Урок №31. целочисленные типы данных: short, int и long
Содержание:
Введение
Мир вокруг можно моделировать различными способами. Самым естественным из них является представление о нём, как о наборе объектов. У каждого объекта есть свои свойства.
Например, для человека это возраст, пол, рост, вес и т.д. Для велосипеда – тип, размер колёс, вес, материал, изготовитель и пр. Для товара в магазине – идентификационный номер,
название, группа, вес, цена, скидка и т.д.
У классов объектов набор этих свойств одинаковый: все собаки могут быть описаны, с той или иной точностью, одинаковым набором свойств, но значения этих свойств будут разные.
Все самолёты обладают набором общих свойств в пределах одного класса. Если же нам надо более точное описание, то можно выделить подклассы: самолёт амфибии, боевые
истребители, пассажирские лайнеры – и в пределах уже этих классов описывать объекты.
Например, нам необходимо хранить информацию о сотрудниках компании. Каждый сотрудник, в общем, обладает большим количеством разных свойств.
Мы выберем только те, которые нас интересуют для решения прикладной задачи: пол, имя, фамилия, возраст, идентификационный номер. Для работы с таким
объектом нам необходима конструкция, которая бы могла агрегировать различные типы данных под одним именем. Для этих целей в си используются структуры.
The void Type
The void type specifies that no value is available. It is used in three kinds of situations −
| Sr.No. | Types & Description |
|---|---|
| 1 |
Function returns as void There are various functions in C which do not return any value or you can say they return void. A function with no return value has the return type as void. For example, void exit (int status); |
| 2 |
Function arguments as void There are various functions in C which do not accept any parameter. A function with no parameter can accept a void. For example, int rand(void); |
| 3 |
Pointers to void A pointer of type void * represents the address of an object, but not its type. For example, a memory allocation function void *malloc( size_t size ); returns a pointer to void which can be casted to any data type. |
Previous Page
Print Page
Next Page
Ссылки и указатели
Указатели — главная особенность языка, они открывают широкие возможности для работы с памятью. Они передают информацию о расположении другой переменной в памяти. Перед использованием они, подобно другим переменным, объявляются в виде type *pointer. Type — тип переменной, pointer — имя указателя.

Чтобы задать указателю значение другой переменной, используются ссылки. Они передают адрес переменной и используются в качестве безопасного указателя.
Ссылки позволяют работать с указателем, как с объектом.

В данном случае &a вернет 0x7340cad2a25c, *pointer — 2, но pointer без “*” — 0x7340cad2a25c.
Изменяя значение, мы не меняем его адрес, поэтому pointer так же будет ссылаться на 0x7340cad2a25c, но при этом изменит свое значение.
Указатель на другой указатель объявляется в виде:
Указатель на массив работает немного другим способом.
Мы объявили массив целых чисел и указатель int a.
В данном случае указатель указывает не на сам массив, а только на его первый элемент. Таким образом,
эквивалентны между собой.
Теперь можно сослаться на третий элемент массива с помощью выражения
или
На примере выше можно заметить, что сложение в указателях работает другим образом. К ним могут применяться различные арифметические операции.
Указатель на массив указывается так:
Но массив указателей выглядит так:
Основные типы данных
Базовые типы данных в C++ можно разбить на несколько групп
Знаковый тип. Переменные знакового типа могут использоваться для хранения одного символа. Самый простой тип char, размер которого равен 1 байт. Также имеются типы для представления
знаков, размером больше одного байта
| Название | Назначение |
|---|---|
| char | Всегда 1 байт. Минимум 8 бит |
| char16_t | 2-х байтный символ |
| char32_t | 4-х байтный символ |
| wchar_t | Используется для представления самого широкого из поддерживаемых наборов символов |
Вообще-то эти типы есть и в си, мы не останавливались подробно на изучении представления строк.
Целочисленные типы данных. Как и в си, могут обладать модификаторами signed и unsigned. Как и в си, основными типами являются char, int, long и long long. Ничего нового здесь
не появилось.
Числа с плавающей точкой. Представлены типами float, double и long double. Ничего нового по сравнению с си.
Все описанные выше типы называют также арифметическими. Кроме них существует ещё пустой тип – void (также ничего нового по сравнению с си) и нулевой указатель.
Теперь, вместо NULL с его удивительными свойствами, появился новый фундаментальный тип nullptr_t с единственным значением nullptr, который хранит нулевой указатель
и равен только сам себе. При этом, он может быть приведён к нулевому указателю нужного типа.
В си++ введён булев тип. Он хранит всего два возможных значения true и false.
