the data exists in the form of spreadsheets. Now to
go through thousands or millions of spreadsheets is not an easy task.
And not only going through those files, finding useful data, just by
watching your comupter monitor makes the task troublesome. Data
scientists can use python, and bingo! work done in almost no time, with
much much better efficiency and millions of cells of data from
spreadsheet is read without missing even one cell. Humans can not do
this task to this level of efficiency, or if they would do it will take
so much time that the utility of such data might be outdated. Hence
many Data analysts and data scientists are using python to do their
task and enjoy relaxed time at office and at home with their family. Do
you want to do the same????
If you are ready to make your life easier, read about the
available python packages for excel given below and start with Openpyxl Tutorial,
the most used package with very easy interface and suitable for
beginners dealing with all types of excel spredsheets. This is starting place for python excel world
Время учиться: дайджест бесплатных образовательных материалов от Mail.Ru Group
Кадр из к/ф «Операция Ы и другие приключения Шурика»
Как говорят, «кризис — пора возможностей». И поэтому сейчас самое время начать вкладывать в саморазвитие, осваивать новую профессию или повышать свою квалификацию. Займитесь изучением языков программирования, обретением навыков разработки, тестирования и вообще всячески прокачивайте свой IT-скилл. Ведь чем больше вы знаете, тем прочнее будете стоять на ногах. А чтобы вам было легче сориентироваться и выбрать направление, мы сделали подборку наших бесплатных образовательных материалов, курсов и инициатив за 2015–2016 годы.
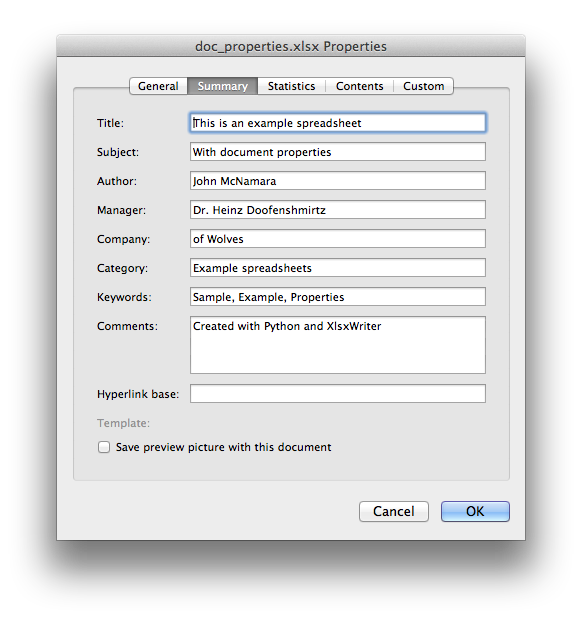
workbook.set_properties()
- (properties)
-
Set the document properties such as Title, Author etc.
Parameters: properties () – Dictionary of document properties.
The method can be used to set the document properties of the
Excel file created by . These properties are visible when you
use the option in Excel and are
also available to external applications that read or index windows files.
The properties that can be set are:
- — the file creation date as a object.
The properties are all optional and should be passed in dictionary format as
follows:
workbook.set_properties({
'title' 'This is an example spreadsheet',
'subject' 'With document properties',
'author' 'John McNamara',
'manager' 'Dr. Heinz Doofenshmirtz',
'company' 'of Wolves',
'category' 'Example spreadsheets',
'keywords' 'Sample, Example, Properties',
'created' datetime.date(2018, 1, 1),
'comments' 'Created with Python and XlsxWriter'})
Formatting of the Dataframe output
XlsxWriter and Pandas provide very little support for formatting the output
data from a dataframe apart from default formatting such as the header and
index cells and any cells that contain dates or datetimes. In addition it
isn’t possible to format any cells that already have a default format applied.
If you require very controlled formatting of the dataframe output then you
would probably be better off using Xlsxwriter directly with raw data taken
from Pandas. However, some formatting options are available.
