Решение «монитор производительности сети»: мониторинг производительностиnetwork performance monitor solution: performance monitoring
Содержание:
Необходимые пакеты управленияRequired management packs
Сетевое обнаружение и мониторинг требует наличия следующих пакетов управления, которые устанавливаются с Operations Manager:Network discovery and monitoring requires the following management packs, which are installed with Operations Manager:
-
Microsoft.Windows.Server.NetworkDiscovery,Microsoft.Windows.Server.NetworkDiscovery
-
Microsoft.Windows.Client.NetworkDiscovery.Microsoft.Windows.Client.NetworkDiscovery
Существует два дополнительных пакета управления, которые требуются для соотнесения сетевых устройств друг с другом и с компьютерами агентов, к которым они подключены.There are additional management packs that are required to relate network devices to each other and to the agent computers they are connected to. Сетевой мониторинг требует обнаружения сетевых адаптеров для каждого компьютера агента, и такое обнаружение выполняется пакетом управления для ОС компьютера агента.Network monitoring requires discovery of the network adapter for each agent computer, which is performed by the management pack for the agent computer’s operating system. Проверьте, что все пакеты управления из следующего списка установлены в каждой операционной системе вашей среды.Verify that the management packs from the following list are installed for each of the operating systems in your environment.
Состояние портов
- доступность порта;
- уровень сигнала (для оптических портов);
- объем трафика (скорость порта);
- ошибки.
1.3.6.1.2.1.2.2.1.8.ifindexiso.3.6.1.2.1.2.2.1.8.1073741829 = INTEGER: 2Визуализация ответа в Nagios.1.3.6.1.4.1.9.9.91.1.1.1.1.4.txindex iso.3.6.1.4.1.9.9.91.1.1.1.1.4.6869781 = INTEGER: 85801.3.6.1.4.1.9.9.91.1.1.1.1.4.rxindexiso.3.6.1.4.1.9.9.91.1.1.1.1.4.63630989 = INTEGER: 2499Статистика сигнала на оптической трассе в Cacti.1.3.6.1.2.1.31.1.1.1.6.ifindex iso.3.6.1.2.1.31.1.1.1.6.1073741831 = Counter64: 1090487139681.3.6.1.2.1.31.1.1.1.10.ifindex iso.3.6.1.2.1.31.1.1.1.10.1073741831 = Counter64: 67229991783График скорости передачи данных в Cacti.1.3.6.1.2.1.2.2.1.14.ifindexiso.3.6.1.2.1.2.2.1.14.1073741831 = Counter32: 01.3.6.1.2.1.2.2.1.20.ifindexiso.3.6.1.2.1.2.2.1.20.1073741831 = Counter32: 0Статистика в Cacti фиксирует количество ошибок при передаче пакетов в секунду.Discards In/OutErrors In/OutТак выглядит проверка на наличие ошибок на портах в Nagios.snmp ifmib ifindex persist
NetworkMiner
NetworkMiner captures network packets and then parses the data to extract files and images, helping you to reconstruct events that a user has taken on the network – it can also do this by parsing a pre-captured PCAP file. You can enter keywords which will be highlighted as network packets are being captured. NetworkMiner is classed as a Network Forensic Analysis Tool (NFAT) that can obtain information such as hostname, operating system and open ports from hosts.
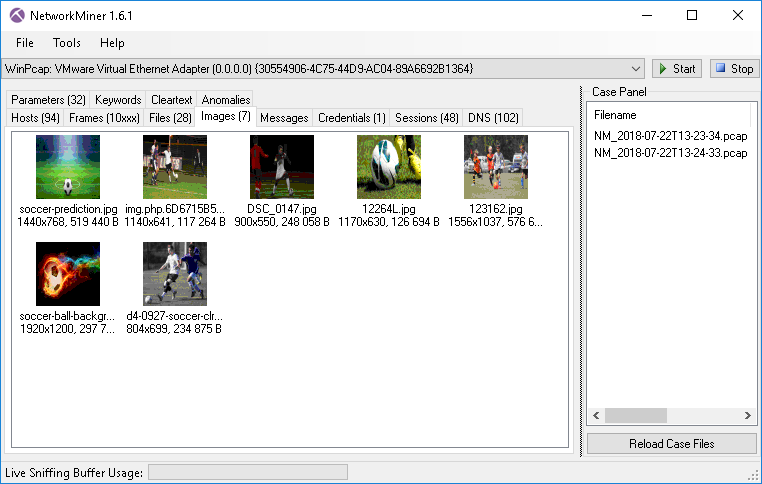
In the example above, I set NetworkMiner to capture packets, opened a web browser and searched for “soccer” as a keyword on Google Images. The images displayed in the Images tab are what I saw during my browser session.
