Как парсить сайт: 20+ инструментов на все случаи жизни
Содержание:
- Виды парсеров по сферам применения
- Установка Scrapy
- Десктопные и облачные парсеры
- Что такое парсинг
- Кому и зачем нужны парсеры сайтов
- Running Parse Server elsewhere
- Неправильная кодировка при использовании cURL
- Обзор Scrapy
- cURL и аутентификация в веб-формах (передача данных методом GET и POST)
- Ограничения при парсинге
- Для чего нужен парсинг
- Customizing your GraphQL Schema
- Извлечение информации из заголовков при использовании cURL
- Learning more
- Upgrading to 3.0.0
- Want to ride the bleeding edge?
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
Установка Scrapy
С установленным Python 3.0 (и новее) при использовании Anaconda можно применить команду для установки . Напишите следующую команду в Anaconda:
Чтобы , посмотрите эти руководства PythonRu для Mac и Windows.
Также можно использовать установщик пакетов pyhton pip. Это работает в Linux, Mac и Windows:
Scrapy Shell
Scrapy предоставляет оболочку веб-сканера Scrapy Shell, которую разработчики могут использовать для проверки своих предположений относительно поведения сайта. Возьмем в качестве примера страницу с планшетами на сайте Aliexpress. С помощью Scrapy можно узнать, из каких элементов она состоит и понять, как это использовать в конкретных целях.
Откройте командную строку и напишите следующую команду:
При использовании Anaconda можете написать эту же команду прямо в . Вывод будет выглядеть приблизительно вот так:
Необходимо запустить парсер на странице с помощью команды в оболочке. Он пройдет по странице, загружая текст и метаданные. fetch(“https://www.aliexpress.com/category/200216607/tablets.html”)
Вывод будет следующий:
Парсер возвращает (ответ), который можно посмотреть с помощью команды . А страница откроется в браузере по умолчанию. С помощью команды можно посмотреть сырой HTML.
Отобразится скрипт, который генерирует страницу. Это то же самое, что вы видите по нажатию правой кнопкой мыши в пустом месте и выборе «Просмотр кода страница» или «Просмотреть код». Но поскольку нужна конкретная информация, а не целый скрипт, с помощью инструментов разработчика в браузере необходимо определить требуемый элемент. Возьмем следующие элементы:
- Название планшета
- Цена планшета
- Количество заказов
- Имя магазина
Нажмите правой кнопкой по элементу и кликните на «Просмотреть код».
Инструменты разработчика сильно помогут при работе с парсингом. Здесь видно, что есть тег с классом , а сам текст включает название продукта:
Использование CSS-селекторов для извлечения
Извлечь эту информацию можно с помощью атрибутов элементов или CSS-селекторов в виде классов. Напишите следующее в оболочке Scrapy, чтобы получить имя продукта:
Вывод:
извлекает первый элемент, соответствующий селектору css. Для извлечения всех названий нужно использовать :
Следующий код извлечет ценовой диапазон этих продуктов:
То же можно повторить для количества заказов и имени магазина.
Использование XPath для извлечения
XPath — это язык запросов для выбора узлов в документах типа XML. Ориентироваться по документу можно с помощью XPath. Scrapy использует этот же язык для работы с объектами документа HTML. Использованные выше CSS-селекторы также конвертируются в XPath, но в большинстве случаев CSS очень легко использовать
И тем не менее важно значить, как язык работает в Scrapy
Откройте оболочку и введите как и раньше. Попробуйте написать следующий код:
Он покажет весь код в теге . указывает на прямого потомка узла. Если нужно получить теги в , то необходимо писать:
Для XPath важно научиться понимать, как используются и , чтобы ориентироваться в дочерних узлах. Если необходимо получить все теги , то нужно написать то же самое, но без :
Если необходимо получить все теги , то нужно написать то же самое, но без :
Можно и дальше фильтровать начальные узлы, чтобы получить нужные узлы с помощью атрибутов и их значений. Это синтаксис использования классов и их значений.
