Сбор информации из открытых источников — как видят вас потенциальные злоумышленники?
Содержание:
- Введение
- Какой ГОСТ определяет правила оформления?
- Алгоритм оформления
- История [ править | править код ]
- Поиск email через сетевой ханипот
- Слишком быстрая цифровизация — как причина роста утечек
- Определяем почтовые адреса
- Иные способы получения информации о должнике.
- О поиске по открытым источникам
- Социальная инженерия
- Форматирование раздела References
- Способы борьбы
- Пробиваем бота Telegram
- Определение почтовых адресов
- Поиск поддоменов
- Поиск по сервисам-агрегаторам и сетевое сканирование
Введение
Поиск информации об организации — это не только сканирование сетевых портов
Это — исследование вашего веб-сайта (при этом не важно, где он размещен, на внешнем хостинге или на вашей собственной площадке), изучение вашего периметра, всех ресурсов, которые там присутствуют. Собрав данные, злоумышленник начинает предпринимать попытки преодоления периметра и в случае успеха действовать уже внутри сети
На этапе сбора информации мы не можем активно противостоять ему; однако бездействие в борьбе за информационную безопасность нам не поможет. Именно поэтому нам надо самим собирать все доступные сведения об организации и делать так, чтобы злоумышленник не смог найти ничего полезного на нашем периметре.
Что же делать? Необходимо знать, что ты защищаешь. Добиться этого можно разными способами:
- инвентаризация — мы запрашиваем у администраторов информацию через опросные листы;
- автоматизированные средства изнутри — сетевые сканеры собирают информацию внутри ЛВС;
- поиск по открытым источникам — сбор информации о том, как злоумышленник видит периметр организации.
Именно о поиске по открытым источникам и поговорим в рамках данной статьи.
Какой ГОСТ определяет правила оформления?
При составлении любого списка литературы, нужно следовать основным правилам. Благодаря этому, каждый сможет понять, что за книга, журнал, статья или веб-ресурс были использованы, и отыскать их. Эта стандартизация позволяет глобализировать научный процесс. Ее цель, чтобы список интернет-источников (или любых других), составленный для курсовой студентом любого вуза был понятен профессорам в любой точке мира.
Чтобы достигнуть этой цели, в каждой стране введены определенные государственный стандарты.
В Российской Федерации оформления всех видов электронных ресурсов контролируется ГОСТом 7.82 — 2001. Кроме РФ, он был признан Межгосударственным Советом по стандартизации, метрологии и сертификации.
Алгоритм оформления
По сути, принцип записи источника информации, взятой из интернета, аналогичен оформлению обычной ссылки в списке литературы. Руководствуясь тем же порядком, здесь располагают данные:
- об авторе;
- о названии сайта, статьи и т. п.;
- о публикации (если они есть, в отличие от печатной продукции, в интернете эта информация может быть не полностью доступной или вовсе скрытой), позволяющее найти источник.
Согласно ГОСТу для электронных ресурсов все упомянутые выше пункты должны оформляться таким способом.
Автор. Сперва, указывается его фамилия, затем инициалы без расшифровки: Мышкевич К. К
Обратите внимание, что это должен быть именно создатель статьи или онлайн-книги, а не всего сайта. Хотя бывают случаи, когда это один и тот же человек
Например, как Алекс Экслер для своего авторского ресурса.
Как и в случае с книгами, их творцом, может быть не один человек, но группа лиц. Несмотря на это, вначале указывается только один из них. Тот, кто записан первым, даже если расположение автором не по алфавиту.
Встречается и другая ситуация, когда автор не указан, тогда на первом месте находится заглавие. Независимо от наличия/отсутствия информации о создателе, оно оформляется по единому стандарту. Может состоять как из нескольких слов, так и пары предложений. Они должно указывать на определенный отрывок, а не весь сайт целиком.
После заглавия в квадратных скобках обязательно пишется , вместо привычного . Это помогает обозначить тип документа. После него ставится знак «слеш» (/).
