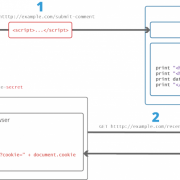
Как мы адаптировали стек elk для мониторинга и анализа ошибок на java и .net проектах
Содержание:
Чем хороши Elasticsearch с Logsatsh и Kibana в Big Data: 5 главных преимуществ
Основными достоинствами ELK-стека считаются следующие :
- Масштабируемость – кластер Elasticsearch (ES) расширяется «на лету» добавлением новых серверов. При этом распределение нагрузки по узлам происходит автоматически.
- Отказоустойчивость — в случае сбоя кластерных узлов данные не потеряются, а будут перераспределены, и поисковая система сама продолжит работу. Операционная стабильность достигается ведением логов на каждое изменение данных в хранилище сразу на нескольких узлах кластера.
- Гибкость поисковых фильтров, включая нечеткий поиск, возможности работы с восточными языками (китайский, японский, корейский) и мультиарендность, когда в рамках одного объекта ES можно динамически организовать несколько различных поисковых систем. Благодаря наличию встроенных анализаторов текста Elasticsearch автоматически выполняет токенизацию, лемматизацию, стемминг и прочие преобразования текста для решения NLP-задач, связанных с поиском данных.
- Управляемость ES по HTTP с помощью JSON-запросов за счет REST API и визуального веб-интерфейса Kibana.
- Универсальность – Logsatsh в потоковом режиме работает одновременно со множеством разных источников данных (СУБД, файлы, системные логи, веб-приложения и пр.), фильтруя и преобразуя их для отправки в хранилище ES. А NoSQL-природа Elasticsearch (отсутствие схемы) позволяет загружать в него JSON-объекты, которые автоматически индексируются и добавляются в базу поиска. Это позволяет ускорить прототипирование поисковых Big Data решений.
Шаг 1 — Установка и настройка Elasticsearch
Компоненты комплекса Elastic отсутствуют в репозиториях пакетов Ubuntu по умолчанию. Однако их можно установить с помощью APT после добавления списка источников пакетов Elastic.
Все пакеты комплекса Elastic подписаны ключом подписи Elasticsearch для защиты вашей системы от поддельных пакетов. Ваш диспетчер пакетов будет считать надежными пакеты, для которых проведена аутентификация с помощью ключа. На этом шаге вы импортируете открытый ключ Elasticsearch GPG и добавить список источников пакетов Elastic для установки Elasticsearch.
Для начала запустите следующую команду для импорта открытого ключа Elasticsearch GPG в APT:
Затем обновите списки пакетов, чтобы APT мог прочитать новый источник Elastic:
Установите Elasticsearch с помощью следующей команды:
После завершения установки Elasticsearch используйте предпочитаемый текстовый редактор для редактирования главного файла конфигурации Elasticsearch с именем . Мы будем использовать :
Примечание. Файл конфигурации Elasticsearch имеет формат YAML, и это значит, что отступы имеют большое значение! Не добавляйте никакие дополнительные пробелы при редактировании этого файла.
Elasticsearch прослушивает весь трафик порта . Вы можете захотеть ограничить внешний доступ к вашему экземпляру Elasticsearch, чтобы посторонние не могли читать ваши данные или отключать ваш кластер Elasticsearch через REST API. Найдите строку с указанием , уберите с нее значок комментария и замените значение на , чтобы она выглядела следующим образом:
/etc/elasticsearch/elasticsearch.yml
Сохраните и закройте файл , нажав , а затем и , если вы используете . Затем запустите службу Elasticsearch с помощью :
Затем запустите следующую команду, чтобы активировать Elasticsearch при каждой загрузке сервера:
Вы можете протестировать работу службы Elasticsearch, отправив запрос HTTP:
Вы получите ответ, содержащий базовую информацию о локальном узле:
Мы настроили и запустили Elasticsearch, и теперь можем перейти к установке Kibana, следующего компонента комплекса Elastic.