Си++ поддерживает также множество составных типов данных, которые будут рассмотрены позднее.
Самоприменение
Тип может быть параметризован другим типом, в соответствии с принципами абстракции и . Например, для реализации функции сортировки последовательностей нет необходимости знать все свойства составляющих её элементов — необходимо лишь, чтобы они допускали операцию сравнения — и тогда составной тип «последовательность» может быть определён как параметрически полиморфный. Это означает, что его компоненты определяются с использованием не конкретных типов (таких как «целое» или «массив целых»), а параметров-типов. Такие параметры называются переменными типа (англ. type variable) — они используются в определении полиморфного типа так же, как параметры-значения в определении функции. Подстановка конкретных типов в качестве фактических параметров для полиморфного типа порождает мономорфный тип. Таким образом, параметрически полиморфный тип представляет собой конструктор типов, то есть оператор над типами в арифметике типов.
Определение функции сортировки как параметрически полиморфной означает, что она сортирует абстрактную последовательность, то есть последовательность из элементов некоторого (неизвестного) типа. Для функции в этом случае требуется знать о своём параметре лишь два свойства — то, что он представляет собой последовательность, и что для её элементов определена операция сравнения. Рассмотрение параметров процедурным, а не декларативным, образом (то есть их использование на основе поведения, а не значения) позволяет использовать одну функцию сортировки для любых последовательностей — для последовательностей целых чисел, для последовательностей строк, для последовательностей последовательностей булевых значений, и так далее — и существенно повышает коэффициент повторного использования кода. Ту же гибкость обеспечивает и динамическая типизация, однако, в отличие от параметрического полиморфизма, первая приводит к накладным расходам. Параметрический полиморфизм наиболее развит в языках, типизированных по Хиндли — Милнеру, то есть потомках языка ML. В объектно-ориентированном программировании параметрический полиморфизм принято называть обобщённым программированием.
Несмотря на очевидные преимущества параметрического полиморфизма, порой возникает необходимость обеспечивать различное поведение для разных одного общего типа, либо аналогичное поведение для несовместимых типов — то есть в тех или иных формах ad-hoc-полиморфизма. Однако, ему не существует математического обоснования, так что требование типобезопасности долгое время затрудняло его использование. Ad-hoc-полиморфизм реализовывался внутри параметрически полиморфной системы типов посредством различных трюков. Для этой цели использовались либо , либо параметрические модули (функторы либо так называемые «значения, индексированные типами» (англ. type-indexed values), которые, в свою очередь, также имеют ряд реализаций. Классы типов, появившиеся в языке Haskell, предоставили более изящное решение этой проблемы.
Подробнее по этой теме см. Класс типов.
Если рассматриваемой информационной сущностью является тип, то назначение ей типа приведёт к понятию «тип типа» («метатип»). В теории типов это понятие носит название «род типов» (англ. kind of a type или type kind). Например, род «» включает все типы, а род «» включает все унарные конструкторы типов. Рода явным образом применяются при полнотиповом программировании — например, в виде конструкторов типов в языках семейства ML.
Подробнее по этой теме см. Род (теория типов).
Расширение безопасной полиморфной системы типов классами и родами типов сделало Haskell первым типизированным в полной мере языком. Полученная система типов оказала влияние на другие языки (например, Scala, Agda).
Ограниченная форма метатипов присутствует также в ряде объектно-ориентированных языков в форме метаклассов. В потомках языка Smalltalk (например, Python) всякая сущность в программе является объектом, имеющим тип, который сам также является объектом — таким образом, метатипы являются естественной частью языка. В языке C++ отдельно от основной системы типов языка реализована подсистема RTTI, также предоставляющая информацию о типе в виде специальной структуры.
Динамическое выяснение метатипов называется отражением (а также рефлексивностью или интроспекцией).
Операции со строками
Большинство операций языка Си, имеющих дело со строками, работает с указателями. Для размещения в оперативной памяти строки символов необходимо:
- выделить блок оперативной памяти под массив;
- проинициализировать строку.
Для выделения памяти под хранение строки могут использоваться функции динамического выделения памяти. При этом необходимо учитывать требуемый размер строки:
char *name;name = (char*)malloc(10);scanf(«%9s», name);
Для ввода строки использована функция scanf(), причем введенная строка не может превышать 9 символов. Последний символ будет содержать ‘\0’.
Функции ввода строк
Для ввода строки может использоваться функция scanf(). Однако функция scanf() предназначена скорее для получения слова, а не строки. Если применять формат «%s» для ввода, строка вводится до (но не включая) следующего пустого символа, которым может быть пробел, табуляция или перевод строки.