Сведения об ответственности. Это снова данные об авторах, редакторах, составителях. Начинают писаться с инициалов: М. К. Клавина. Если создателей более пяти — указываются только первые трое, затем «и др.» Например: М. Л. Розен, М. Н. Хрусталева, П. С. Бочкина и др. Если автор не указан, но есть данные о месте составления, именно их и следует записать. Например: НУИНУ (Научный универсальный институт необыкновенных услуг).
В случаях, когда приходится иметь дело с отрывком из онлайн-книги или журнала (как и с ссылками на бумажные источники), нужно записать, откуда он был взят. Иными словами, предоставить сведения об основном документе. Для этого перед его название ставится двойной «слеш» (//). Например: //Очевидное и невероятное.
Место и дату издания, в случае с веб-ресурсами, не всегда возможно установить. И если для книг они выглядя как «Китежград, 2018», то для интернет-источника это будет просто номер года и журнала (если это периодическое издание). Когда же эти данные не известны — допускается их пропуск.
Системные требования, способствующие просмотру страницы. В зависимости от его типологии могут отличаться. К примеру, если сайт платный, или определенная информация доступна только для зарегистрированных пользователей (как в случае с «Фейсбуком»).
Электронный адрес. Он нужен, чтобы можно было зайти на сайт, откуда взята информация для научной работы. Перед этими данными пишется «Режим доступа» и ставится знак «двоеточие» (:). Возможна его замена на аббревиатуру URL. Однако первый вариант предпочтительнее. Далее указывается адрес сайта, скопированный из интернета. Причем ссылка должна вести именно к той странице (книге, статье), где расположена использованная информация.
Дата обращения. Теоретически данный параметр не обязателен и его можно опустить. Вот только сайт, откуда были взяты данные, может перестать существовать или измениться. Поэтому, внося в ссылку на интернет-источник сведения о дате обращения (цифрами: число. месяц. год и «г.»), можно хоть немного застраховать себя от обвинения в применении недостоверных данных с несуществующем ресурсе.
В качестве примера можно привести ссылку на статью о правилах оформления различных источников в списке литературы, размещенную на этом же сайте:
Шамшурина Ю. С. Оформление списка литературы по ГОСТу: правила, примеры . Режим доступа: http://fb.ru/article/56233/cu-oformlenie-spiska-literaturyi-po-gostu-pravila-primeryi (Дата обращения: 23.11.2018 г.)
История [ править | править код ]
История OSINT начинается с формирования в декабре 1941 года Службы мониторинга зарубежных трансляций (англ. Foreign Broadcast Monitoring Service, FBMS ) в Соединённых Штатах Америки для изучения иностранных трансляций. Сотрудники службы записывали коротковолновые передачи на пластиковые диски, после чего отдельные материалы переписывались и переводились, а затем отправлялись в военные ведомства и подавались в формате еженедельных докладов . Классическим примером работы FBMS является получение информации об успешности проведения бомбардировок на вражеские мосты путём получения и анализа изменения цен на апельсины в Париже .
«Кто владеет информацией — тот владеет миром»
Поиск email через сетевой ханипот
А теперь предположим, что мы находимся в противоположной ситуации: можем контактировать с человеком только через сеть, например мессенджер Jabber. Мы знаем, что он занимается разработкой малвари, но ведет двойную жизнь и имеет официальную работу. Нам бы очень хотелось выяснить его личность, но использует он исключительно Tor и VPN. За что мы можем зацепиться в этом случае?
Вариант 1. Присоединись к сообществу «Xakep.ru», чтобы читать все материалы на сайте
Членство в сообществе в течение указанного срока откроет тебе доступ ко ВСЕМ материалам «Хакера», увеличит личную накопительную скидку и позволит накапливать профессиональный рейтинг Xakep Score!
Подробнее
Вариант 2. Открой один материал
Заинтересовала статья, но нет возможности стать членом клуба «Xakep.ru»? Тогда этот вариант для тебя!