Используйте для извлечения всего текста в узлах
Десктопные и облачные парсеры
Облачные парсеры
Основное преимущество облачных парсеров — не нужно ничего скачивать и устанавливать на компьютер. Вся работа производится «в облаке», а вы только скачиваете результаты работы алгоритмов. У таких парсеров может быть веб-интерфейс и/или API (полезно, если вы хотите автоматизировать парсинг данных и делать его регулярно).
Например, вот англоязычные облачные парсеры:
- Import.io,
- Mozenda (доступна также десктопная версия парсера),
- Octoparce,
- ParseHub.
Из русскоязычных облачных парсеров можно привести такие:
- Xmldatafeed,
- Диггернаут,
- Catalogloader.
Любой из сервисов, приведенных выше, можно протестировать в бесплатной версии. Правда, этого достаточно только для того, чтобы оценить базовые возможности и познакомиться с функционалом. В бесплатной версии есть ограничения: либо по объему парсинга данных, либо по времени пользования сервисом.
Десктопные парсеры
Большинство десктопных парсеров разработаны под Windows — на macOS их необходимо запускать с виртуальных машин. Также некоторые парсеры имеют портативные версии — можно запускать с флешки или внешнего накопителя.
Популярные десктопные парсеры:
- ParserOK,
- Datacol,
- Screaming Frog, ComparseR, Netpeak Spider — об этих инструментах чуть позже поговорим подробнее.
Что такое парсинг
Парсинг (parsing) – это буквально с английского «разбор», «анализ». Под парсингом обычно имеют ввиду нахождение, вычленение определённой информации.
Парсинг сайтов может использоваться при создании сервиса, а также при тестировании на проникновение. Для пентестера веб-сайтов, навык парсинга сайтов является базовыми, т.е. аудитор безопасности (хакер) должен это уметь.
Умение правильно выделить информацию зависит от мастерства владения регулярными выражениями и командой grep (очень рекомендую это освоить – потрясающее испытание для мозга!). В этой же статье будут рассмотрены проблемные моменты получения данных, поскольку все сайты разные и вас могут ждать необычные ситуации, которые при первом взгляде могут поставить в тупик.
В качестве примера парсинга сайтов, вот одна единственная команда, которая получает заголовки последних десяти статей, опубликованных на HackWare.ru:
curl -s https://hackware.ru/ | grep -E -o '<h3 class=ftitle>.*</h3>' | sed 's/<h3 class=ftitle>//' | sed 's/<\/h3>//'

Подобным образом можно автоматизировать получение и извлечение любой информации с любого сайта.
Кому и зачем нужны парсеры сайтов
Парсеры экономят время на сбор большого объема данных и группировку их в нужный вид. Такими сервисами пользуются интернет-маркетологи, вебмастера, SEO-специалисты, сотрудники отделов продаж.
Парсеры могут выполнять следующие задачи:
Кому и для каких целей требуются парсеры, разобрались. Если вам нужен этот инструмент, есть несколько способов его заполучить.
- При наличии программистов в штате проще всего поставить им задачу сделать парсер под нужные цели. Так вы получите гибкие настройки и оперативную техподдержку. Самые популярные языки для создания парсеров — PHP и Python.
- Воспользоваться бесплатным или платным облачным сервисом.
- Установить подходящую по функционалу программу.
- Обратиться в компанию, которая разработает инструмент под ваши нужды (ожидаемо самый дорогой вариант).
С первым и последним вариантом все понятно. Но выбор из готовых решений может занять немало времени. Мы упростили эту задачу и сделали обзор инструментов.
Running Parse Server elsewhere
Once you have a better understanding of how the project works, please refer to the Parse Server wiki for in-depth guides to deploy Parse Server to major infrastructure providers. Read on to learn more about additional ways of running Parse Server.