Очистка устаревших данных
Разберем пример удаления логов, которые старше 30 дней. Для этого будем использовать Elasticsearch Curator. Для установки последнего переходим на страницу Curator Reference, выбираем текущую версию программного продукта и кликаем по Installation:
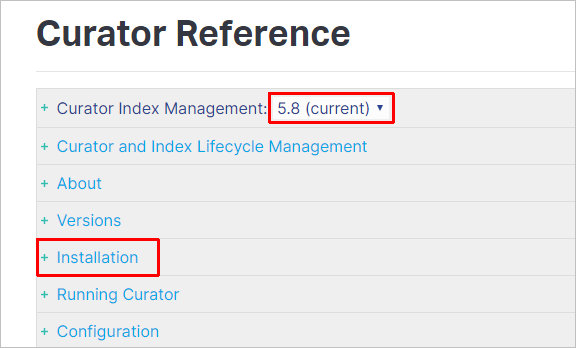
В открывшемся окне переходим на нужную инструкцию по установки (так как у нас CentOS, выбираем YUM Repository):
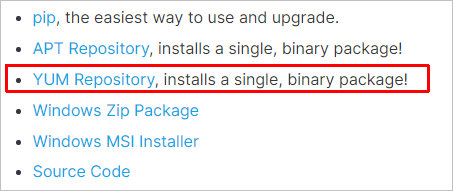
В открывшемся окне следуем инструкции — в моем случае, версия была 5.8.
Загружаем и устанавливаем публичный gpg-ключ, которым подписаны пакеты добавляемого репозитория:
rpm —import https://packages.elastic.co/GPG-KEY-elasticsearch
Создаем файл репозитория:
vi /etc/yum.repos.d/curator.repo
name=CentOS/RHEL 7 repository for Elasticsearch Curator 5.x packages
baseurl=https://packages.elastic.co/curator/5/centos/7
gpgcheck=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
* на момент написания статьи уже вышла версия CentOS 8, но куратор был только для 7. Вполне возможно, что в ближайшее время появится curator для новой версии операционной системы.
Выполняем установку командой yum:
yum install elasticsearch-curator
После установки куратора, создаем каталог для конфигурационных файлов:
mkdir /etc/curator
Создаем конфигурационный файл config.yml:
vi /etc/curator/config.yml
client:
hosts:
— 127.0.0.1
port: 9200
url_prefix:
use_ssl: False
certificate:
client_cert:
client_key:
ssl_no_validate: False
http_auth:
timeout: 30
master_only: False
* в данном файле нас интересует настройка hosts — мы указали, что curator должен подключаться к elasticsearch на локальном хосте (127.0.0.1) порту 9200.
vi /etc/curator/action.yml
actions:
1:
action: close
description: >-
Close indices older than 30 days (based on index name).
options:
ignore_empty_list: True
delete_aliases: False
disable_action: False
filters:
— filtertype: pattern
kind: prefix
value: filebeat-
— filtertype: age
source: name
direction: older
timestring: ‘%Y.%m.%d’
unit: days
unit_count: 30
2:
action: delete_indices
description: >-
Delete indices older than 30 days (based on index name).
options:
ignore_empty_list: True
disable_action: False
filters:
— filtertype: pattern
kind: prefix
value: filebeat-
— filtertype: age
source: name
direction: older
timestring: ‘%Y.%m.%d’
unit: days
unit_count: 30
Запускаем curator для удаления устаревших логов:
curator —config /etc/curator/config.yml /etc/curator/action.yml
Systems feeding into logstash
See 2015-08 Tech talk slides
Writing new filters is easy.
Supported log shipping protocols & formats («interfaces»)
Support of logs shipped directly from application to Logstash has been deprecated.
Please see Logstash/Interface for details regarding long-term supported log shipping interfaces.
Kubernetes
Kubernetes hosted services are taken care of directly by the kubernetes infrastructure which ships via rsyslog into the logstash pipeline. All a kubernetes service needs to do is log in a JSON structured format (e.g. bunyan for nodejs services) to standard output/standard error.
Systems not feeding into logstash
- EventLogging (of program-defined events with schemas), despite its name, uses a different pipeline.
- Varnish logs of the billions of pageviews of WMF wikis would require a lot more hardware. Instead we use Kafka to feed web requests into Hadoop. A notable exception to this rule: varnish user-facing errors (HTTP status 500-599) are sent to logstash to make debugging easier.
- MediaWiki logs usually go to both logstash and log files, but a few log channels aren’t. You can check which in in InitialiseSettings.php.