Обрати внимание: этот способ подходит только для статей, опубликованных более двух месяцев назад.
Я уже участник «Xakep.ru»
Слишком быстрая цифровизация — как причина роста утечек
Мы собираем информацию о таких происшествиях с 2004 года. И все 15 лет видим, что их количество только растет. Причина роста — слишком быстрая цифровизация. Государственные услуги, финансы, медицина, добыча и переработка полезных ископаемых — все это быстро становится цифровым и вместе с новыми возможностями порождает новые угрозы, новые «дыры» в защите корпораций. После этого происходят масштабные «сливы» оцифрованной информации.
Рост их числа хорошо ощутим, если посмотреть на количество утекших записей пользовательских данных (это персональные данные и записи платежной информации). За 2018 год, по данным нашего аналитического центра, в мире утекло 7,28 млрд записей. А за первое полугодие 2019-го уже 8,74 млрд. То есть за половину нынешнего года мы перекрыли показатель всего предыдущего. В процентных показателях это значит, что за первую половину 2019 года утекло на 266% больше записей, чем за первую половину 2018-го. Таким образом, растет не только количество утечек, но и сами они становятся масштабнее, чем раньше.
Определяем почтовые адреса
Начнем с того, что лежит на поверхности и легко находится в интернете. В качестве примера я взял колледж в Канаде (alg…ge.com). Это наша учебная цель, о которой мы попробуем узнать как можно больше. Здесь и далее часть адреса опущена по этическим соображениям.
Чтобы заняться социальной инженерией, нам необходимо собрать базу почтовых адресов в домене жертвы. Идем на сайт колледжа и заглядываем в раздел с контактами.
Раздел с контактами на сайте alg…ge.com
Там представлены одиннадцать адресов. Попробуем собрать больше. Хорошая новость в том, что нам не придется рыскать по сайтам в поисках одиночных адресов. Воспользуемся инструментом theHarvester. В Kali Linux эта программа уже установлена, так что просто запускаем ее следующей командой:
После 2–5 минут ожидания получаем 125 адресов вместо 11 общедоступных. Хорошее начало!
Результат работы theHarvester
Если у них доменная система и стоит почтовый сервер Exchange, то (как это часто бывает) какой-то из найденных адресов наверняка будет доменной учетной записью.
Иные способы получения информации о должнике.
Рекомендации ФССП
Основным источником получения доступной информации о должнике служит интернет. По определению, всё, что можно найти в сети является общедоступной информацией. Методику поиска таких сведений можно найти в методичке ФССП «Использованию сети Интернет в целях поиска информации о должниках и их имуществе».
Посмотреть методические рекомендации
Конкретные способы получения сведений зависят от используемых инструментов. Например, поисковые системы (Гугл, Яндекс и т. д.) позволяют делать запросы, выбирающие все сетевые ресурсы, связанные ссылками с ресурсом должника.
Кратко и по сути
- Информацию о должнике можно и нужно собирать из всех доступных источниках
- Все что находится в сети интернет является общедоступной информацией
- В статье рассмотрены основные информационные ресурсы, условия и способы получения необходимых сведений.
Рыков Иван
Основатель антикризисной юридической компании «Рыков групп»
Специализации: антикризисное управление и банкротство крупных
предприятий и организаций;
управление проблемными активами; взыскание дебиторской задолженности, деятельность
коллекторов; субсидиарная ответственность по обязательствам должника.
О поиске по открытым источникам
Поиск по открытым источникам (OSINT) — процесс, в ходе которого производится обнаружение, выбор, сбор и анализ информации, находящейся в свободном доступе. Само понятие OSINT довольно широко; мы рассмотрим ту часть, которая относится к ИБ.
Можно выделить три различных метода сбора информации в OSINT:
- автоматизированными средствами;
- при помощи сервисов;
- ручным методом.
В усредненном виде автоматизированные средства поиска собирают следующую техническую информацию по доменному имени:
Разумеется, собираемые данные могут сильно различаться от объекта к объекту.