For example it is possible to set the default date and datetime formats via
the Pandas interface:
writer = pd.ExcelWriter("pandas_datetime.xlsx",
engine='xlsxwriter',
datetime_format='mmm d yyyy hh:mm:ss',
date_format='mmmm dd yyyy')
Which would give:
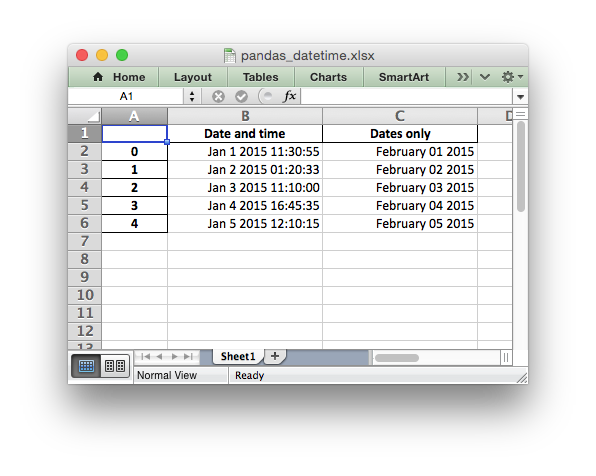
See the full example at .
It is possible to format any other, non date/datetime column data using
:
# Add some cell formats.
format1 = workbook.add_format({'num_format' '#,##0.00'})
format2 = workbook.add_format({'num_format' '0%'})
# Set the column width and format.
worksheet.set_column('B:B', 18, format1)
# Set the format but not the column width.
worksheet.set_column('C:C', None, format2)
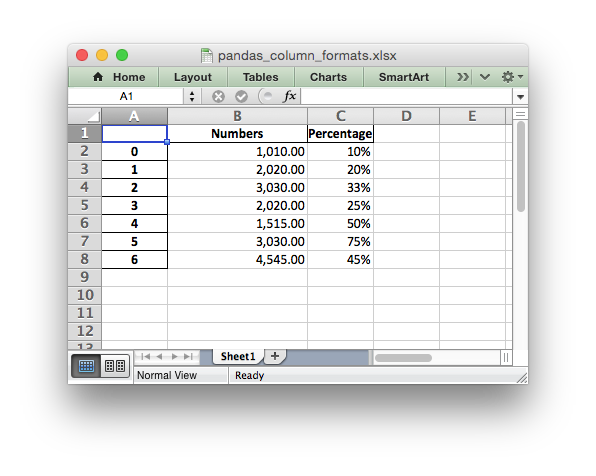
Note: This feature requires Pandas >= 0.16.
Эксперименты в песочнице
- Найдите все натуральные числа (возможно, окружённые буквами);
- Найдите все «слова», написанные капсом (то есть строго заглавными), возможно внутри настоящих слов (аааБББввв);
- Найдите слова, в которых есть русская буква, а когда-нибудь за ней цифра;
- Найдите все слова, начинающиеся с русской или латинской большой буквы ( — граница слова);
- Найдите слова, которые начинаются на гласную ( — граница слова);;
- Найдите все натуральные числа, не находящиеся внутри или на границе слова;
- Найдите строчки, в которых есть символ ( — это точно не конец строки!);
- Найдите строчки, в которых есть открывающая и когда-нибудь потом закрывающая скобки;
- Выделите одним махом весь кусок оглавления (в конце примера, вместе с тегами);
- Выделите одним махом только текстовую часть оглавления, без тегов;
- Найдите пустые строчки;
How to Read Multiple Excel (xlsx) Files in Python
In this section, we will learn how to read multiple xlsx files in Python using openpyxl. Additionally to openpyxl and Path, we are also going to work with the os module.
2. Read all xlsx Files in the Directory to a List
Second, we are going to read all the .xlsx files in a subdirectory into a list. Now, we use the glob module together with Path:
3. Create Workbook Objects (i.e., read the xlsx files)
Third, we can now read all the xlsx files using Python. Again, we will use the load_workbook method. However, this time we will loop through each file we found in the subdirectory,
Now, in the code examples above, we are using Python list comprehension (twice, in both step 2 and 3). First, we create a list of all the xlsx files in the “XLSX_FILES” directory. Second, we loop through this list and create a list of workbooks. Of course, we could add this to the first line of code above.
4. Work with the Imported Excel Files
In the fourth step, we can now work with the imported excel files. For example, we can get the first file by adding “” to the list. If we want to know the sheet names of this file we do like this: .That is, many of the things we can do, and have done in the previous example on reading xlsx files in Python, can be done when we’ve read multiple Excel files.
