Полнотекстовый поиск
Содержание:
Селективность индексов
Вернемся к запросу:
Для такого запроса необходимо создать составной индекс. Но как правильно выбрать последовательность колонок в индексе? Варианта два:
- age, gender
- gender, age
Подойдут оба. Но работать они будут с разной эффективностью.
Чтобы понять это, рассмотрим уникальность значений каждой колонки и количество соответствующих записей в таблице:
mysql> select age, count(*) from users group by age; +------+----------+ | age | count(*) | +------+----------+ | 15 | 160 | | 16 | 250 | | ... | | 76 | 210 | | 85 | 230 | +------+----------+ 68 rows in set (0.00 sec) mysql> select gender, count(*) from users group by gender; +--------+----------+ | gender | count(*) | +--------+----------+ | female | 8740 | | male | 4500 | +--------+----------+ 2 rows in set (0.00 sec)
Эта информация говорит нам вот о чем:
- Любое значение колонки age обычно содержит около 200 записей.
- Любое значение колонки gender — около 6000 записей.
Если колонка age будет идти первой в индексе, тогда MySQL после первой части индекса сократит количество записей до 200. Останется сделать выборку по ним. Если же колонка gender будет идти первой, то количество записей будет сокращено до 6000 после первой части индекса. Т.е. на порядок больше, чем в случае age.
Это значит, что индекс age_gender будет работать лучше, чем gender_age.
Селективность колонки определяется количеством записей в таблице с одинаковыми значениями. Когда записей с одинаковым значением мало — селективность высокая. Такие колонки необходимо использовать первыми в составных индексах.
Устройство полнотекстового индекса
Все технологии полнотекстового поиска работают по одному принципу. На основе текстовых данных строится индекс, который способен очень быстро искать соответствия по ключевым словам.
Обычно сервис поиска состоит из двух компонент. Поисковик и индексатор.
Индексатор получает текст на вход, делает обработку текста (вырезание окончаний, незначимых слов и т.п.) и сохраняет все в индексе. Устройство такого индекса позволяет проводить по нему очень быстрый поиск.
 Поисковик — интерфейс поиска по индексу — принимает от клиента запрос, обрабатывает фразу и ищет ее в индексе.
Поисковик — интерфейс поиска по индексу — принимает от клиента запрос, обрабатывает фразу и ищет ее в индексе.

Существует несколько популярных технологий для реализации полнотекстового поиска в приложениях.
Варианты хранения
Начиная с версии SQL Server 2008, существует два разных варианта хранения, каждый из которых позволяет сохранять объекты LOB и экономить дисковое пространство. Это следующие варианты:
-
хранение данных типа FILESTREAM;
-
хранение с использованием разреженных столбцов (sparse columns).
Эти варианты хранения рассматриваются в следующих подразделах.
Хранение данных типа FILESTREAM
Как уже упоминалось ранее, SQL Server поддерживает хранение больших объектов (LOB) посредством типа данных VARBINARY(MAX). Свойство этого типа данных таково, что большие двоичные объекты (BLOB) сохраняются в базе данных. Это обстоятельство может вызвать проблемы с производительностью в случае хранения очень больших файлов, таких как аудио- или видеофайлов. В таких случаях эти данные сохраняются вне базы данных во внешних файлах.
Хранение данных типа FILESTREAM поддерживает управление объектами LOB, которые сохраняются в файловой системе NTFS. Основным преимуществом этого типа хранения является то, что хотя данные хранятся вне базы данных, управляются они базой данных. Таким образом, этот тип хранения имеет следующие свойства:
-
данные типа FILESTREAM можно сохранять с помощью инструкции CREATE TABLE, а для работы с этими данными можно использовать инструкции для модифицирования данных (SELECT, INSERT, UPDATE и DELETE);
-
система управления базой данных обеспечивает такой же самый уровень безопасности для данных типа FILESTREAM, как и для данных, хранящихся внутри базы данных.
Разреженные столбцы (sparse columns)
Цель варианта хранения, предоставляемого разреженными столбцами, значительно отличается от цели хранения типа FILESTREAM. Тогда как целью хранения типа FILESTREAM является хранение объектов LOB вне базы данных, целью разреженных столбцов является минимизировать дисковое пространство, занимаемое базой данных.
Столбцы этого типа позволяют оптимизировать хранение столбцов, большинство значений которых равны null. При использовании разреженных столбцов для хранения значений null дисковое пространство не требуется, но, с другой стороны, для хранения значений, отличных от null, требуется дополнительно от 2 до 4 байтов, в зависимости от их типа. По этой причине разработчики Microsoft рекомендуют использовать разреженные столбцы только в тех случаях, когда ожидается, по крайней мере, 20% общей экономии дискового пространства.
Разреженные столбцы определяются таким же образом, как и прочие столбцы таблицы; аналогично осуществляется и обращение к ним. Это означает, что для обращения к разреженным столбцам можно использовать инструкции SELECT, INSERT, UPDATE и DELETE таким же образом, как и при обращении к обычным столбцам. Единственная разница касается создания разреженных столбцов: для определения конкретного столбца разреженным применяется аргумент SPARSE после названия столбца, как это показано в данном примере:
имя_столбца тип_данных SPARSE
Несколько разреженных столбцов таблицы можно сгруппировать в набор столбцов. Такой набор будет альтернативным способом сохранять значения во всех разреженных столбцах таблицы и обращаться к ним.