Each filter has a corresponding test after its name in tests/. Within the test file the fields map lists the fields common to all tests and are used to trigger a specific filter’s «if» conditions. The ignore key usually contains only @timestamp since that field is bound to change across invocations and can be safely ignored. The remainder of a test file is a list of testcases in the form of input/expected pairs. For «input» it is recommended to use yaml > to include verbatim JSON, whereas «expected» is usually yaml, although it can be also verbatim JSON if more convenient.
Установка curator
Для начала установим curator. Сделать это можно разными способами. Самый простой — из репозитория packages.elastic.co от авторов продукта. Подключим его в CentOS 7.
# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch # mcedit /etc/yum.repos.d/curator.repo
name=CentOS/RHEL 7 repository for Elasticsearch Curator 5.x packages baseurl=https://packages.elastic.co/curator/5/centos/7 gpgcheck=1 gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch enabled=1
Подключаем репозиторий в Debian 8/Ubuntu
# wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - # mcedit /etc/apt/sources.list.d/curator.list
deb https://packages.elastic.co/curator/5/debian stable main
Отдельный репозиторий для Debian 9
# deb https://packages.elastic.co/curator/5/debian9 stable main
Устанавливаем curtator:
# yum install elasticsearch-curator # apt update && apt install elasticsearch-curator
Так же curator можно установить через pip. Как установить pip в CentOS 7 я рассказывал отдельно. Для Debian/Ubuntu достаточно просто выполнить:
# apt install python-pip
Установка curator через pip:
# pip install elasticsearch-curator
Когда и зачем нужна интеграция Elasticsearch с Apache Kafka: 3 практических примера
Напомним, в ELK Stack компонент Logstash отвечает за сбор, преобразование и сохранение в общем хранилище данных из разных файлов, СУБД, логов и прочих мест в режиме реального времени. Это похоже на основное назначение Apache Kafka – распределенной стриминговой платформы, которая собирает и агрегирует большие данные разных форматов из множества источников. Возникает вопрос: зачем добавлять Kafka в ELK-стек, используя дополнительное средство сбора потоковых данных? Здесь можно выделить несколько сценариев :
- временная остановка кластера Elasticsearch (ES) с целью обновления версии или внесения других изменений. Чтобы не потерять данные, приходящие из разных систем, Kafka можно использовать в качестве временного буфера для сохранения информации. Когда ELK-кластер возобновит работу, Logstash продолжит собирать, преобразовывать и отправлять в ES пропущенные данные, считывая их из топиков Apache Kafka с того места, где случился останов.
- Выравнивание пропускной способности компонентов ELK, чтобы, например, при внезапном увеличении объема данных ES-кластер не «захлебнулся» от высокой скорости поступления новой информации. На практике такая ситуация может возникнуть в случае ошибки в обновленном Big Data приложении или аномальном непредвиденном росте пользовательской активности.
Таким образом, добавление Кафка в Эластик-стек позволяет не зависеть от мониторинга событий. Совместное использование FileBeat с Kafka дает возможность создавать разные топики для каждого сервиса, улучшая «реактивность» всей Big Data системы. Напомним, FileBeat – это легковесный серверный агент для отправки определенных типов рабочих данных в Elasticsearch. Он занимает использует гораздо меньше системных ресурсов, чем Logstash. Хотя функциональные возможности Logstash по вводу, фильтрации и выводу для сбора, обогащения и преобразования данных из различных источников гораздо больше, чем у FileBeat. Можно сказать, что Logstash «дороже», чем FileBeat.
Возвращаясь к преимуществам включения Kafka в ELK Stack, отметим, что любая команда разработчиков или администраторов Big Data систем может подписаться на топики Kafka для сбора метрик или выдачи сигналов тревоги, уведомляющих о случившихся или потенциальных авариях. Это весьма востребована, поскольку на практике, в основном, Elasticsearch с Kibana используются для информирования, а не для оповещения или мониторинга .
Например, в этом случае можно использовать 2 экземпляра Logstash – для отправки и индексации данных соответственно. Отправитель (Logstash Shipper) будет немедленно сохранять данные в топиках Кафка. А индексатор (Logstash Indexer) считывает из Кафка данные со своей собственной скоростью, выполняя при этом дорогостоящие преобразования, включая поиск и индексацию в Elasticsearch. Также FileBeat может отслеживать файлы и отправлять их в Kafka через приемник Logstash .