When you load NetworkMiner, choose a network adapter to bind to and hit the “Start” button to initiate the packet capture process.
Компоненты системы
Сервис состоит из двух компонентов: сервера и агента. Агент собирает snmp-данные об интерфейсах и отправляет их на сервер. Сервер обрабатывает (сортирует, обновляет rrd-файлы и прочая) полученные данные и отображает через web-интерфейс.
Как работает сервер
Сервер — это docker-контейнер со «стандартным» набором софта: nginx/php-fpm/memcached/mysql/rrdtool. Сервер ожидает, что агенты будут присылать данные каждые 5 минут. Данные сохраняются в базе – по нагрузке интерфейсов и ошибкам ведётся недельная history, по которой рассчитываются 95-й перцентиль и топ по max/avg. Сделано это для того, что «видеть» сеть в разных «разрезах» – без редких всплесков или наоборот, когда нужно посмотреть только всплески.
Данные контейнера хранятся на хостовой системе для удобства обновления, бекапа и переноса сервера на другие хосты. Обновиться можно буквально одной командой (идея взята у докера, см. https://get.docker.com)
Как работает агент
Агент – это тоже docker-контейнер, в котором по крону раз в 5 минут запускается агент, собирающий snmp-данные об интерфейсах с сетевых устройств или серверов. Пока что интервал обновления (опроса) устройств изменить нельзя.
Клиент поддерживает две версии SNMP – v2 и v3.
Конфигурация агента, логи, и отправляемые данные хранится на хостовой системе. Это позволяет легко редактировать конфиги, переносить агента на другие хосты при необходимости.
Как написать программу для мониторинга сети на C#
Наша цель — написать простой сетевой монитор, чтобы в фоновом режиме отслеживать главные показатели в сети и сохранять их для анализа. Думаю, сбора следующих параметров хватит с головой, а если тебе понадобится что-то еще, всегда можно добавить (не забудь рассказать об этом мне).
- Пинг для заданных хостов. Просто маст-хэв для любой диагностической утилиты. Измеряя пинг, можно узнать также и процент потерь пакетов (packet loss), и коды ошибок, позволяющие узнать, что именно не так с сетью. Например, означает, что сеть вроде и есть, но администратор какого-то из промежуточных устройств не пропускает пакет. В общем, анализировать статус-коды ответов обязательно.
- Реальная возможность подключений по TCP. Возможна ситуация, когда хосты вроде живы и откликаются на пинг, DNS работает, а доступ в интернет закрыт за неоплату. Этот тест потенциально позволит нам выявить недобросовестного провайдера, который подделывает ответы на пинги, но не обеспечивает реальный коннект.
- Уведомления о времени даунтайма в Telegram. Они должны отправляться, как только соединение восстановится. Сообщение по-хорошему должно включать расширенную инфу о пинге и потерях пакетов после сбоя, а также состояние HTTP-клиента.
- Доступ к роутеру. Для домашней сети с нестабильным Wi-Fi это особенно актуально. Роутер может просто упасть от перегрузки (например, очередной школохакер ломится на дырявый WPS, но вместо взлома получается DoS) или попросту не выдержать всех клиентов, которых в ином «умном доме» может быть и 15, и 20. Короче, роутер в любой момент может уйти в перезагрузку, а мы будем грешить на провайдера. Это нехорошо, поэтому при потере связи с роутером мы не будем тестировать дальше, а просто подождем, пока починят.