Solr

Solr — не просто поисковый индекс, а еще и хранилище документов. Т.е. в отличие от Sphinx’a, документы сохраняются целиком и их не нужно дублировать в базу данных.
Решение Java-based, поэтому понадобится JVM и сам Solr. Из пакетов можно поставить все вместе:
apt-get install solr-jetty
Либо просто скачать Solr и запустить его:
wget http://apache.cp.if.ua/lucene/solr/5.3.1/solr-5.3.1.tgz tar -xvf solr-5.3.1.tgz cd solr-5.3.1 bin/solr start
После этого сервис станет доступен на порту 8983:
http://127.0.0.1:8983/
Solr работает по текстовому HTTP протоколу. Сразу после установки можно отправлять данные в индекс. Индекс — это что-то вроде таблицы в MySQL, для ее создания нужно выполнить команду:
bin/solr create -c shop
Чтобы добавить документ в индекс, достаточно отправить такой запрос.
curl http://localhost:8983/solr/shop/update -d ' '
Теперь можно сделать выборку документа по ID:
curl http://localhost:8983/solr/shop/get?id=1
Чтобы стала доступной возможность поиска по индексу, необходимо запустить перестроение индекса:
curl http://localhost:8983/solr/shop/update?commit=true
После этого можно искать по тексту:
curl http://localhost:8983/solr/demo/query -d 'q=author_t:Den'
Получим что-то типа этого:
Solr поддерживает масштабирование в кластер, поэтому это решение подойдет для очень больших объемов данных и нагрузок. Кроме обычного текстового поиска этот поисковик может находить неточные соответствия (например, при поиске слов с ошибками).
Overhead
Важно помнить, что индексы предполагают дополнительные операции записи на диск. При каждом обновлении или добавлении данных в таблицу, происходит также запись и обновление данных в индексе

Создавайте только необходимые индексы, чтобы не расходовать зря ресурсы сервера. Контролируйте размеры индексов для Ваших таблиц:
mysql> show table status; +-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+ | Name | Engine | Version | Row_format | Rows | Avg_row_length | Data_length | Max_data_length | Index_length | Data_free | Auto_increment | Create_time | Update_time | Check_time | Collation | Checksum | Create_options | Comment | +-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+ ... | users | InnoDB | 10 | Compact | 314 | 208 | 65536 | 0 | 16384 | 0 | 355 | 2014-07-11 01:12:17 | NULL | NULL | utf8_general_ci | NULL | | | +-------------------+--------+---------+------------+--------+----------------+-------------+-----------------+--------------+-----------+----------------+---------------------+-------------+------------+-----------------+----------+----------------+---------+ 18 rows in set (0.06 sec)
Phần cuối: Mở rộng
- Lỡ tìm hiểu về đánh index đặc biệt là fulltext rồi chẳng nhẽ ta không đi tiếp đến đánh index bình thường?
- Đó là đánh index kiểu B-tree, về định nghĩa thì nghe hơi loằng ngoằng thế này
.
Bạn có thể xem qua ảnh gif mà mình sưu tầm được, nó rất là hay.
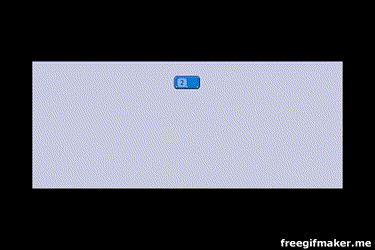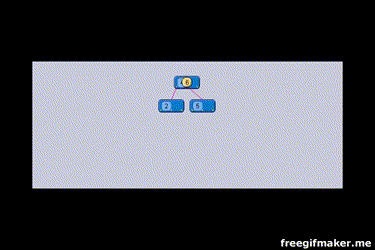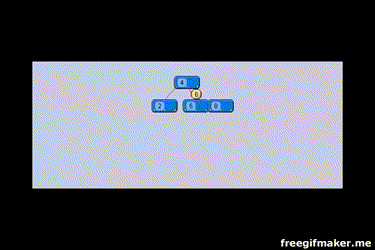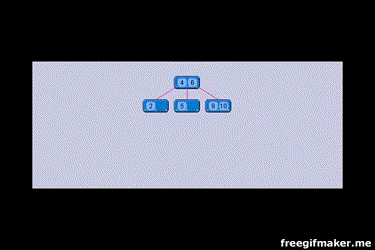
Cách đánh index như sau
và sau đó cũng sử dụng để kiểm tra và ta được kết quả sau.
Giờ ta sẽ lại so sánh với câu search like lúc ban đầu và so sánh về tốc độ cũng như hiệu năng của câu lệnh sau khi được đánh index.

Hiệu năng

Chú ý :
- Các chỉ mục không nên được sử dụng trong các bảng nhỏ.
- Các chỉ mục không nên được sử dụng trên các cột mà chứa một số lượng lớn giá trị NULL.
- Không nên dùng chỉ mục trên các cột mà thường xuyên bị sửa đổi (Insert, Update…)
Типы данных
Для полнотекстового поиска в PostgreSQL предусмотрены специальные типы данных: tsvector и tsquery.