Excel + Python
Один из первых найденных проектов —PyXLL позволял быстро писать на питоне функции, которые далее можно было использовать наравне со стандартными функциями Excel’я (вроде СУММА()). Я даже попробовал его в действии. Выглядит это так: ты пишешь Python-скрипт в соответствии с некоторыми правилами, реализуя необходимые действия с получаемыми данными, после чего через специальный аддон для Excel’я импортируешь написанные функции. Не так плохо, но хотелось прямо в коде Python обращаться к нужным ячейкам электронной таблицы. И это позволял другой найденный аддон DataNitro. После его установки в Excel’е появляется новая вкладка, откуда вызывается редактор. Интеграция выполнена очень удобно, поэтому можно, не сильно заморачиваясь, написать что-то вроде:
Далее запускаем сценарий с помощью кнопки на панели тулбара и получаем нужное значение в ячейке A1! Недолго думая, я стал наращивать функционал, который мне был нужен. Пробую импортировать библиотеки для работы с нужными форматами и прочитать данные — все работает. Запрашиваю через API информацию из нескольких онлайн-сервисов — все отлично агрегируется. Пишу простенькую приблуду для рассылки отчетов — все отлично отправляется. В итоге за тридцать минут удается сделать скрипт, который будет экономить два часа — те, что превращались для меня в пытку :). Сперва я даже начал выполнять в Python все расчеты, лишь позже вспомнив, что с этим справится сам Excel. Впрочем, если нужно посчитать что-то серьезное, то ничего не стоит подгрузить математический модуль NumPy и делать любые научные вычисления.
Вкладка аддона, с помощью которой реализуется интеграция DataNitro и Excel
Другие статьи в выпуске:
Должен ли финансист использовать EXCEL?
Так как EXCEL уже вошел в культуру финансовой среды, то знания этого инструмента, на мой взгляд, необходимы. Есть ситуации, когда применение EXCEL является оптимальным даже для тех, кто обладает опытом в Python или других языках программирования, ориентированных на анализ данных (например, R). К таким ситуациям относится:
- Анализ небольших объемов финансовых данных (например, когда все данные умещаются на одном экране)
- Ввод небольшого количества данных «руками»
- Использование EXCEL как продвинутой версии калькулятора
- Необходимо поделиться результатом с теми, кто не владеет тем же Python
Можно придумать еще много ситуаций, когда использование EXCEL вполне оправдано. Но в целом они все сводятся к одному сценарию. EXCEL хорош тогда, когда есть не слишком большой объем анализируемой информации, и когда не требуется применять к данным сложные алгоритмы.
Большим преимуществом EXCEL является то, что его можно освоить буквально за несколько часов и пользоваться им уже на приемлемом уровне.
Если вы еще плохо знакомы с EXCEL или совсем его не знаете, можно воспользоваться нашим вводным курсом .
Добавление формул
Формулы, начинающиеся со знака равенства, позволяют устанавливать для ячеек значения, рассчитанные на основе значений в других ячейках.
sheet'B9' = '=SUM(B1:B8)'
Эта инструкция сохранит в качестве значения в ячейке . Тем самым для ячейки задается формула, которая суммирует значения, хранящиеся в ячейках от до .
Формула Excel — это математическое выражение, которое создается для вычисления результата и которое может зависеть от содержимого других ячеек. Формула в ячейке Excel может содержать данные, ссылки на другие ячейки, а также обозначение действий, которые необходимо выполнить.
Использование ссылок на ячейки позволяет пересчитывать результат по формулам, когда происходят изменения содержимого ячеек, включенных в формулы. Формулы Excel начинаются со знака . Скобки могут использоваться для определения порядка математических операции.
Примеры формул Excel: =27+36, =А1+А2-АЗ, =SUM(А1:А5), =MAX(АЗ:А5), =(А1+А2)/АЗ.
Хранящуюся в ячейке формулу можно читать, как любое другое значение. Однако, если нужно получить результат расчета по формуле, а не саму формулу, то при вызове функции ей следует передать именованный аргумент со значением .