Цели обрисованы. Теперь детали реализации.
- Программа предназначена для длительной работы в фоновом режиме. Оформим программу как системный сервис Windows.
- Если мы работаем в фоновом режиме, ни консольный интерфейс, ни тем более GUI нам не нужен. Тем лучше — меньше кода.
- Проверки не должны сильно нагружать канал, ведь будет некомфортно работать. Так что постоянно флудить пингами мы не станем. Отправим очередь из десятка пакетов раз в минуту-две, и хватит. Реже отправлять не имеет смысла — большинство неполадок устраняются в течение нескольких минут, а мы хотим знать о каждом сбое.
- Возможность хранить отчет в JSON и выгружать CSV для изучения в Excel — с фильтрацией по дате создания.
- Неплохо бы прикрутить возможность забирать логи по сети и скидывать статистику на центральный сервер, но в рамках демо я этого делать не буду.
Из этого следует, что нам понадобится работа с JSON. Писать я буду на C# и воспользуюсь модулем Json.NET.
GFI LanGuard (our award-winning paid solution)
People say it’s good to be modest and not to brag, but we’re so proud of our network management tool that we had to start the list with GFI LanGuard. You can use it to scan both small and large networks, in search of software vulnerabilities and unpatched or unlicensed applications. Information coming from up to 60,000 devices, running on Windows, Mac OS or Linux, will be shown in a centralized web console, so you’ll be able to see the state of your whole network at any moment and from any location.

With centralized patch management and network auditing, GFI LanGuard prevents potential compliance issues, but if you’re a sysadmin the fact that all machines are patched and secured will surely seem like a more important advantage. But, don’t take our word for it, download the free 30-day trial and try it out.
Температурные показатели
Недавно мои коллеги рассказывали о мониторинге холодоснабжения в машинных залах, где упомянули, что на каждый холодный коридор приходится по три температурных датчика. Эти датчики снимают общие показатели по коридору и позволяют судить о работе самой охлаждающей системы.
Для мониторинга сетевой инфраструктуры нужно знать показания температурных датчиков с каждой единицы оборудования. Это позволяет выявлять и устранять не только возможные перегревы хостов, но и определять на ранней стадии локальные перегревы стоек.
Для получения статуса устройства мы отправляем запрос вида snmpwalk <параметры> <устройство> | grep <что ищем> и получаем список всех OID по заданным фильтрам.

Изучив вывод, делаем более детальный запрос:

И еще более детальный:

Выбираем параметры NP1 и NP2
В итоге мы получаем OID 1.3.6.1.4.1.9.9.91.1.1.1.1.4.index и можем отследить показания нужного температурного датчика. На нашем примере – значение 590, т. е. 59 градусов по Цельсию.
В графическом представлении Nagios результаты опроса выглядят так:

На скриншоте мы видим следующее:
- Temperature 0/0, 0/1, 0/2 – датчики линейных карт маршрутизатора ASR9006;
- RSP – датчик карты Route Switch Processor;
- RSP/CPU – датчик температуры CPU карты Route Switch Processor.
Мониторинг оперативной памяти
Одна из самых опасных ситуаций в случае с оперативной памятью – утечка (memory leak)
Предупреждать и устранять ее важно своевременно, так как в небольших интервалах (день, неделя) медленное, но неотвратимое уменьшение свободной памяти можно просто не заметить
Частично решить эту проблему позволяет сбор долгосрочной статистики в Cacti. Мы можем отследить тенденцию к переполнению памяти и запланировать технологическое окно для перезагрузки оборудования. К сожалению, в большинстве случаев это единственный абсолютный метод «лечения» утечки.