Для ввода строки, включая пробелы, используется функция
char * gets(char *);
char * gets_s(char *);
Enter
Функции вывода строк
Для вывода строк можно воспользоваться рассмотренной ранее функцией
printf(«%s», str); // str — указатель на строку
или в сокращенном формате
printf(str);
int puts (char *s);
которая печатает строку s и переводит курсор на новую строку (в отличие от printf()). Функция puts() также может использоваться для вывода строковых констант, заключенных в кавычки.
Для ввода символов может использоваться функция
char getchar();
Функция вывода символов
Для вывода символов может использоваться функция
char putchar(char);
Пример
1234567891011121314151617181920212223242526
#include <stdio.h>#include <string.h>#include <stdlib.h>int main() { char s, sym; int count, i; system(«chcp 1251»); system(«cls»); printf(«Введите строку : «); gets_s(s); printf(«Введите символ : «); sym = getchar(); count = 0; for (i = 0; s != ‘\0’; i++) { if (s == sym) count++; } printf(«В строке\n»); puts(s); // Вывод строки printf(«символ «); putchar(sym); // Вывод символа printf(» встречается %d раз», count); getchar(); getchar(); return 0;}
Результат выполнения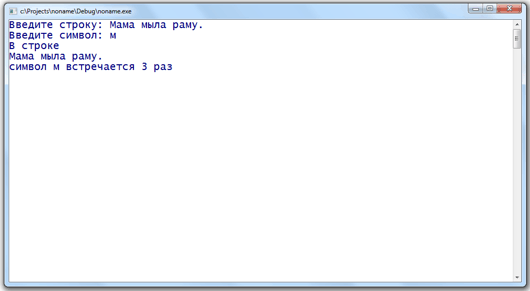
Строковые константы
Строковая константа — это последовательность символов, заключенная в кавычки, например:
«Это строковая константа»
Кавычки не входят в строку, а лишь ограничивают её. Технически строковая константа представляет собой массив символов, и по этому признаку может быть отнесена к разряду сложных объектов языка Си.
В конце каждой строковой константы компилятор помещает ‘\0’ (нуль-символ), чтобы программе было возможно определить конец строки. Такое представление означает, что размер строковой константы не ограничен каким-либо пределом, но для определения длины строковой константы её нужно полностью просмотреть.
Поскольку строковая константа состоит из символов, то она имеет тип char. Количество ячеек памяти, необходимое для хранения строковой константы на 1 больше количества символов в ней (1 байт используется для хранения нуль-символа).
Символьная константа ‘x’ и строка из одного символа «x» — не одно и то же. Символьная константа — это символ, используемый для числового представления буквы x, а строковая константа «x» содержит символ ‘x’ и нуль-символ ‘\0’ и занимает в памяти 2 байта. Если в программе строковые константы записаны одна за другой через разделители, то при выполнении программы они будут размещаться в последовательных ячейках памяти.
Форматирование строк
Часто возникает ситуация, когда необходимо создать строку, подставив в нее определенные значения, полученные во время выполнения программы. Подстановка данных в таком случае выполняется при помощи форматирования строк, сделать это можно несколькими способами.
Оператор %
Строки в Python обладают встроенной операцией, к которой можно получить доступ оператором %, что дает возможность очень просто делать форматирование. Самый простой пример – когда для подстановки нужен только один аргумент, значением будет он сам:
Если же для подстановки используется несколько аргументов, то значением будет кортеж со строками:
Как видно из предыдущего примера, зависимо от типа данных для подстановки и того, что требуется получить в итоге, пишется разный формат. Наиболее часто используются:
- ‘%d’, ‘%i’, ‘%u – десятичное число;
- ‘%c’ – символ, точнее строка из одного символа или число – код символа;
- ‘%r’ – строка (литерал Python);
- ‘%s’ – строка.
Такой способ форматирования строк называет «старым» стилем, который в Python 3 был заменен на более удобные способы.
str.format()
В Python 3 появился более новый метод форматирования строк, который вскоре перенесли и в Python 2.7. Такой способ избавляет программиста от специального синтаксиса %-оператора. Делается все путем вызова .format() для строковой переменной. С помощью специального символа – фигурных скобок – указывается место для подстановки значения, каждая пара скобок указывает отдельное место для подстановки, значения могут быть разного типа:
В Python 3 форматирование строк с использованием «нового стиля» является более предпочтительным по сравнению с использованием %-стиля, так как предоставляет более широкие возможности, не усложняя простые варианты использования.
f-строки (Python 3.6+)
В Python версии 3.6 появился новый метод форматирования строк – «f-строки», с его помощью можно использовать встроенные выражения внутри строк:
Такой способ форматирования очень мощный, так как дает возможность встраивать выражения:
Таким образом, форматирование с помощью f-строк напоминает использование метода format(), но более гибкое, быстрое и читабельное.