Тип tsvector — представляет документ в виде оптимизированном для текстового поиска. По сути это нормализованная строка по которой будет производиться поиск.
Под нормализацией следует понимать такие процедуры как выкидывание стоп-слов, вырезание окончаний слов, приведение к нижнему регистру и т.д.
Для нормализации строки используется процедура to_tsvector.
Например так будет выглядеть нормализованная строка:
SELECT to_tsvector('I find the system really useful');
'find':2 'realli':5 'system':4 'use':6
Тип tsquery — используется для представления запросов поиска. Для преобразования поисковых запросов используется процедура plainto_tsquery:
SELECT plainto_tsquery('help us to save Jupiter');
'help' & 'us' & 'save' & 'jupit'
Ранжирование результатов поиска
Оценка релевантности документа относительно запроса происходит с учетом весов элементов tsvector.
Для установки весов предусмотрена функция setweight, значения задаются буквами A B C D.
Например установим важность слов в заголовке больше чем в теле документа. Тогда наш запрос будет выглядеть так:
SELECT * FROM news WHERE setweight(to_tsvector(title), 'A') ||
setweight(to_tsvector(content), 'B') @@ plainto_tsquery('user search text')
ORDER BY ts_rank(setweight(to_tsvector(title), 'A') ||
setweight(to_tsvector(content), 'B'), plainto_tsquery('user search text')) DESC;
Функция ts_rank ранжирует результаты по частоте найденных лексем.
2: Создание индекса полнотекстового поиска
Создайте индекс для текстовых столбцов, чтобы затем выполнить полнотекстовый поиск.
Для этого нужно использовать специальную команду MySQL, FULLTEXT. Эта команда позволяет выполнять полнотекстовый поиск по заданным полям.
Команда объединяет все текстовые столбцы и фильтрует их (например, удаляет пунктуацию и преобразовывает прописные буквы в нижний регистр). Полученный индекс будет обновляться любым SQL-запросом, который изменяет содержимое исходной таблицы.
Теперь попробуйте выполнить полнотекстовый поиск по запросу «Seattle beach» с помощью функции MATCH() AGAINST().
Часть команды MATCH() указывает, какой набор столбцов индексируется с помощью полнотекстового поиска; здесь нужно указать список столбцов, который использовался для создания индекса. Часть AGAINST() указывает, какое слово применяется для полнотекстового поиска (в данном примере это Seattle beach).
IN NATURAL LANGUAGE MODE включает режим, при котором слова для поиска поступают непосредственно из пользовательского ввода без предварительной обработки. MySQL по умолчанию использует этот режим, поэтому явно указывать его не нужно.
Примечание: word stemming – еще один полезный метод полнотекстового поиска, который сохраняет только корневую часть слова. Например, слова «подходит» и «подойти» были бы идентичными в этом режиме. К сожалению, MySQL не поддерживает режим word stemming. Stemming есть в рабочем логе MySQL, но пока что нет возможности реализовать его. Тем не менее, полнотекстовый поиск по-прежнему полезен, потому что он намного быстрее, чем LIKE. Если вы хотите использовать word stemming, вы можете интегрировать библиотеку Snowball.
\G в конце вышеприведенного запроса выводит каждый столбец с новой строки. Благодаря этому большие результаты немного легче читать. Предыдущая команда вернет такой результат:
Как видите, в таблице не нашлось записей, содержащих запрос «Seattle beach». Но полнотекстовый поиск обнаруживает два результата: в первой строке содержится только слово «Seattle», а во второй содержится только слово «beach». Вы можете попробовать создать дополнительные запросы, изменив ключевые слова.
Теперь вы можете использовать функции полнотекстового поиска в SQL-запросах и находить строки.
Когда создавать индексы?
- Индексы следует создавать по мере обнаружения медленных запросов. В этом поможет slow log в MySQL. Запросы, которые выполняются более 1 секунды являются первыми кандидатами на оптимизацию.
- Начинайте создание индексов с самых частых запросов. Запрос, выполняющийся секунду, но 1000 раз в день наносит больше ущерба, чем 10-секундный запрос, который выполняется несколько раз в день.
- Не создавайте индексы на таблицах, число записей в которых меньше нескольких тысяч. Для таких размеров выигрыш от использования индекса будет почти незаметен.
- Не создавайте индексы заранее, например, в среде разработки. Индексы должны устанавливаться исключительно под форму и тип нагрузки работающей системы.
- Удаляйте неиспользуемые индексы.
Самое важное
Для поиска по тексту следует использовать указанные инструменты, т.к. обычные базы данных весьма ограничены и неэффективны в этом вопросе. Короткая сводка поможет выбрать подходящее решение:
- Sphinx. Простой, быстрый, легкий, используется в связке с базовый данных, поиск по русскому/английскому тексту, wildcard поиск.
- Solr. Большой, мощный, выступает как хранилище, миллион функций, сделать можно практически все, есть неточный поиск и возможность масштабироваться из коробке.
- Elastic. Не только поиск и хранилище, а и другие инструменты (визуализация, сборщик логов, система шифрования и т.п.). Умеет масштабироваться и позволяет выполнять выборки очень сложной формы, что делает это хорошим вариантов для аналитической платформы.