Вот еще один пример из жизни нашей сети:
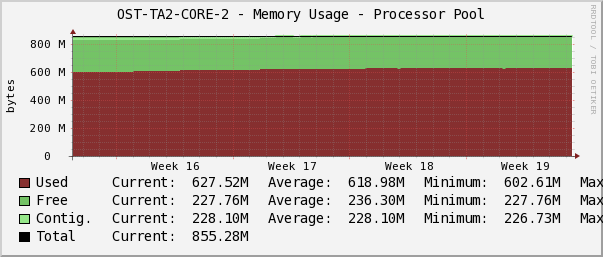
При очередном анализе показателей мониторинга инженеры обнаружили динамику уменьшения объема свободной памяти на одном из коммутаторов. Изменения были почти незаметны на коротких интервалах времени, но, если увеличить масштаб времени, скажем до месяца, появлялся тренд на плавное уменьшение свободной памяти. При заполнении памяти последствия для коммутатора могут быть непредсказуемы, вплоть до странностей в поведении протоколов маршрутизации. Например, часть маршрутов может перестать анонсироваться своему соседу. Или случайным образом начнет отказывать peer-link на системе VSS.
Ситуация, описанная выше, закончилась вполне благополучно. Мы согласовали с клиентами техокно и перегрузили коммутатор.
Итак, продолжим. Графики Cacti помогают определить точное время начала утечки, и, сопоставив логи, мы находим и «лечим» причину.
Делаем запрос загрузки оперативной памяти:
- OID: 1.3.6.1.4.1.9.9.221.1.1.1.1.18.index
- Ответ: iso.3.6.1.4.1.9.9.221.1.1.1.1.18.52690955.1 = Counter64: 2734644292
Значение указывает количество байтов из пула памяти, используемое операционной системой.
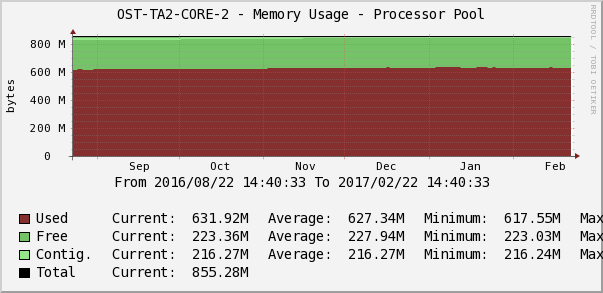
Статистика загрузки оперативной памяти в Cacti
Дежурный инженер следит за тем, чтобы не было аномальных перепадов или тренда на постоянное заполнение свободной памяти по параметру Memory Usage. График в Cacti показывает память под процессы, ввод/вывод, общую память, количество свободной/занятой памяти.
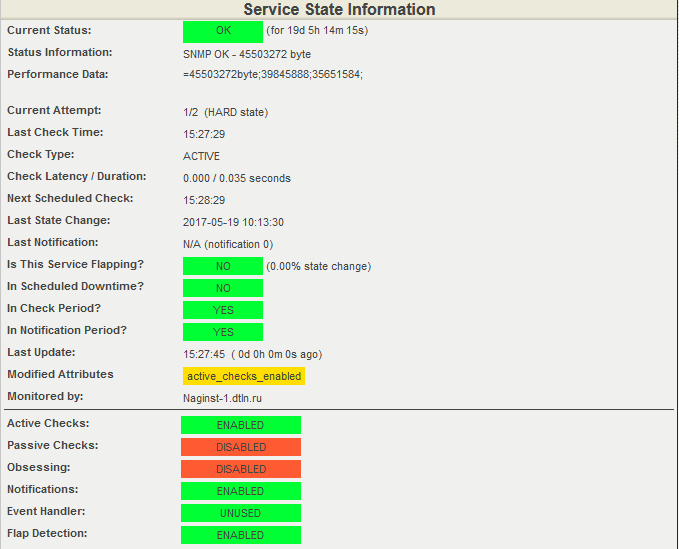
Текущее значение свободной оперативной памяти коммутатора – выгрузка из Nagios
В момент создания скриншота было свободно 45503272 байт ОП, установлены пороги срабатывания: для WARNING — в интервале от 35651584 до 39845888 байт, для CRITICAL — от 0 до 35651584 байт.