Стандартная библиотека Template Strings
Еще один способ форматирования строк, который появился еще с выходом Python версии 2.4, но так и не стал популярным – использование библиотеки Template Strings. Есть поддержка передачи значения по имени, используется $-синтаксис как в языке PHP:
Присваивание
Для присваивания в языке С служит знак «=» – не путать со знаком сравнения двух чисел. При использовании данного знака производится вычисление выражение, стоящего справа от знака присваивания, и полученное значение присваивается переменной, стоящей слева от знака присваивания. При этом старое значение переменной стирается и заменяется на новое.
Примеры: y = 6 + 8; // сложить значения 6 и 8, // результат присвоить переменной y (записать в переменную y)
c = b + 5; // прибавить 5 к значению, хранящемуся в переменной b, // полученный результат присвоить переменной c (записать в переменную b)
d = d + 2; // прибавить 2 к значению, хранящемуся в переменной d, // полученный результат присвоить переменной d (записать в переменную d)
В правой части значение переменной может быть использовано несколько раз, например:
z = x * x + 5 * x;
Что использовать: ‘\n’ или std::endl?
Вы могли заметить, что в последнем примере мы использовали для перемещения курсора на следующую строку. Но мы могли бы использовать и . Какая между ними разница? Сейчас разберемся.
При использовании std::cout, данные для вывода могут помещаться в буфер, т.е. std::cout может не отправлять данные сразу же на вывод. Вместо этого он может оставить их при себе на некоторое время (в целях улучшения производительности).
И , и оба переводят курсор на следующую строку. Только ещё гарантирует, что все данные из буфера будут выведены, перед тем, как продолжить.
Так когда же использовать , а когда ?
Используйте , когда нужно, чтобы ваши данные выводились сразу же (например, при записи в файл или при обновлении индикатора состояния какого-либо процесса)
Обратите внимание, это может повлечь за собой незначительное снижение производительности, особенно если запись на устройство происходит медленно (например, запись файла на диск)
Используйте во всех остальных случаях.
Строки
В С++ нет базового типа строка. Однако есть стандартная библиотека string, которая предоставляет класс для работы со строками.
#include <iostream>
#include <string>
void main() {
std::string first_name = "Vasya";
std::string last_name = { "Pupkin" };
//конкатенация строк
auto full_name = first_name + " " + last_name;
std::string *department = new std::string("Department of copying and scanning");
std::cout << full_name << std::endl;
//сравнение строк
std::string a = "A";
std::string b = "B";
if (first_name.compare(last_name) > 0) {
std::cout << a + " > " + b << std::endl;
} else {
std::cout << a + " < " + b << std::endl;
}
//подстрока
std::string subs = department->substr(0, 10);
std::cout << subs << std::endl;
//замена подстроки
std::cout << last_name.replace(0, 1, "G") << std::endl;
//вставка
std::string new_department = department->insert(department->length(), " and shreddering");
std::cout << new_department << std::endl;
delete department;
system("pause");
}
Со стандартной библиотекой string познакомимся поздее более подробно.
Q&A
Всё ещё не понятно? – пиши вопросы на ящик
Приведение типов
Стандартом поведение при приведении одной структуры к другой не определено. Это значит, что даже если структуры имеют одинаковые поля, то нельзя явно
кастовать одну структуру до другой.
#include <conio.h>
#include <stdio.h>
struct Point {
int x;
int y;
};
struct Apex {
int a;
int b;
};
void main() {
struct Point point = {10, 20};
struct Apex apex;
apex = (*(struct Apex*)(&point));
printf("a = %d, b = %d", apex.a, apex.b);
getch();
}
Этот пример работает, но это хак, которого необходимо избегать. Правильно писать так
void main() {
struct Point point = {10, 20};
struct Apex apex;
apex.a = point.x;
apex.b = point.y;
printf("a = %d, b = %d", apex.a, apex.b);
getch();
}
Привести массив к структуре (или любому другому типу) по стандарту также невозможно (хотя в различных компиляторах есть для этого инструменты).
Но в си возможно всё.
#include <conio.h>
#include <stdio.h>
struct Point {
int x;
int y;
};
void main() {
struct Point point = {10, 20};
int x = {300, 400, 500};
point = (*(struct Point*)(x));
printf("a = %d, b = %d", point.x, point.y);
getch();
}
Но запомните, что в данном случае поведение не определено.