Основы синтаксиса
экранировать
Шаблоны, соответствующие одному символу
| Шаблон | Описание | Пример | Применяем к тексту |
|---|---|---|---|
| Один любой символ, кроме новой строки . |
молоко, малако, Им0л0коИхлеб |
||
| Любая цифра | СУ35, СУ111, АЛСУ14 | ||
| Любой символ, кроме цифры | 926)123, 1926-1234 | ||
| Любой пробельный символ (пробел, табуляция, конец строки и т.п.) |
бор ода, бор ода, борода |
||
| Любой непробельный символ | X123, я123, !123456, 1 + 123456 | ||
| Любая буква (то, что может быть частью слова), а также цифры и | Год, f_3, qwert | ||
| Любая не-буква, не-цифра и не подчёркивание | сом!, сом? | ||
| Один из символов в скобках, а также любой символ из диапазона |
12, 1F, 4B | ||
| Любой символ, кроме перечисленных | <1>, <a>, <>> | ||
| Буква “ё” не включается в общий диапазон букв! Вообще говоря, в включается всё, что в юникоде помечено как «цифра», а в — как буква. Ещё много всего! |
|||
| если нужен минус, его нужно указать последним или первым | |||
| внутри скобок нужно экранировать только и | |||
| Начало или конец слова (слева пусто или не-буква, справа буква и наоборот). В отличие от предыдущих соответствует позиции, а не символу |
вал, перевал, Перевалка | ||
| Не граница слова: либо и слева, и справа буквы, либо и слева, и справа НЕ буквы |
перевал, вал, Перевалка | ||
| перевал, вал, Перевалка |
Квантификаторы (указание количества повторений)
| Шаблон | Описание | Пример | Применяем к тексту |
|---|---|---|---|
| Ровно n повторений | 1, 12, 123, 1234, 12345 | ||
| От m до n повторений включительно | 1, 12, 123, 1234, 12345 | ||
| Не менее m повторений | 1, 12, 123, 1234, 12345 | ||
| Не более n повторений | 1, 12, 123 | ||
| Ноль или одно вхождение, синоним | вал, валы, валов | ||
| Ноль или более, синоним | СУ, СУ1, СУ12, … | ||
| Одно или более, синоним | a), a)), a))), ba)]) | ||
| По умолчанию квантификаторы жадные — захватывают максимально возможное число символов. Добавление делает их ленивыми, они захватывают минимально возможное число символов |
(a + b) * (c + d) * (e + f)(a + b) * (c + d) * (e + f) |
Жадность в регулярках и границы найденного шаблона
Как указано выше, по умолчанию квантификаторы жадные. Этот подход решает очень важную проблему — проблему границы шаблона. Скажем, шаблон захватывает максимально возможное количество цифр. Поэтому можно быть уверенным, что перед найденным шаблоном идёт не цифра, и после идёт не цифра. Однако если в шаблоне есть не жадные части (например, явный текст), то подстрока может быть найдена неудачно. Например, если мы хотим найти «слова», начинающиеся на , после которой идут цифры, при помощи регулярки , то мы найдём и неправильные шаблоны:
Группирующие скобки (…) и match-объекты в питоне
Match-объекты
| Метод | Описание | Пример |
|---|---|---|
| , | Подстрока, соответствующая шаблону | |
| Индекс в исходной строке, начиная с которого идёт найденная подстрока | ||
| Индекс в исходной строке, который следует сразу за найденной подстрока |
Группирующие скобки
Если в шаблоне регулярного выражения встречаются скобки без , то они становятся группирующими. В match-объекте, который возвращают , и , по каждой такой группе можно получить ту же информацию, что и по всему шаблону. А именно часть подстроки, которая соответствует , а также индексы начала и окончания в исходной строке. Достаточно часто это бывает полезно.
Тонкости со скобками и нумерацией групп.
Если к группирующим скобкам применён квантификатор (то есть указано число повторений), то подгруппа в match-объекте будет создана только для последнего соответствия. Например, если бы в примере выше квантификаторы были снаружи от скобок , то вывод был бы таким:
Внутри группирующих скобок могут быть и другие группирующие скобки. В этом случае их нумерация производится в соответствии с номером появления открывающей скобки с шаблоне.