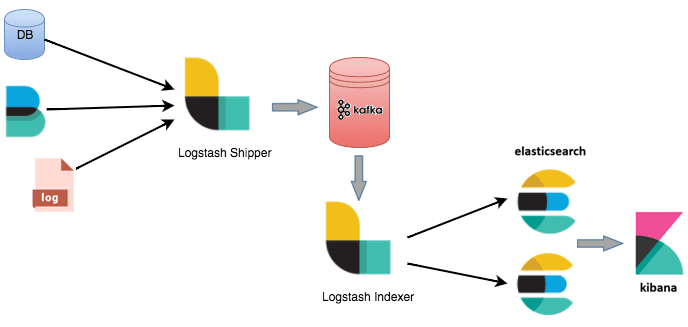 Интеграция Elasticseacrh с Apache Kafka
Интеграция Elasticseacrh с Apache Kafka
ELK Logging: How to Use the Elastic Stack for Log Management & Analytics
Depending on the use case and environment, businesses require different logging architectures.
For small environments, the classic ELK stack architecture is more than enough. It would look as follows:
On the other hand, when you work with massive amounts of data, you will, more than likely, need additional components. For example, you may want to use Apache Kafka for buffering:
A full-production grade architecture will more than likely, have multiple Elasticsearch nodes, maybe even multiple Logstash instances, an alerting plugin and an archiving mechanism.
That is why, before setting up your stack, you should be clear about your use case. This will influence where and how you install the stack, how you configure your Elasticsearch cluster, how you allocate resources and many more.
Now that you know how your ELK logging stack should look like, let’s start with the basics and see in detail what each of the ELK components – Elasticsearch, Logstash, Kibana and Beats – do:
Что внутри ELK-системы: архитектура и принципы работы
Инфраструктура ELK включает следующие компоненты :
- Elasticsearch (ES) – масштабируемая утилита полнотекстового поиска и аналитики, которая позволяет быстро в режиме реального времени хранить, искать и анализировать большие объемы данных. Как правило, ES используется в качестве NoSQL-базы данных для приложений со сложными функциями поиска. Elasticsearch основана на библиотеке Apache Lucene, предназначенной для индексирования и поиска информации в любом типе документов. В масштабных Big Data системах несколько копий Elasticsearch объединяются в кластер .
- Logstash — средство сбора, преобразования и сохранения в общем хранилище событий из файлов, баз данных, логов и других источников в реальном времени. Logsatsh позволяет модифицировать полученные данные с помощью фильтров: разбить строку на поля, обогатить или их, агрегировать несколько строк, преобразовать их в JSON-документы и пр. Обработанные данные Logsatsh отправляет в системы-потребители.
- Kibana – визуальный инструмент для Elasticsearch, чтобы взаимодействовать с данными, которые хранятся в индексах ES. Веб-интерфейс Kibana позволяет быстро создавать и обмениваться динамическими панелями мониторинга, включая таблицы, графики и диаграммы, которые отображают изменения в ES-запросах в реальном времени. Примечательно, что изначально Kibana была ориентирована на работу с Logstash, а не на Elasticsearch. Однако, с интеграцией 3-х систем в единую ELK-платформу, Kibana стала работать непосредственно с ES .
- FileBeat – агент на серверах для отправки различных типов оперативных данных в Elasticsearch.
В рамках единой ELK-платформы все вышеперечисленные компоненты взаимодействуют следующим образом :
- Logstash представляет собой конвейер обработки данных (data pipeline) на стороне сервера, который одновременно получает данные из нескольких источников, включая FileBeat. Здесь выполняется первичное преобразование, фильтрация, агрегация или парсинг логов, а затем обработанные данные отправляется в Elasticsearch.
- Elasticsearch играет роль ядра всей системы, сочетая функции базы данных, поискового и аналитического движков. Быстрый и гибкий поиск обеспечивается за счет анализаторов текста, нечеткого поиска, поддержки восточных языков (корейский, китайский, японский). Наличие REST API позволяет добавлять, просматривать, модифицировать и удалять данные .
- Kibana позволяет визуализировать данные ES, а также администрировать базу данных.