Целые числа
Для всех числовых колонок обязательно рассчитайте максимальное значение. В Mysql существует 4 целочисленных типа:
- TINYINT: 8 бит, максимум 127
- SMALLINT: 16 бит, максимум 32 676
- INT: 32 бит, максимум 2 x 109
- BIGINT: 64 бит, максимум 9 x 1018
Представьте, что вы используете тип INT для колонки, в которой хранится возраст пользователя. Тогда, как вам достаточно типа TINYINT, вы используете на 32 — 8 = 24 бита больше. Для каждой строки. Если у Вас 10 тыс. пользователей, вы зря расходуете: 24/8 * 10 000 = 30 Кб. Если пользователей 10 млн, то 30 Мб.
Это может быть не так много для диска, зато критично для оперативной памяти.
UNSIGNED
Если отрицательное число неактуально для колонки, используйте UNSIGNED значения. Тогда максимально значение будет в два раза больше, однако минимальным будет ноль:
- UNSIGNED TINYINT: 8 бит, максимум 255
- UNSIGNED SMALLINT: 16 бит, максимум 65 535
- UNSIGNED INT: 32 бит, максимум 4 x 109
- UNSIGNED BIGINT: 64 бит, максимум 18 x 1018
Длинна числовых типов
В Mysql можно указать длину колонки после указания числового типа:
Это не имеет никакого влияния ни на размер колонки ни на максимальное число. Просто никогда не используйте длину для числовых типов.
Создание индексов
Для полнотекстового поиска более предпочтительным является индекс GIN (Generalized Inverted Index).
Он содержит записи всех ключей (лексем) со списком мест их вхождений.
Индекс GIN для поиска ключей использует бинарное дерево, поэтому он слабо зависит от количества ключей и хорошо масштабируется.
Создаем индекс:
CREATE INDEX search_index news USING GIN(setweight(to_tsvector('title'), 'A')
|| setweight(to_tsvector(content), 'B'));
Но будьте осторожны и не используйте индекс GIN для документов которые постоянно изменяются. Так как изменения приводят к большому количеству обновлений индекса.
Использование EXPLAIN для анализа индексов
Инструкция EXPLAIN покажет данные об использовании индексов для конкретного запроса. Например:
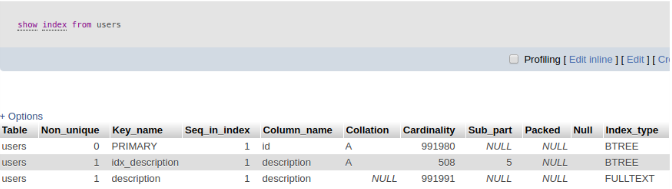
mysql> EXPLAIN SELECT * FROM users WHERE email = 'golotyuk@gmail.com'; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | users | ALL | NULL | NULL | NULL | NULL | 336 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+
Колонка key показывает используемый индекс. Колонка possible_keys показывает все индексы, которые могут быть использованы для этого запроса. Колонка rows показывает число записей, которые пришлось прочитать базе данных для выполнения этого запроса (в таблице всего 336 записей).
Как видим, в примере не используется ни один индекс. После создания индекса:
mysql> EXPLAIN SELECT * FROM users WHERE email = 'golotyuk@gmail.com'; +----+-------------+-------+-------+---------------+-------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+-------+---------+-------+------+-------+ | 1 | SIMPLE | users | const | email | email | 386 | const | 1 | | +----+-------------+-------+-------+---------------+-------+---------+-------+------+-------+
Прочитана всего одна запись, т.к. был использован индекс.
Проверка длинны составных индексов
Explain также поможет определить правильность использования составного индекса. Проверим запрос из примера (с индексом на колонки age и gender):
mysql> EXPLAIN SELECT * FROM users WHERE age = 29 AND gender = 'male'; +----+-------------+--------+------+---------------+------------+---------+-------------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+------------+---------+-------------+------+-------------+ | 1 | SIMPLE | users | ref | age_gender | age_gender | 24 | const,const | 1 | Using where | +----+-------------+--------+------+---------------+------------+---------+-------------+------+-------------+
Значение key_len показывает используемую длину индекса. В нашем случае 24 байта — длинна всего индекса (5 байт age + 19 байт gender).
Если мы выполним изменим точное сравнение на поиск по диапазону, увидим что MySQL использует только часть индекса:
mysql> EXPLAIN SELECT * FROM users WHERE age <= 29 AND gender = 'male'; +----+-------------+--------+------+---------------+------------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+------+---------------+------------+---------+------+------+-------------+ | 1 | SIMPLE | users | ref | age_gender | age_gender | 5 | | 82 | Using where | +----+-------------+--------+------+---------------+------------+---------+------+------+-------------+
Это сигнал о том, что созданный индекс не подходит для этого запроса. Если же мы создадим правильный индекс:
mysql> Create index gender_age on users(gender, age); mysql> EXPLAIN SELECT * FROM users WHERE age < 29 and gender = 'male'; +----+-------------+--------+-------+-----------------------+------------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+--------+-------+-----------------------+------------+---------+------+------+-------------+ | 1 | SIMPLE | users | range | age_gender,gender_age | gender_age | 24 | NULL | 47 | Using where | +----+-------------+--------+-------+-----------------------+------------+---------+------+------+-------------+
В этом случае MySQL использует весь индекс gender_age, т.к. порядок колонок в нем позволяет сделать эту выборку.