Parse Server Sample Application
We have provided a basic Node.js application that uses the Parse Server module on Express and can be easily deployed to various infrastructure providers:
- Pivotal Web Services
Parse Server + Express
You can also create an instance of Parse Server, and mount it on a new or existing Express website:
var express = require('express');
var ParseServer = require('parse-server').ParseServer;
var app = express();
var api = new ParseServer({
databaseURI: 'mongodb://localhost:27017/dev', // Connection string for your MongoDB database
cloud: '/home/myApp/cloud/main.js', // Absolute path to your Cloud Code
appId: 'myAppId',
masterKey: 'myMasterKey', // Keep this key secret!
fileKey: 'optionalFileKey',
serverURL: 'http://localhost:1337/parse' // Don't forget to change to https if needed
});
// Serve the Parse API on the /parse URL prefix
app.use('/parse', api);
app.listen(1337, function() {
console.log('parse-server-example running on port 1337.');
});
Неправильная кодировка при использовании cURL
В настоящее время на большинстве сайтов используется кодировка UTF-8, с которой cURL прекрасно работает.
Но, например, при открытии некоторых сайтов:
curl http://z-oleg.com/
Вместо кириллицы мы увидим крякозяблы:
Кодировку можно преобразовать «на лету» с помощью команды iconv. Но нужно знать, какая кодировка используется на сайте. Для этого обычно достаточно заглянуть в исходный код веб-страницы и найти там строку, содержащую слово charset, например:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
Эта строка означает, что используется кодировка windows-1251.
Для преобразования из кодировки windows-1251 в кодировку UTF-8 с помощью iconv команда выглядит так:
iconv -f windows-1251 -t UTF-8
Совместим её с командой curl:
curl http://z-oleg.com/ | iconv -f windows-1251 -t UTF-8
После этого вместо крякозяблов вы увидите русские буквы.
Обзор Scrapy
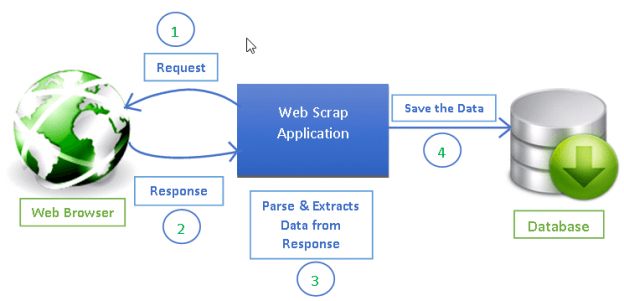
Веб-скрапинг (парсинг) стал эффективным путем извлечения информации из сети для последующего принятия решений и анализа. Он является неотъемлемым инструментом в руках специалиста в области data science. Дата сайентисты должны знать, как собирать данные с веб-страниц и хранить их в разных форматах для дальнейшего анализа.
Любую страницу в интернете можно исследовать в поисках информации, а все, что есть на странице — можно извлечь. У каждой страницы есть собственная структура и веб-элементы, из-за чего необходимо писать собственных сканеров для каждой страницы.
Scrapy предоставляет мощный фреймворк для извлечения, обработки и хранения данных.
Scrapy использует — автономных сканеров с определенным набором инструкций. С помощью фреймворка легко разработать даже крупные проекты для скрапинга, так чтобы и другие разработчики могли использовать этот код.
cURL и аутентификация в веб-формах (передача данных методом GET и POST)
Аутентификация в веб-формах – это тот случай, когда мы вводим логин и пароль в форму на сайте. Именно такая аутентификация используется при входе в почту, на форумы и т. д.
Использование curl для получения страницы после HTTP аутентификации очень сильно различается в зависимости от конкретного сайта и его движка. Обычно, схема действий следующая:
1) С помощью Burp Suite или Wireshark узнать, как именно происходит передача данных. Необходимо знать: адрес страницы, на которую происходит передача данных, метод передачи (GET или POST), передаваемая строка.
2) Когда информация собрана, то curl запускается дважды – в первый раз для аутентификации и получения кукиз, второй раз – с использованием полученных кукиз происходит обращение к странице, на которой содержаться нужные сведения.
Используя веб-браузер, для нас получение и использование кукиз происходит незаметно. При переходе на другую страницу или даже закрытии браузера, кукиз не стираются – они хранятся на компьютере и используются при заходе на сайт, для которого предназначены. Но curl по умолчанию кукиз не хранит. И поэтому после успешной аутентификации на сайте с помощью curl, если мы не позаботившись о кукиз вновь запустим curl, мы не сможем получить данные.