Предлагаю на примере одного домена, принадлежащего учебному заведению, рассмотреть, что же может быть обнаружено и чем это грозит.
Социальная инженерия
Как собирать такую информацию? Лучше использовать связку программного обеспечения (SpiderFoot, theHarvester) и сервисов (например, hunter.io) для ее обнаружения.
Добавить сопутствующих сведений нам помогут различные метаданные из офисных документов, размещенных на периметре. Для их сбора подойдут FOCA и Metagoofil. С той же целью после обнаружения файлов можно их выкачать и исследовать, уже имея локальные копии, при помощи ExifTool. Здесь мы можем обнаружить, например, имя автора, и даже этого будет достаточно для составления таргетированного фишингового письма, т.к. документ нам известен, а почтовые адреса мы собрали этапом ранее. Пример подобного письма показан ниже (рисунок 9).
Рисунок 9. Пример фишингового письма

Форматирование раздела References
Форматирование (выделение курсивом, расстановка знаков препинания) в русском и английских стандартах немного отличается. В русском списке источников по стандартам современного книгоиздания необходимо придерживаться требований ГОСТ, в то время как для обеспечения машиночитаемого распознавания раздела References, его необходимо оформить в соответствии с международными правилами. В настоящем разделе приведены основные отличия форматирования, которые надо исправить при подготовке раздела References:
| Элемент описания | Оформление по ГОСТ | Оформление в Referenses |
|---|---|---|
| Имя автора | выделяется курсивом | прямым шрифтомФамилия автора является одним из самых значимых для международных баз данных составляющих в библиографической ссылке, поэтому любая библиографическая запись должна начинаться с имени автора. Если в статье цитируется источник без авторства, по возможности в начало библиографической записи выносятся данные о составителе издания или других лицах, упомянутых в сведениях об ответственности (с указанием роли в скобках после имени, например: сост. И.И. Иванов -> Ivanov I.I. (ed.)). В исключительных случаях допускается использование библиографической записи без имени автора. |
| название журнала (сборника) в аналитической записи | Перед названием журнала ставится знак // | Название журнала (сборника) выделяется курсивом |
| Название монографии | прямой шрифт | выделяется курсивом |
| Разделительные знаки между полями | точка | запятая (исключение — перед местом издания (город) ставится точка) |
| Сведения об ответственности | размещаются после одной косой черты / | В разделе References не приводятся. Исключение составляет имя составителя, если у сборника нет автора. |
| Если статья содержит более 3 авторов, сведения о них размещаются за одной косой чертой | Все сведения об авторах статьи размещаются в начале библиографической записи |
Способы борьбы
Говоря о том, как нужно бороться с утечками, нужно, во-первых, сказать, что современным организациям все же не нужно пренебрегать традиционными инструментами, обеспечивающими безопасность. Без антивируса можно точно подвергнуться заражению. А без системы защиты от утечек — гарантированно потерять конфиденциальную информацию, причем не раз. Поэтому несмотря на то, что ни антивирус, ни DLP не дают 100-процентной гарантии, совсем без них обойтись нельзя.
Во-вторых, организациям нужно обучать сотрудников элементарной цифровой гигиене.
В-третьих, важно правильно проводить организационные мероприятия по недопущению утечек. В число этих мероприятий входит: ограничение доступа посторонних лиц в помещение, подписание сотрудниками соответствующих письменных обязательств, разграничение доступа к информации и так далее
Это целый комплекс действий, без которого никакая автоматическая система не будет эффективной.
Пробиваем бота Telegram
Как ты знаешь, у Telegram широкая функциональность для работы с ботами. Ничего не стоит создать нового, получить токен для управления и использовать в готовом скрипте с GitHub. Так же легко токены от ботов и утекают: найти их можно по элементарным доркам. А иногда в руки просто попадается малварь, которая использует функции Telegram как пульт управления, — знал бы ты, сколько архивов стиллеров хранится в облаке мессенджера!