Solr
Solr — не просто поисковый индекс, а еще и хранилище документов. Т.е. в отличие от Sphinx’a, документы сохраняются целиком и их не нужно дублировать в базу данных.
Решение Java-based, поэтому понадобится JVM и сам Solr. Из пакетов можно поставить все вместе:
apt-get install solr-jetty
Либо просто скачать Solr и запустить его:
wget http://apache.cp.if.ua/lucene/solr/5.3.1/solr-5.3.1.tgz tar -xvf solr-5.3.1.tgz cd solr-5.3.1 bin/solr start
После этого сервис станет доступен на порту 8983:
http://127.0.0.1:8983/
Solr работает по текстовому HTTP протоколу. Сразу после установки можно отправлять данные в индекс. Индекс — это что-то вроде таблицы в MySQL, для ее создания нужно выполнить команду:
bin/solr create -c shop
Чтобы добавить документ в индекс, достаточно отправить такой запрос.
curl http://localhost:8983/solr/shop/update -d ' '
Теперь можно сделать выборку документа по ID:
curl http://localhost:8983/solr/shop/get?id=1
Чтобы стала доступной возможность поиска по индексу, необходимо запустить перестроение индекса:
curl http://localhost:8983/solr/shop/update?commit=true
После этого можно искать по тексту:
curl http://localhost:8983/solr/demo/query -d 'q=author_t:Den'
Получим что-то типа этого:
Solr поддерживает масштабирование в кластер, поэтому это решение подойдет для очень больших объемов данных и нагрузок. Кроме обычного текстового поиска этот поисковик может находить неточные соответствия (например, при поиске слов с ошибками).
Elastic

Elasticsearch — целая инфраструктура для работы с данными, в том числе полнотекстовым поиском. Построен на основе Apache Lucene.
Установка из кастомного репозитория Debian:
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - echo "deb http://packages.elastic.co/elasticsearch/1.4/debian stable main" | sudo tee -a /etc/apt/sources.list apt-get update && apt-get install elasticsearch update-rc.d elasticsearch defaults 95 10 /etc/init.d/elasticsearch restart
После запуска (может занять несколько секунд) нужно проверить доступность:
curl localhost:9200
Индексы (таблицы) создаются автоматически при индексации, а сам индексатор работает в режиме реального времени. Поэтому для добавления документа в индекс нужно сделать только один вызов:
curl -XPUT "http://localhost:9200/shop/products/1" -d'
{
"title": "Elastic",
"description": "Better than Solr"
}'
Чтобы получить документ по id достаточно сделать такой вызов:
curl -XGET "http://localhost:9200/shop/products/1"
Для поиска документов по тексту:
curl -XPOST "http://localhost:9200/shop/products/_search" -d'
{
"query": {
"query_string": {
"query": "Better"
}
}
}'
Elastic имеет мега продвинутую систему хранения данных и протокол запросов. Поэтому во многих случаях его применяют, как движок для Ad-hoc запросов.
Sphinx

Супер простое решение, которое подойдет для большинства случаев. По умолчанию поддерживает английский и русский язык. Имеет интерфейс для индексирования таблиц MySQL. Чтобы начать использовать Sphinx достаточно установить его из пакетов, настроить источник данных и запустить индексатор в cron задачу.
Конфигурация делится на source и index для определения источника данных и параметров индекса:
После этого достаточно запустить индексатор в cron, например для переиндексации каждые 5 минут:
В таком режиме максимальная задержка до появления данных в поиске будет составлять 5 минут.
Sphinx поддерживает обычный MySQL протокол для поиска, поэтому чтобы найти в индексе какой-то текст достаточно подключиться к порту 9306 и отправить обычный MySQL запрос:
Например, в PHP:
При больших объемах можно использовать схему Delta индексов для ускорения индексации. Кроме этого, Sphinx поддерживает Real Time индексы, фильтрацию и сортировку результатов поиска и поиск по wildcard условиям.
Чтение данных с диска
На жестком диске нет такого понятия, как файл. Есть понятие блок. Один файл обычно занимает несколько блоков. Каждый блок знает, какой блок идет после него. Файл делится на куски и каждый кусок сохраняется в пустой блок.

При чтении файла, мы по очереди проходимся по всем блокам и собираем файл из кусков. Блоки одного файла могут быть раскиданы по диску (фрагментация). Тогда чтение файла замедлится, т.к. понадобится прыгать разным участкам диска.
Когда мы ищем что-то внутри файла, нам понадобится пройтись по всем блокам, в которых он сохранен. Если файл очень большой, то и количество блоков будет значительным. Необходимость перепрыгивать с блока на блок, которые могут находиться в разных местах, сильно замедлит поиск данных.
Чтение записей¶
Другая частая операция при работе с базами данных в PHP — это получение записей из таблиц (запросы типа ).
Составим SQL-запрос, который будет использовать выражение. Затем выполним этот запрос с помощью функции , чтобы получить данные из таблицы.