Для сохранения кукиз используется опция —cookie-jar, после которой нужно указать имя файла. Для передачи данных методом POST используется опция —data. Пример (пароль заменён на неверный):
curl --cookie-jar cookies.txt http://forum.ru-board.com/misc.cgi --data 'action=dologin&inmembername=f123gh4t6&inpassword=111222333&ref=http%3A%2F%2Fforum.ru-board.com%2Fmisc.cgi%3Faction%3Dlogout'
Далее для получения информации со страницы, доступ на которую имеют только зарегестрированные пользователи, нужно использовать опцию -b, после которой нужно указать путь до файла с ранее сохранёнными кукиз:
curl -b cookies.txt 'http://forum.ru-board.com/topic.cgi?forum=35&topic=80699&start=3040' | iconv -f windows-1251 -t UTF-8
Эта схема может не работать в некоторых случаях, поскольку веб-приложение может требовать указание кукиз при использовании первой команды (встречалось такое поведение на некоторых роутерах), также может понадобиться указать верного реферера, либо другие данные, чтобы аутентификация прошла успешно.
Ограничения при парсинге
Есть несколько вариантов ограничений, которые могут затруднить работу парсера:
- По user-agent. Это запрос, в котором программа сообщает сайту о себе. Парсеры банят многие веб-ресурсы. Однако в настройках данные можно изменить на YandexBot или Googlebot и отсылать правильные запросы.
- По robots.txt, в котором прописан запрет для индексации поисковыми роботами Яндекса или (ими мы представились сайту выше) определенных страниц. Необходимо задать в настройках программы игнорирование robots.txt.
- По IP-адресу, если с него в течение долгого времени поступают на сайт однотипные запросы. Решение — использовать VPN.
- По капче. Если действия похожи на автоматические, выводится капча. Научить парсеры распознавать конкретные виды достаточно сложно и дорогостояще.
Для чего нужен парсинг
Использование этого процесса в информатике очень разнообразно. Перечислить все варианты его применения практически невозможно.
Рассмотрим наиболее важные примеры.
Активнее всего «парсят» всемирную паутину поисковые сервисы. Их программы парсеры, которые называют поисковыми роботами или пауками, непрерывно просматривают и анализируют сайты, пополняя и обновляя свои базы данных. Эта незаметная, но очень важная для нас работа позволяет практически мгновенно находить нужную нам информацию.
Парсинг используется для наполнения сайтов контентом. В некоторых случаях это оправданно, а в некоторых такое действие можно считать воровством интеллектуальной собственности.
Парсинг необходим для быстрого обновления новостных сайтов и других сайтов, содержащих информацию, которая быстро и постоянно изменяется, например, сводки погоды, курсы валюты, изменения на биржах и т. д.
Парсеры мгновенно отслеживают все изменения и отправляют их на сайты заказчиков. Все происходит без вмешательства человека. Мы открываем сайт и смотрим, какая сейчас погода, каков курс доллара на данный момент в разных банках, на каком участке дороги есть пробки и многое другое.
Как я уже упоминал, парсинг необходим для поиска ключевых слов при составлении семантического ядра.
Customizing your GraphQL Schema
Parse GraphQL Server allows you to create a custom GraphQL schema with own queries and mutations to be merged with the auto-generated ones. You can resolve these operations using your regular cloud code functions.
To start creating your custom schema, you need to code a file and initialize Parse Server with and options:
$ parse-server --appId APPLICATION_ID --masterKey MASTER_KEY --databaseURI mongodb://localhost/test --publicServerURL http://localhost:1337/parse --cloud ./cloud/main.js --graphQLSchema ./cloud/schema.graphql --mountGraphQL --mountPlayground
Creating your first custom query
Use the code below for your and files. Then restart your Parse Server.
# schema.graphql
extend type Query {
hello: String! @resolve
}
// main.js
Parse.Cloud.define('hello', async () => {
return 'Hello world!';
});
You can now run your custom query using GraphQL Playground:
query {
hello
}
You should receive the response below:
{
"data": {
"hello": "Hello world!"