Что останавливает от вытаскивания всей информации бота через утекший токен? Конечно, это API Telegram, в котором ограничиваются множественные подключения для ботов из разных мест. А даже если бот не работает или его владелец проигнорирует ошибки подключения, то мы все равно сможем получать только новые, не обработанные ранее сообщения. Наконец, бот не обладает знанием о том, с кем он общался в прошлом. Таким образом, прочитать историю не получится — нужно тихо ждать, пока кто-то напишет, чтобы перехватить сообщение.
К счастью, HTTP API для работы с ботами — это только надстройка над оригинальным MTProto API, который позволяет взаимодействовать с ними, как с человеческими аккаунтами. А для работы с этим протоколом уже есть готовые библиотеки! Лично я советую Telethon, в котором не так давно была реализована прослойка для управления ботами.
Как ты понимаешь, возможности при таком способе увеличиваются на порядок. Теперь мы можем подключиться незаметно для владельца бота и вытащить историю сообщений. А первый диалог, очевидно, будет с его хозяином. Я написал простой скрипт, который тащит переписки, сохраняет медиаконтент, имена и фотографии собеседников.
И кстати, ты наверняка помнишь, что недавно в Telegram добавили функцию удаления своих сообщений у собеседника. Так вот, если удалить сообщение из диалога с ботом, то у него оно останется.
Определение почтовых адресов
Приступим к сбору информации. Начнем с самого простого, и что легче всего находится в сети. В качестве эксперимента я выбрал колледж в Канаде (al…..ge.com). Это наша учебная цель, о которой мы постараемся накопать как можно больше информации. По этическим соображениям часть адреса будет скрыта.
Чтобы заняться социальной инженерией, нам потребуется собрать базу почтовых адресов в домене жертвы. Заходим на сайт колледжа и переходим в раздел с контактами.
Раздел с контактами на сайте al..…ge.com
Там представлены одиннадцать адресов. Попробуем собрать больше. Хорошая новость в том, что нам не придется рыскать по сайтам в поисках одиночных адресов. Воспользуемся инструментом theHarvester. В Kali Linux эта программа уже установлена, так что просто запускаем ее следующей командой:
-d alg*******ge.com -b all -l 1000
После нескольких минут утомительного ожидания получаем 125 адресов вместо 11 общедоступных. Хорошее начало, не правда ли?!
Результат работы theHarvester
Если у них доменная система, а почтовиком назначен сервер Exchange, то (как это обычно бывает) какой-нибудь из найденных почтовых ящиков наверняка будет доменной учетной записью.
Поиск поддоменов
Сейчас в большинстве организаций есть поддомены. Хакеры ищут там серверы удаленного доступа, неправильно настроенные сервисы или новые сетевые имена. Это уже не чисто пассивный сбор данных. Мы взаимодействуем с системой жертвы, но не так грубо, как, к примеру, при сканировании открытых портов. Поэтому с натяжкой метод можно отнести к пассивным техникам.
Брутфорс субдоменов
Суть этого метода состоит в том, чтобы подобрать имя поддомена. Воспользоваться можно программой host. Введем команду
$ host ns3.alg*******ge.com
В ответ получим строку ns3.alg*******ge.com has address 205***.***.11, то есть — такой поддомен существует.
Согласитесь, вручную перебирать имена — нудное занятие. Поэтому мы будем автоматизировать. Создадим файл со списком имен поддоменов. Можно найти готовый на просторах интернета, но для демонстрации я создал простейший файл с содержимым mail dns ftp file vpn test dev prod voip firewall и называл его dns. Теперь для запуска перебора имен необходимо написать мини-скрипт:
for name in $(cat dns);do host $name.alg*******ge.com |grep "has address"; done
Перебор поддоменов программой host
DNSMap
Есть неплохой инструмент DNSMap. Он делает почти те же действия, что описаны выше. В нем уже встроен словарь, но можно использовать и свой. Для запуска перебора необходимо набрать
$ dnsmap alg*******ge.com
Процесс это небыстрый. У меня он занял (для выбранного домена) 1555 секунд, но и результат выдал неплохой — нашел 18 поддоменов.