В этом примере показано, как вывести все существующие города из таблицы :
В примере выше результат выполнения функции сохранён в переменной .
Важно понимать, что в этой переменной находятся не данные из таблицы, а специальный тип данных — так называемая ссылка на результаты запроса. Чтобы получить действительные данные, то есть записи из таблицы, следует использовать другую функцию — — и передать ей единственным параметром эту самую ссылку
Чтобы получить действительные данные, то есть записи из таблицы, следует использовать другую функцию — — и передать ей единственным параметром эту самую ссылку.
Теперь каждый вызов функции будет возвращать следующую запись из всего результирующего набора записей в виде ассоциативного массива.
Цикл здесь используется для «прохода» по всем записям из полученного набора записей.
Значение поля каждой записи можно узнать просто обратившись по ключу этого ассоциативного массива.
Как получить сразу все записи в виде двумерного массива
Иногда бывает удобно после запроса на чтение не вызывать в цикле для извлечения очередной записи по порядку, а получить их сразу все одним вызовом. PHP так тоже умеет. Функция вернёт двумерный массив со всеми записями из результата последнего запроса.
Перепишем пример с показом существующих городов с её использованием:
Как узнать количество записей
Часто бывает необходимо узнать, сколько всего записей вернёт выполненный SQL запрос.
Это может помочь при организации постраничной навигации, или просто в качестве информации.
Узнать число записей поможет функция , которой следует передать ссылку на результат запроса.
Основные возможности полнотекстового поиска
- Поддержка транслитерации (написание русских слов символами латиницы в соответствии с ГОСТ);
- Поддержка замещения (написание части символов в русских словах одноклавишными латинскими символами);
- Возможность нечеткого поиска (буквы в найденных словах могут отличаться) с указанием порога нечеткости;
- Возможность указания области выполнения поиска по выбранным объектам конфигурации;
- Представление результатов поиска в формате XML и HTML с выделением найденных слов;
- Полнотекстовое индексирование названий стандартных полей («Код», «Наименование» и т. д.) на всех языках конфигурации;
- Выполнение поиска с учетом синонимов русского, английского и украинского языков;
- Поиск по значащим частям слов. Эта возможность реализована за счет разделения слов на значащие части во время индексирования. В результате, например, при поиске «хлеб» будет подсвечено слово «Мосхлеб», т. к. в нем «хлеб» является значащей частью;
- Возможность добавления собственных словарей значащих частей;
- Морфологический словарь русского языка содержит ряд специфических слов, относящихся к областям деятельности, автоматизируемым с помощью системы программ 1С:Предприятие;
- Возможность использования дополнительных словарей полнотекстового поиска;
- В состав поставляемых словарей включены словарные базы и словари тезауруса и синонимов русского, украинского и английского языков, предоставленные компанией «Информатик».
II. MySQL Fulltext Search
- là kĩ thuật tìm kiếm toàn văn cho phép người dùng tìm kiếm các mẩu thông tin khớp với một chuỗi trên một hay một số cột nhất định
- Một chỉ mục toàn văn trong MySQL là một chỉ mục có kiểu FULLTEXT. Các chỉ mục FULLTEXT chỉ được dùng với các bảng có thể được tạo ra từ các cột CHAR, VARCHAR, hay TEXT.
- Sử dụng cơ chế ranking (ranking dựa trên mức độ phù hợp của kết tài liệu tìm thấy, tài liệu trả về càng phù hợp thì có số rank càng cao)
2.1 Inverted Index
Điều làm nên sự khác biệt giữa FTS và các kĩ thuật search thông thường chính là Inverted index.
- là kĩ thuật đánh index theo đơn vị term
- nhằm mục đich map giữa các term với các bản ghi chưa term đó.
- Vậy việc tạo index theo term như trên có lợi thế nào?
Hãy giả sử bạn muốn query cụm từ «Son, is, Developer», thì thay vì việc phải scan từng document một, bài toán tìm kiếm document chứa 3 term trên sẽ trở thành phép toán union của 3 tập hợp
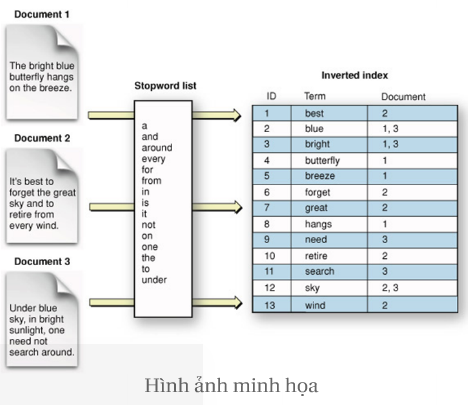
Ví dụ:
D1 = «Son is Developer»
D2 = «Developer PHP»
D3 = «Son is Developer and Student»
Inverted Index:
«Son» => {D1,D3}
«is» => {D1, D3}
«Developer» => {D1, D2, D3}
«PHP» => {D2}
«and» => {D3}
«Student» => {D3}
Query cụm “Son, is, Developer” thì ta sẽ có biểu thức union:
{D1,D3} union {D1,D3} union {D1, D2 ,D3} = {D1}
=> việc tìm kiếm trở nên nhanh hơn nhiều thay vì việc phải scan toàn bộ table để tìm ra tài liệu có chứa từ đó
Thực hiện FTS
Để thực hiện được FTS chúng ta cần lưu ý về cách đánh chỉ mục Fulltext:
- Nếu đánh chỉ mục cho 2 cột thì khi search chúng ta cũng phải điền cả 2 cột
- Thư tự đánh thế nào thì thứ tự search cũng phải vậy.