}
}
Извлечение информации из заголовков при использовании cURL
Иногда необходимо извлечь информацию из заголовка, либо просто узнать, куда делается перенаправление.
Заголовки – это некоторая техническая информация, которой обмениваются клиент (веб-браузер или программа curl) с веб-приложением (веб-сервером). Обычно нам не видна эта информация, она включает в себя такие данные как кукиз, перенаправления (редиректы), данные о User Agent, кодировка, наличие сжатия, информация о рукопожатии при использовании HTTPS, версия HTTP и т.д.
Пример команды:
curl -s -I -A 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36' https://www.acrylicwifi.com/AcrylicWifi/UpdateCheckerFree.php?download | grep -i '^location'
Получаемый результат:
location: https://tarlogiccdn.s3.amazonaws.com/AcrylicWiFi/Home/Acrylic_WiFi_Home_v3.3.6569.32648-Setup.exe
В этой команде имеются уже знакомые нам опции -s (подавление вывода) и -A (для указания своего пользовательского агента).
Новой опцией является -I, которая означает показывать только заголовки. Т.е. не будет показываться HTML код, поскольку он нам не нужен.
На этом скриншоте видно, в какой именно момент отправляется информация о новой ссылке для перехода:

curl -s -v http://www.paterva.com/web7/downloadPaths41.php -d 'fileType=exe&os=Windows' 2>&1 | grep -i 'Location:'
Обратите внимание, что в этой команде не использовалась опция -I, поскольку она вызывает ошибку:
Warning: You can only select one HTTP request method! You asked for both POST Warning: (-d, --data) and HEAD (-I, --head).
Суть ошибки в том, что можно выбрать только один метод запроса HTTP, а используются сразу два: POST и HEAD.
Кстати, опция -d (её псевдоним упоминался выше (—data), когда мы говорили про HTML аутентификацию через формы на веб-сайтах), передаёт данные методом POST, т.е. будто бы нажали на кнопку «Отправить» на веб-странице.
В последней команде используется новая для нас опция -v, которая увеличивает вербальность, т.е. количество показываемой информации. Но особенностью опции -v является то, что она дополнительные сведения (заголовки и прочее) выводит не в стандартный вывод (stdout), а в стандартный вывод ошибок (stderr). Хотя в консоли всё это выглядит одинаково, но команда grep перестаёт анализировать заголовки (как это происходит в случае с -I, которая выводит заголовки в стандартный вывод). В этом можно убедиться используя предыдущую команду без 2>&1:
curl -s -v http://www.paterva.com/web7/downloadPaths41.php -d 'fileType=exe&os=Windows' | grep -i 'Location:'
Строка с Location никогда не будет найдена, хотя на экране она явно присутствует.
Конструкция 2>&1 перенаправляет стандартный вывод ошибок в стандартный вывод, в результате внешне ничего не меняется, но теперь grep может обрабатывать эти строки.
Более сложная команда для предыдущего обработчика форм (попробуйте в ней разобраться самостоятельно):
timeout 10 curl -s -L -v http://www.paterva.com/web7/downloadPaths.php -d 'fileType=exe&client=ce&os=Windows' -e 'www.paterva.com/web7/downloads.php' 2>&1 >/dev/null | grep -E 'Location:'
Learning more
You also have a very powerful tool inside your GraphQL Playground. Please look at the right side of your GraphQL Playground. You will see the and menus. They are automatically generated by analyzing your application schema. Please refer to them and learn more about everything that you can do with your Parse GraphQL API.
Upgrading to 3.0.0
Starting 3.0.0, parse-server uses the JS SDK version 2.0.
In short, parse SDK v2.0 removes the backbone style callbacks as well as the Parse.Promise object in favor of native promises.
All the Cloud Code interfaces also have been updated to reflect those changes, and all backbone style response objects are removed and replaced by Promise style resolution.
We have written up a migration guide, hoping this will help you transition to the next major release.
Want to ride the bleeding edge?
It is recommend to use builds deployed npm for many reasons, but if you want to use
the latest not-yet-released version of parse-server, you can do so by depending
directly on this branch:






