Обновление ядра linux до новой версии
Содержание:
- 1.15. 64-bit Boot Protocol¶
- Introduction¶
- uname command to display the Linux or Unix kernel version
- Mailing lists¶
- Working with the community¶
- Intro¶
- 1.1. Memory Layout¶
- Break up your changes¶
- Writing Documentation¶
- Mailing lists¶
- Break up your changes¶
- Introduction¶
- Package management tools (Linux only command)
- 1.2. The Real-Mode Kernel Header¶
- 1) Indentation¶
- 1.4. The kernel_info¶
- 1.12. Running the Kernel¶
- Introduction¶
- Break up your changes¶
- Conclusion
- ioctls: Not writing a new system call¶
- 1.7. The Kernel Command Line¶
- Documentation¶
- 8) Commenting¶
- Atomic Operations¶
- Introduction¶
- Working with the community¶
1.15. 64-bit Boot Protocol¶
For machine with 64bit cpus and 64bit kernel, we could use 64bit bootloader
and we need a 64-bit boot protocol.
In 64-bit boot protocol, the first step in loading a Linux kernel
should be to setup the boot parameters (struct boot_params,
traditionally known as “zero page”). The memory for struct boot_params
could be allocated anywhere (even above 4G) and initialized to all zero.
Then, the setup header at offset 0x01f1 of kernel image on should be
loaded into struct boot_params and examined. The end of setup header
can be calculated as follows:
0x0202 + byte value at offset 0x0201
In addition to read/modify/write the setup header of the struct
boot_params as that of 16-bit boot protocol, the boot loader should
also fill the additional fields of the struct boot_params as described
in zero-page.txt.
After setting up the struct boot_params, the boot loader can load
64-bit kernel in the same way as that of 16-bit boot protocol, but
kernel could be loaded above 4G.
In 64-bit boot protocol, the kernel is started by jumping to the
64-bit kernel entry point, which is the start address of loaded
64-bit kernel plus 0x200.
Introduction¶
So, you want to learn how to become a Linux kernel developer? Or you
have been told by your manager, “Go write a Linux driver for this
device.” This document’s goal is to teach you everything you need to
know to achieve this by describing the process you need to go through,
and hints on how to work with the community. It will also try to
explain some of the reasons why the community works like it does.
The kernel is written mostly in C, with some architecture-dependent
parts written in assembly. A good understanding of C is required for
kernel development. Assembly (any architecture) is not required unless
you plan to do low-level development for that architecture. Though they
are not a good substitute for a solid C education and/or years of
experience, the following books are good for, if anything, reference:
The kernel is written using GNU C and the GNU toolchain. While it
adheres to the ISO C89 standard, it uses a number of extensions that are
not featured in the standard. The kernel is a freestanding C
environment, with no reliance on the standard C library, so some
portions of the C standard are not supported. Arbitrary long long
divisions and floating point are not allowed. It can sometimes be
difficult to understand the assumptions the kernel has on the toolchain
and the extensions that it uses, and unfortunately there is no
definitive reference for them. Please check the gcc info pages (info
gcc) for some information on them.
uname command to display the Linux or Unix kernel version
This command works under all Linux distributions and other UNIX-like operating systems such as FreeBSD, OpenBSD, Solaris, HP UX, OS X and friends. Type the following command to see running kernel version: Output taken from Linux based system:
2.6.22-14-generic
Where,
- 2 : Kernel version
- 6 : The major revision of the kernel
- 22 : The minor revision of the kernel
- 14 : Immediate fixing / bug fixing for critical error
- generic : Distribution specific sting. For example, Redhat appends string such as EL5 to indicate RHEL 5 kernel.
Another common usage is as follows: Output taken from Linux:
Linux moon.nixcraft.in 2.6.18-53.1.4.el5 x86_64
Here is another output from RHEL 8:
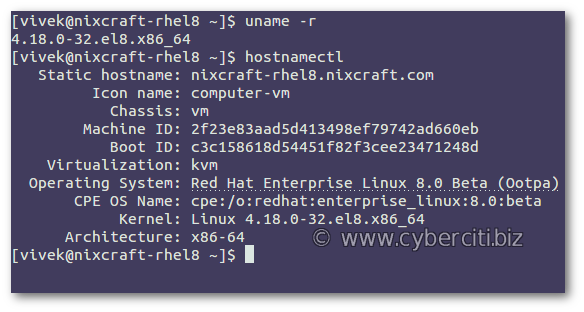
My RHEL 8 kernel version
Outputs from my OS X Unix desktop
$ uname -a Darwin desktop01 13.0.0 Darwin Kernel Version 13.0.0: Thu Sep 19 22:22:27 PDT 2013; root:xnu-2422.1.72~6/RELEASE_X86_64 x86_64
Outputs from OpenBSD Unix server
$ uname -mrs OpenBSD 5.4 amd64
For example, at the prompt, I type the following on AIX unix to print OS name: Sample outputs:
AIX
Mailing lists¶
As some of the above documents describe, the majority of the core kernel
developers participate on the Linux Kernel Mailing list. Details on how
to subscribe and unsubscribe from the list can be found at:
Most of the individual kernel subsystems also have their own separate
mailing list where they do their development efforts. See the
MAINTAINERS file for a list of what these lists are for the different
groups.
Many of the lists are hosted on kernel.org. Information on them can be
found at:
Please remember to follow good behavioral habits when using the lists.
Though a bit cheesy, the following URL has some simple guidelines for
interacting with the list (or any list):
If multiple people respond to your mail, the CC: list of recipients may
get pretty large. Don’t remove anybody from the CC: list without a good
reason, or don’t reply only to the list address. Get used to receiving the
mail twice, one from the sender and the one from the list, and don’t try
to tune that by adding fancy mail-headers, people will not like it.
Working with the community¶
The goal of the kernel community is to provide the best possible kernel
there is. When you submit a patch for acceptance, it will be reviewed
on its technical merits and those alone. So, what should you be
expecting?
Remember, this is part of getting your patch into the kernel. You have
to be able to take criticism and comments about your patches, evaluate
them at a technical level and either rework your patches or provide
clear and concise reasoning as to why those changes should not be made.
If there are no responses to your posting, wait a few days and try
again, sometimes things get lost in the huge volume.
What should you not do?
In a community that is looking for the best technical solution possible,
there will always be differing opinions on how beneficial a patch is.
You have to be cooperative, and willing to adapt your idea to fit within
the kernel. Or at least be willing to prove your idea is worth it.
Remember, being wrong is acceptable as long as you are willing to work
toward a solution that is right.
Intro¶
It’s only the odd person who wants to write a kernel driver that needs
to worry about the in-kernel interfaces changing. For the majority of
the world, they neither see this interface, nor do they care about it at
all.
First off, I’m not going to address any legal issues about closed
source, hidden source, binary blobs, source wrappers, or any other term
that describes kernel drivers that do not have their source code
released under the GPL. Please consult a lawyer if you have any legal
questions, I’m a programmer and hence, I’m just going to be describing
the technical issues here (not to make light of the legal issues, they
are real, and you do need to be aware of them at all times.)
1.1. Memory Layout¶
The traditional memory map for the kernel loader, used for Image or
zImage kernels, typically looks like:
| |
0A0000 +------------------------+
| Reserved for BIOS | Do not use. Reserved for BIOS EBDA.
09A000 +------------------------+
| Command line |
| Stack/heap | For use by the kernel real-mode code.
098000 +------------------------+
| Kernel setup | The kernel real-mode code.
090200 +------------------------+
| Kernel boot sector | The kernel legacy boot sector.
090000 +------------------------+
| Protected-mode kernel | The bulk of the kernel image.
010000 +------------------------+
| Boot loader | <- Boot sector entry point 0000:7C00
001000 +------------------------+
| Reserved for MBR/BIOS |
000800 +------------------------+
| Typically used by MBR |
000600 +------------------------+
| BIOS use only |
000000 +------------------------+
When using bzImage, the protected-mode kernel was relocated to
0x100000 (“high memory”), and the kernel real-mode block (boot sector,
setup, and stack/heap) was made relocatable to any address between
0x10000 and end of low memory. Unfortunately, in protocols 2.00 and
2.01 the 0x90000+ memory range is still used internally by the kernel;
the 2.02 protocol resolves that problem.
It is desirable to keep the “memory ceiling” – the highest point in
low memory touched by the boot loader – as low as possible, since
some newer BIOSes have begun to allocate some rather large amounts of
memory, called the Extended BIOS Data Area, near the top of low
memory. The boot loader should use the “INT 12h” BIOS call to verify
how much low memory is available.