- Lưu ý: Fulltext là trường hợp đặc biệt của đánh index trong bảng
Ví dụ như sau
2.2 IN NATURAL LANGUAGE MODE(mặc định)
- Chế độ sort mặc định theo mức độ phù hợp (relevance rank)
- Công thức tính điểm cho mức độ phù hợp
- Được tính theo công thức:
(tất nhiên các bạn không cần quan tâm công thức loằng ngoằng này vì MySQL đã làm hết cho ta thông qua những câu lệnh)
Giải thích về công thức như sau: Nếu 1 tư khóa xuất hiện nhiều lần trong 1 bản ghi thì điểm weight của từ khóa đó sẽ tăng lên và ngược lại nếu từ khóa xuất hiện trong nhiều bản ghi thì điểm weight sẽ bị giảm đi.
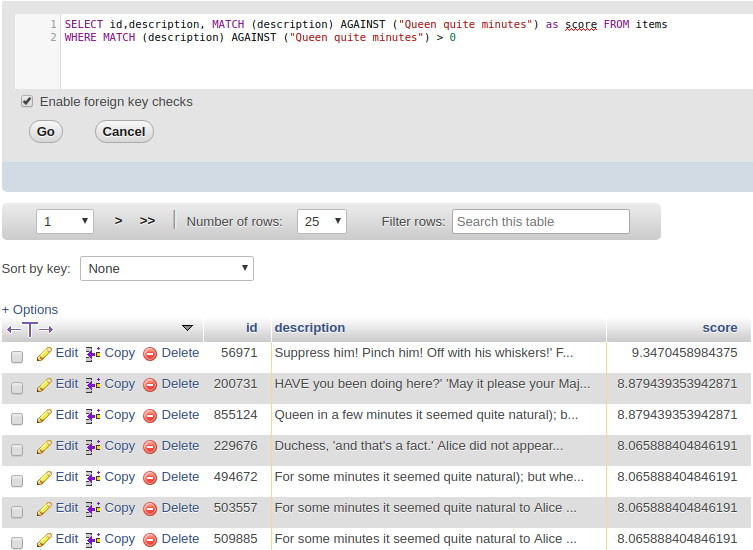
Với câu lệnh như trên: MATCH…AGAINST sẽ trả về điểm ranking dạng số thực dựa trên mức độ phù hợp của kết quả tìm thấy, kết quả trả về càng phù hợp thì có số rank càng cao
Bạn còn nhớ câu search cách từ với kiểu search cổ truyền lúc đầu chứ?Giờ ta sẽ so sánh với FTS nhé?
=> Passed
2.3 IN BOOLEAN MODE
- Search theo từ khóa tìm kiếm
-
Dùng toán từ ‘+’ hoặc ‘-’ để quyết định từ nào sẽ được trả về kết quả.
Và đây là danh sách các cách sử dụng wilcard của IBM trong FTS
2.4 Query Expansion
Theo mình chế độ này có lẽ là những điểm hay nhất nhưng cũng là hạn chế (hạn chế bởi vì nó chưa thể hiên thực sự hết khả năng của nó đáng ra phải mang lại trong quá trình mình tìm hiểu)
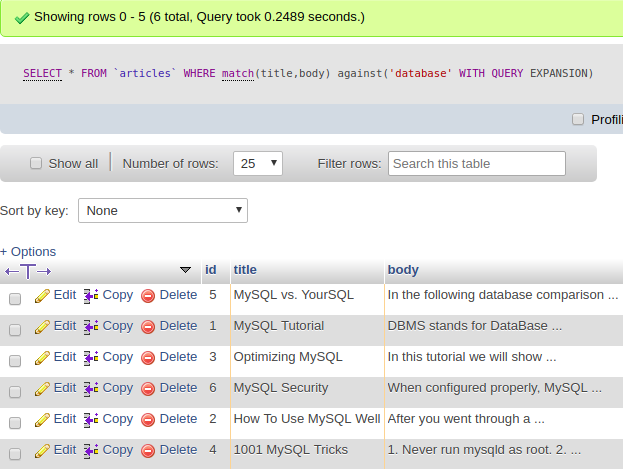
- MySQL sẽ thực hiện search 2 lần, trong lần search thứ 2 MySQL sẽ tìm kết hợp cụm từ tìm kiếm gốc với những từ thích hợp nổi bật so với từ khóa gốc.