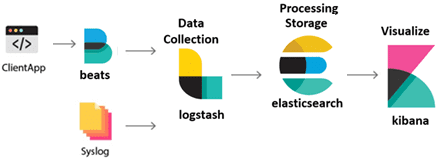 Принцип работы ELK-инфраструктуры: как взаимодействуют Elasticsearch, Logstash и Kibana
Принцип работы ELK-инфраструктуры: как взаимодействуют Elasticsearch, Logstash и Kibana
Завтра мы рассмотрим главные достоинства и недостатки ELK-инфраструктуры. А как эффективно использовать их для сбора и анализа больших данных в реальных проектах, вы узнаете на практических курсах по администрированию и эксплуатации Big Data систем в нашем лицензированном учебном центре повышения квалификации и обучения руководителей и ИТ-специалистов (разработчиков, архитекторов, инженеров и аналитиков) в Москве.
Смотреть расписание
Записаться на курс
Источники
- https://www.softlab.ru/blog/technologies/5816/
- https://ru.bmstu.wiki/Elastic_Logstash
- https://system-admins.ru/elk-o-chem-i-zachem/
- http://samag.ru/archive/article/3575
Stats
Documents and bytes counts
The Elasticsearch cat API provides a simple way to extract general statistics about log storage, e.g. total logs and bytes (not including replication)
logstash1010:~$ curl -s 'localhost:9200/_cat/indices?v&bytes=b' | awk '/logstash-/ {b+=$10; d+=$7} END {print d; print b}'
Or logs per day (change $3 to $7 to get bytes sans replication)
logstash1010:~$ curl -s 'localhost:9200/_cat/indices?v&bytes=b' | awk '/logstash-/ { gsub(/logstash-*/, "", $3); sum += $7 } END { for (i in sum) print i, sum }' | sort
Or logs per month:
logstash1010:~$ curl -s 'localhost:9200/_cat/indices?v&bytes=b' | awk '/logstash-/ { gsub(/logstash-*/, "", $3); gsub(/\.$/, "", $3); sum += $7 } END { for (i in sum) print i, sum }' | sort
Установка и настройка Elasticsearch
С помощью команды rpm загрузите ключ Elasticsearch:
Добавьте репозиторий:
Вставьте в него следующее содержимое и сохраните файл:
Запустите процесс установки:
Далее необходимо отредактировать файл конфигурации, для начала его нужно открыть с помощью текстового редактора vi:
В файле необходимо раскомментировать следующую строку:
Раскомментировать и установить значения следующим параметрам:
Сохраните изменения и закройте текстовый редактор.
Следующим шагом является редактирование файла конфигурации sysconfig для Elasticsearch:
Раскомментируйте параметр MAX_LOCKED_MEMORY и убедитесь, что установлено значение unlimited:
Перед тем, как запустить сервис, сначала перезагрузите системы и разрешите запуск Elasticsearch во время загрузки:
Вывод
В ходе данной работы была произведена установка ElasticSearch и ElasticLogstash для работы с базой данных ElasticSearch на ОС Ubuntu 18.04. Был продемонстрирован процесс создания простого конфигурационного файла logstash.conf и запуск в CLI в среде командной строки (терминала).
Добавление файлов происходит с помощью механизма сбора данных ElasticLogstash. А за хранение данных отвечает ElasticSearch.
Итак, мы разобрались с тем,что из себя представляет Logstash и из каких основных компонентов состоит.
Logstash очень полезен в ситуациях,когда необходимо пропарсить log-файлы с нескольких десятков серверов одновременно или найти ошибку в логах какого-нибудь сервиса.
Так как, обладает следующими преимуществами:
- Open source (даже X-pack).
- Простота установки и конфигурирование основных настроек.
- Input — ввод данных в любом формате, размере из любых источников.Так как, часто возникают ситуации,когда данные разбросаны в различных системных форматах.
- Filters — когда данные перемещаются из источника в хранилище, фильтры Logstash анализируют каждое событие, определяют именованные поля для построения структуры и преобразуют их в единый формат для упрощения и ускорения анализа.
- Output — в logstash есть целая библиотека выходных плагинов, с помощью которых определяется выход конечных данных(например,e-mail,exec,file или mongodb).
- Возможность модификации — в Logstash есть подключаемый фреймворк с более чем 200 плагинами.
- Безопасность — если узлы Logstash терпят неудачу, Logstash гарантирует доставку по крайней мере один раз для ваших событий.Для событий, которые не были успешно обработаны, создается отдельный список.