PRTG Network Monitor Freeware
PRTG Network Monitor monitors network availability and network usage using a variety of protocols including SNMP, Netflow, and WMI. It is a powerful tool that offers an easy to use web-based interface and apps for iOS and Android. Amongst others, PRTG Network Monitor’s key features include:
(1) Comprehensive Network Monitoring which offers more than 170 sensor types for application monitoring, virtual server monitoring, SLA monitoring, QoS monitoring
(2) Flexible Alerting, including nine different notification methods, status alerts, limit alerts, threshold alerts, conditional alerts, and alert scheduling
(3) In-Depth Reporting, including the ability to create reports in HTML/PDF format, scheduled reports, as well as pre-defined reports (e.g., Top 100 Ping Times) and report templates.
Note: The Freeware version of PRTG Network Monitor is limited to 100 sensors.

When you launch PRTG Network Monitor, head straight to the configuration wizard to get started. This wizard will run you through the main configuration settings required to get the application up and running, including the adding of servers to monitors and which sensors to use.
Просмотр неполадокView a problem
По умолчанию Azure позволяет осуществлять связь по всем портам между виртуальными машинами в одной виртуальной сети.By default, Azure allows communication over all ports between VMs in the same virtual network. Со временем вы или кто-либо из вашей организации может переопределить правила по умолчанию Azure, непреднамеренно вызвав сбои в связи.Over time, you, or someone in your organization, might override Azure’s default rules, inadvertently causing a communication failure. Выполните следующие шаги, чтобы инициировать неполадку со связью, а затем снова просмотрите монитор подключения.Complete the following steps to create a communication problem and then view the connection monitor again:
-
В поле поиска в верхней части портала введите myResourceGroup.In the search box at the top of the portal, enter myResourceGroup. Когда группа ресурсов myResourceGroup появится в результатах поиска, выберите ее.When the myResourceGroup resource group appears in the search results, select it.
-
Выберите группу безопасности сети myVm2-nsg.Select the myVm2-nsg network security group.
-
Выберите Правила безопасности для входящего трафика, а затем щелкните Добавить, как показано на следующем рисунке.Select Inbound security rules, and then select Add, as shown in the following picture:
-
Правило AllowVnetInBound — это правило по умолчанию, позволяющее осуществлять связь между всеми виртуальными машинами в виртуальной сети.The default rule that allows communication between all VMs in a virtual network is the rule named AllowVnetInBound. Создайте правило с более высоким приоритетом (меньшее число), чем правило AllowVnetInBound, которое отклоняет входящую связь через порт 22.Create a rule with a higher priority (lower number) than the AllowVnetInBound rule that denies inbound communication over port 22. Выберите или введите приведенные ниже сведения, примите значения по умолчанию и щелкните Добавить.Select, or enter, the following information, accept the remaining defaults, and then select Add:
ПараметрSetting ЗначениеValue Диапазоны портов назначенияDestination port ranges 2222 ДействиеAction ЗапретDeny ПриоритетPriority 100100 ИмяName DenySshInboundDenySshInbound -
Так как монитор подключения выполняет проверку с интервалом 60 секунд, подождите несколько минут, а затем в левой части портала выберите Наблюдатель за сетями, затем — Монитор подключения и монитор myVm1-myVm2(22) .Since connection monitor probes at 60-second intervals, wait a few minutes and then on the left side of the portal, select Network Watcher, then Connection monitor, and then select the myVm1-myVm2(22) monitor again. Теперь результаты отличаются от показанных на следующем рисунке.The results are different now, as shown in the following picture:
В столбце состояния сетевого интерфейса myvm2529 отображается красный восклицательный знак.You can see that there’s a red exclamation icon in the status column for the myvm2529 network interface.
-
Чтобы узнать, почему состояние изменилось, выберите 10.0.0.5, как на предыдущем рисунке.To learn why the status has changed, select 10.0.0.5, in the previous picture. Монитор подключения сообщает вам следующую причину сбоя связи: Traffic blocked due to the following network security group rule: UserRule_DenySshInbound (Трафик заблокирован из-за следующего правила группы безопасности сети: UserRule_DenySshInbound).Connection monitor informs you that the reason for the communication failure is: Traffic blocked due to the following network security group rule: UserRule_DenySshInbound.