Группы и
Если в шаблоне есть группирующие скобки, то вместо списка найденных подстрок будет возвращён список кортежей, в каждом из которых только соответствие каждой группе. Это не всегда происходит по плану, поэтому обычно нужно использовать негруппирующие скобки .
Группы и
Если в шаблоне нет группирующих скобок, то работает очень похожим образом на . А вот если группирующие скобки в шаблоне есть, то между каждыми разрезанными строками будут все соответствия каждой из подгрупп.
1. Определения и классификация
1.1 Что и зачем
- Генераторы выражений предназначены для компактного и удобного способа генерации коллекций элементов, а также преобразования одного типа коллекций в другой.
- В процессе генерации или преобразования возможно применение условий и модификация элементов.
- Генераторы выражений являются синтаксическим сахаром и не решают задач, которые нельзя было бы решить без их использования.
1.2 Преимущества использования генераторов выражений
- Более короткий и удобный синтаксис, чем генерация в обычном цикле.
- Более понятный и читаемый синтаксис чем функциональный аналог сочетающий одновременное применение функций map(), filter() и lambda.
- В целом: быстрее набирать, легче читать, особенно когда подобных операций много в коде.
1.3 Классификация и особенности
- выражение-генератор (generator expression) — выражение в круглых скобках которое выдает создает на каждой итерации новый элемент по правилам.
- генератор коллекции — обобщенное название для генератора списка (list comprehension), генератора словаря (dictionary comprehension) и генератора множества (set comprehension).
Диаграммы
Модуль OpenPyXL поддерживает создание гистогорамм, графиков, а также точечных и круговых диаграмм с использование данных, хранящихся в электронной таблице. Чтобы создать диаграмму, необходимо выполнить следующие действия:
- создать объект на основе ячеек в пределах выделенной прямоугольной области;
- создать объект , передав функции объект ;
- создать объект Chart;
- дополнительно можно установить значения переменных , , , объекта , определяющих положение и размеры диаграммы;
- добавить объект в объект .
Объекты создаются путем вызова функции , принимающей пять аргуменов:
- Объект , содержащий данные диаграммы.
- Два целых числа, представляющих верхнюю левую ячейку выделенной прямоугольной области, в которых содержатся данные диаграммы: первое число задает строку, второе — столбец; первой строке соответствует 1, а не 0.
- Два целых числа, представляющих нижнюю правую ячейку выделенной прямоугольной области, в которых содержатся данные диаграммы: первое число задает строку, второе — столбец.
from openpyxl import Workbook
from openpyxl.chart import BarChart, Reference
# создаем новый excel-файл
wb = Workbook()
# добавляем новый лист
wb.create_sheet(title = 'Первый лист', index = )
# получаем лист, с которым будем работать
sheet = wb'Первый лист'
sheet'A1' = 'Серия 1'
# это колонка с данными
for i in range(1, 11)
cell = sheet.cell(row = i + 1, column = 1)
cell.value = i * i
# создаем диаграмму
chart = BarChart()
chart.title = 'Первая серия данных'
data = Reference(sheet, min_col = 1, min_row = 1, max_col = 1, max_row = 11)
chart.add_data(data, titles_from_data = True)
# добавляем диаграмму на лист
sheet.add_chart(chart, 'C2')
# записываем файл
wb.save('example.xlsx')
Аналогично можно создавать графики, точечные и круговые диаграммы, вызывая методы:
Поиск:
Excel • MS • Python • Web-разработка • Модуль
2. Синтаксис
Важно
Общие принципы важные для понимания:
- Ввод — это итератор — это может быть функция-генератор, выражение-генератор, коллекция — любой объект поддерживающий итерацию по нему.
- Условие — это фильтр при выполнении которого элемент пойдет в финальное выражение, если элемент ему не удовлетворяет, он будет пропущен.
- Финальное выражение — преобразование каждого выбранного элемента перед его выводом или просто вывод без изменений.
несколько условий, комбинируя их логическими операторами
2.4 Ветвление выражения
Обратите внимание:if-else для ветвления финального выражения
- Условия ветвления пишутся не после, а перед итератором.
- В данном случае if-else это не фильтр перед выполнением выражения, а ветвление самого выражения, то есть переменная уже прошла фильтр, но в зависимости от условия может быть обработана по-разному!
комбинировать фильтрацию и ветвление