Лог DNSMap
Поиск по сервисам-агрегаторам и сетевое сканирование
Зачем тратить свое время на сканирование, если можно забрать данные из Shodan?
На выбранном целевом домене находим сервис Apache версии 2.2.15 при помощи Shodan, просто указав в поиске интересующее нас доменное имя.
Рисунок 1. Версия Apache
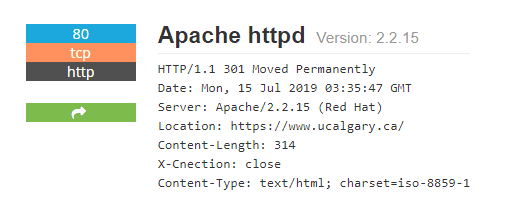
Проверяем, есть ли какие-то уязвимости в данной версии, при помощи того же Shodan. Просто пролистав страницу ниже, обнаруживаем более 20 уязвимостей различного уровня критичности, в том числе — с готовыми эксплойтами. Наличие последних можно проверить на сервисе Vulmon — либо по CVE, либо по версии программного обеспечения.
Рисунок 2. Уязвимость с эксплойтом

Брешь на рисунке 2 позволяет проводить DoS-атаки на сервер и имеет готовый модуль в Metasploit. Напомню, что для избавления от большинства уязвимостей нужно регулярно обновлять компоненты.
Расширение границ исследования
Инфраструктура не ограничивается одним лишь веб-ресурсом, и на следующем шаге мы смотрим, какой перечень подсетей был выделен организации. Для этого переходим на bgp.he.net и указываем в поисковой строке интересующую нас организацию или IP-адрес.
Рисунок 3. Зарегистрированная сеть

На данном ресурсе можно получить еще и перечень доменных имен в одно нажатие клавиши. На вкладке DNS мы видим, что имеется более 1000 зарегистрированных имен.
Рисунок 4. Перечень доменных имен
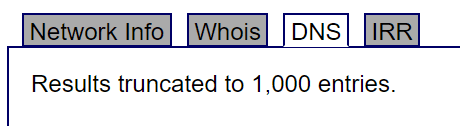
Здесь мы можем сразу найти наиболее перспективные для атак доменные имена активов: корпоративные мессенджеры, сервисы для пользователей, средства удаленного управления и т.д.
Рисунок 5. Threatcrowd

Другие агрегаторы
Хочу обратить внимание, что мы собрали уже довольно большой объем информации и при этом сами не отправили еще ни байта в адрес объекта исследования. У нас с вами уже имеется представление о сетевой инфраструктуре, о том, где и в каких сетях размещены объекты, перечень известных сетевых имен, по некоторым узлам был получен список уязвимостей и существующих эксплойтов
Результаты активного сетевого сканирования
Большинство инструментов имеет встроенные сетевые сканеры, которые сами проведут исследование указанного домена. На фоне довольно большого количества специализированных качественных сканеров, которые и перечень уязвимостей составят, и красивый отчет оформят, данная функциональность выглядит сомнительно. Однако она существует и может помочь в определении сервисов БД, FTP и различных служб удаленного администрирования, которые не должны присутствовать на периметре.
Внешние Java-скрипты
Хочется сделать акцент на возможности обнаружить на вашем ресурсе внешние Java-скрипты.
Рисунок 6. Внешние Java-скрипты

Почему это важно? Если скрипт будет изменен на оригинальном ресурсе, то мы получим изменения и у себя. Будет ли это правка кода или же очередной майнер криптовалюты, никто не скажет
Как это обнаруживать? Я использовал SpiderFoot.
Лучше, конечно, применять Java-скрипты, размещенные на своей собственной инфраструктуре.