Если вы не знали, что кто-то реализовал правило безопасности, которое вы создали на шаге 4, с помощью монитора подключений вы узнаете, что это правило вызывает неполадки со связью.If you didn’t know that someone had implemented the security rule you created in step 4, you’d learn from connection monitor that the rule is causing the communication problem. Затем вы можете изменить, переопределить или удалить это правило, чтобы восстановить связь между виртуальными машинами.You could then change, override, or remove the rule, to restore communication between the VMs.
Wireshark
This list wouldn’t be complete without the ever-popular Wireshark. Wireshark is an interactive network protocol analyzer and capture utility. It provides for in-depth inspection of hundreds of protocols and runs on multiple platforms.

When you launch Wireshark, choose which interface you want to bind to and click the green shark fin icon to get going. Packets will immediately start to be captured. Once you’ve collected what you need, you can export the data to a file for analysis in another application or use the inbuilt filter to drill down and analyze the captured packets at a deeper level from within Wireshark itself.
Are there any free tools not on this list that you’ve found useful and would like to share with the community?
Splunk
Splunk is a data collection and analysis platform that allows you to monitor, gather and analyze data from different sources on your network (e.g., event logs, devices, services, TCP/UDP traffic, etc.). You can set up alerts to notify you when something is wrong or use Splunk’s extensive search, reporting, and dashboard features to make the most of the collected data. Splunk also allows you to install ‘Apps’ to extend system functionality.
Note: When you first download and install Splunk, it automatically installs the Enterprise version for you to trial for 60 days before switching to the Free version. To switch to the free version straight away, go to Manager > Licensing.

When you login to the Splunk web UI for the first time, add a data source and configure your indexes to get started. Once you do this, you can then create reports, build dashboards, and search and analyze data.
Возможности и область действия мониторинга сетевых устройствNetwork device monitoring capabilities and scope
Operations Manager обеспечивает следующие возможности наблюдения за обнаруженными сетевыми устройствами:Operations Manager provides the following monitoring for discovered network devices:
-
работоспособность подключения — подключение проверяется с обеих сторон;Connection health — Based on looking at both ends of a connection
-
работоспособность виртуальной ЛС — проверяется состояние работоспособности коммутаторов в виртуальной ЛС;VLAN health — Based on health state of switches in VLAN
-
работоспособность группы HSRP — проверяется состояние работоспособности отдельных конечных точек HSRP;HSRP group health — Based on health state of individual HSRP end points
-
порт или интерфейс:Port/Interface
-
работает или не работает (рабочее и административное состояния);Up/down (operational & administrative status)
-
объемы входящего и исходящего трафика (включая частоту прерываний, широковещательной рассылки, контроля несущей, конфликтов, проверки циклической контрольной суммы, ошибки отклонения, ошибки контрольной последовательности кадра, кадры, пакеты с недопустимо большой или недопустимо малой длиной, пропущенные пакеты, ошибки передачи и приема на MAC-уровне, скорость очереди);Volumes of inbound/outbound traffic (includes abort, broadcast, carrier sense, collision, CRC rates, discard, error, FCS error, frame, giants, runts, ignored, MAC transmit/receive error, queue rates)
-
степень использования (%);% Utilization
-
интенсивность отбрасывания и широковещательной передачи;Drop and broadcast rates
Примечание
порты, подключенные к компьютеру, не отслеживаются, выполняется только наблюдение за портами, которые подключены к другим сетевым устройствам.Ports that are connected to a computer are not monitored; only ports that connect to other network devices are monitored. Можно выполнять наблюдение за портом, подключенным к компьютеру, который не управляется агентом той же самой группы, добавив порт в группу «Критические сетевые адаптеры».You can monitor a port that is connected to a computer that is not agent-managed in the same management group by adding the port to the Critical Network Adapters Group.