Mặt khác đây chính là cái hay nhất trong fulltext search - Tìm được từ đồng nghĩa
- Tìm được từ viết tắt
- Sửa lỗi chính tả
- đánh lại trọng số weight
Để so sánh với mức độ lợi hại của Query Expansion thì mình có tìm hiểu về SQLServer thì thấy có 2 hàm của SQLServer là Hàm CONTAINS và Hàm FREETEXT mang lại giá trị tương đối cao với các giá trị trả về sát với định nghĩa về FTS. các bạn có thể tim hiểu thêm tại đây
I. Đặt vấn đề
Vấn đề 1
Giả sử ta có 1 bảng dữ liệu như sau
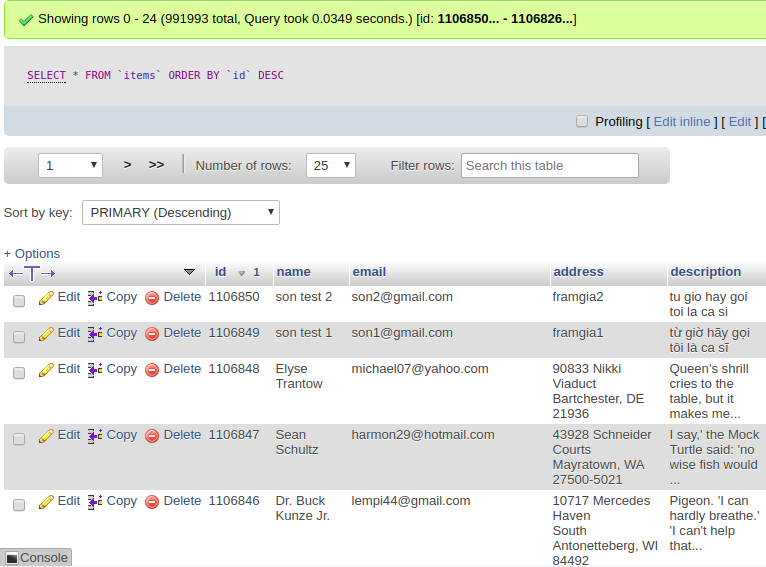
Gỉa sử bây giờ chúng ta muốn tìm 2000 items có bắt đầu bằng từ .
Và chắc chắn đây là câu lệnh quen thuộc mà chúng ta thường sử dụng . Khoan hãy xem kết quả, chúng ta hay xem hiệu năng của câu lệnh mang lại bằng việc thêm từ khóa vào trước câu lệnh trên. Sẽ mang lại cho ta kết quả như sau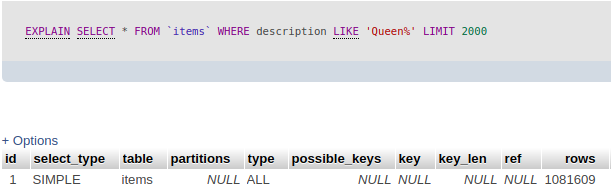
Về cơ bản khi bạn nhìn vào bảng dữ liệu này thì hãy chú ý một vài cột như:
- Type: All (Sau khi thực hiện câu lệnh MySQL sẽ duyệt qua toàn bộ bản ghi để lấy ra dữ liệu — thể hiện ở cột rows MySQL đã quét hơn 1M data, nếu trong table có 10M, 100M thì thật là…thất bại)
- Còn một vài trường như
- table : Table liên quan đến output data.
- type : Mức độ từ tốt nhất đến chậm nhất như sau: system, const, eq_ref, ref, range, index, all
- possible_keys : Đưa ra những Index có thể sử dụng để query
- key : và Index nào đang được sử dụng
- key_len : Chiều dài của từng mục trong Index
- ref : Cột nào đang sử dụng
Bạn có thể tham khảo thêm tại đây
Vấn đề 2
Trong bản ghi có 1 câu như thế này, giả sử bạn không thể nhớ hết được cả câu này, mà chỉ nhớ được 3 từ thôi. thì ta sẽ làm thế nào để tìm được các bản ghi đó? Nếu sử dụng câu lệnh như lúc đầu thì nó có chạy được hay không?
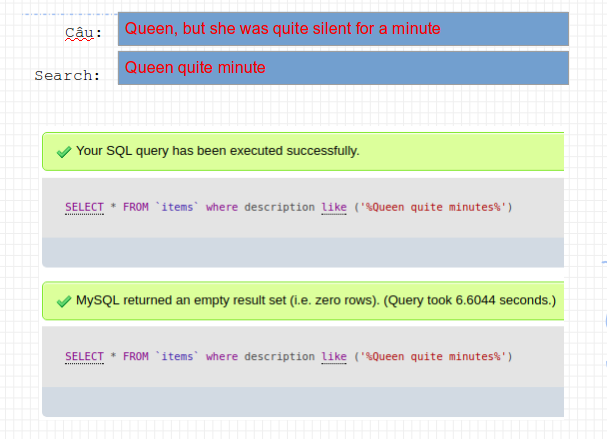
Rõ rang là . Và còn rất nhiều mặt hạn chế của . Vậy tổng kết lại ta được một list hạn chế như sau:
- Tốc độ chậm.
- Không tìm được từ đồng nghĩa
- Không tìm được các từ viết tắt phổ biến như: Trung Học Phổ Thông (THPT)
- Không tìm được tìm kiếm cách từ như ví dụ trên.
- Không search được do lỗi chính tả…
Vậy để hạn chế các vấn đề trên, MySQL đã hỗ trợ thêm cho chúng ta .