-
-
процессор — процент использования (для некоторых сертифицированных устройств);Processor — % Utilization (for some certified devices)
-
память — включая высокий уровень использования памяти и буфера, чрезмерную фрагментацию и сбои выделения буфера (для некоторых сертифицированных устройств);Memory — including high utilization, high buffer utilization, excessive fragmentation, and buffer allocation failures (for some certified devices)
-
подробные счетчики памяти (только для устройств Cisco);In-depth memory counters (Cisco devices only)
-
свободная память.Free memory
-
Примечание
По умолчанию отключены некоторые из возможностей мониторинга.Some monitoring capabilities are disabled by default. Дополнительные сведения см. в статье Как настроить мониторинг сетевых устройств.For more information, see How to configure monitoring of network devices.
Operations Manager поддерживает выполнение наблюдения за следующим количеством сетевых устройств:Operations Manager supports monitoring of the following number of network devices:
-
2000 сетевых устройств (приблизительно 25 000 отслеживаемых портов), управляемых двумя пулами ресурсов;2000 network devices (approximately 25,000 monitored ports) managed by two resource pools
-
1 000 сетевых устройств (приблизительно 12 500 отслеживаемых портов), управляемых пулом ресурсов, который имеет три или более серверов управления;1000 network devices (approximately 12,500 monitored ports) managed by a resource pool that has three or more management servers
-
500 сетевых устройств (приблизительно 6 250 отслеживаемых портов), управляемых пулом ресурсов, который имеет два или более серверов шлюзов.500 network devices (approximately 6,250 monitored ports) managed by a resource pool that has two or more gateway servers
Как заполняли inventory
Мы уже не мы, мы — сетевики.inventory.pySNMPiteminventory
- Недостаточная вложенность действий, т.к. часто необходимо вытянуть значение по SNMP и использовать результат в следующем запросе.
- Запускать один раз в день сбор данных по всем узлам внешним скриптом не нагружает основную деятельность мониторинга и не образуется очередь по item’ам
- Есть данные, которые не собрать по SNMP
BGP-AS-BASE.cfgASBGPASSNMP
запрашиваем у роутера подсети по OID 1.3.6.1.2.1.4.20.1.1 и маски подсетей по OID 1.3.6.1.2.1.4.20.1.3 в одном запросе. Обрабатываем, переводим в вид x.x.x.x/xx и записываем в ячейку host_networks.
запрашиваем данные о ip адресах BGP пиров, а также их ASN, находим в созданной нами базе имя провайдера по номеру. Записываем их в поля host_router и host_netmask
Важно сразу сделать ограничение на 38 символов, т.к. эти поля не поддерживают большее количество
У нас названия полей в БД не всегда совпадают с данными, которые они хранят, т.к. использовали уже существующие поля в БД Zabbix, чтобы не возится с созданием новых полей в таблице. Правильные названия полей правили в WEB’е, путаницы не было.
выгружаем данные по вендору, модели и софту оборудования. Парсим, пишем в переменные. Конструкция, связанная с записью модели железки связана с тем, что у Cisco в некоторых моделях название пишется в другой OID(чаще всего для шасси), поэтому пришлось сделать дополнительную проверку данных.
try-exceptdate_hw_expiryJSONinventory.pymultiprocessingSAP IDupdate
Summary
host.gethost.createhost.updatepysnmpxlrdzabbix.apixmlipaddressjsonxlrdxmlpysnmpOIDiso.3.6.1.2.1.4.20.1.1iso.3.6.1.2.1.4.20.1.3iso.3.6.1.2.1.15.3.1.7iso.3.6.1.2.1.15.3.1.9iso.3.6.1.2.1.47.1.1.1.1.13.1iso.3.6.1.2.1.47.1.1.1.1.10.1iso.3.6.1.2.1.47.1.1.1.1.12.1iso.3.6.1.2.1.1.1.0iso.3.6.1.2.1.47.1.1.1.1.7.1Dashboard«Workview»