Unfortunately, if INT 12h reports that the amount of memory is too
low, there is usually nothing the boot loader can do but to report an
error to the user. The boot loader should therefore be designed to
take up as little space in low memory as it reasonably can. For
zImage or old bzImage kernels, which need data written into the
0x90000 segment, the boot loader should make sure not to use memory
above the 0x9A000 point; too many BIOSes will break above that point.
For a modern bzImage kernel with boot protocol version >= 2.02, a
memory layout like the following is suggested:
Break up your changes¶
The reasons for breaking things up are the following:
-
Small patches increase the likelihood that your patches will be
applied, since they don’t take much time or effort to verify for
correctness. A 5 line patch can be applied by a maintainer with
barely a second glance. However, a 500 line patch may take hours to
review for correctness (the time it takes is exponentially
proportional to the size of the patch, or something).Small patches also make it very easy to debug when something goes
wrong. It’s much easier to back out patches one by one than it is
to dissect a very large patch after it’s been applied (and broken
something). -
It’s important not only to send small patches, but also to rewrite
and simplify (or simply re-order) patches before submitting them.
Here is an analogy from kernel developer Al Viro:
It may be challenging to keep the balance between presenting an elegant
solution and working together with the community and discussing your
unfinished work. Therefore it is good to get early in the process to
get feedback to improve your work, but also keep your changes in small
chunks that they may get already accepted, even when your whole task is
not ready for inclusion now.
Writing Documentation¶
Adding new documentation can be as simple as:
- Add a new file somewhere under .
- Refer to it from the Sphinx main TOC tree in .
This is usually good enough for simple documentation (like the one you’re
reading right now), but for larger documents it may be advisable to create a
subdirectory (or use an existing one). For example, the graphics subsystem
documentation is under , split to several files,
and has a separate (with a of its own) referenced from
the main index.
See the documentation for Sphinx and reStructuredText on what you can do
with them. In particular, the Sphinx reStructuredText Primer is a good place
to get started with reStructuredText. There are also some Sphinx specific
markup constructs.
Specific guidelines for the kernel documentation
Here are some specific guidelines for the kernel documentation:
-
Please don’t go overboard with reStructuredText markup. Keep it simple.
-
Please stick to this order of heading adornments:
-
with overline for document title:
============== Document title ==============
-
for chapters:
Chapters ========
-
for sections:
Section -------
-
for subsections:
Subsection ~~~~~~~~~~
Although RST doesn’t mandate a specific order (“Rather than imposing a fixed
number and order of section title adornment styles, the order enforced will be
the order as encountered.”), having the higher levels the same overall makes
it easier to follow the documents. -
the C domain
The Sphinx C Domain (name c) is suited for documentation of C API. E.g. a
function prototype:
.. c:function:: int ioctl( int fd, int request )
The C domain of the kernel-doc has some additional features. E.g. you can
rename the reference name of a function with a common name like or
:
.. c:function:: int ioctl( int fd, int request ) :name: VIDIOC_LOG_STATUS
The func-name (e.g. ioctl) remains in the output but the ref-name changed from
to . The index entry for this function is also
changed to and the function can now referenced by:
:c:func:`VIDIOC_LOG_STATUS`
Mailing lists¶
As some of the above documents describe, the majority of the core kernel
developers participate on the Linux Kernel Mailing list. Details on how
to subscribe and unsubscribe from the list can be found at:
Most of the individual kernel subsystems also have their own separate
mailing list where they do their development efforts. See the
MAINTAINERS file for a list of what these lists are for the different
groups.
Many of the lists are hosted on kernel.org. Information on them can be
found at:
Please remember to follow good behavioral habits when using the lists.
Though a bit cheesy, the following URL has some simple guidelines for
interacting with the list (or any list):
If multiple people respond to your mail, the CC: list of recipients may
get pretty large. Don’t remove anybody from the CC: list without a good
reason, or don’t reply only to the list address. Get used to receiving the
mail twice, one from the sender and the one from the list, and don’t try
to tune that by adding fancy mail-headers, people will not like it.
Break up your changes¶
The reasons for breaking things up are the following:
-
Small patches increase the likelihood that your patches will be
applied, since they don’t take much time or effort to verify for
correctness. A 5 line patch can be applied by a maintainer with
barely a second glance. However, a 500 line patch may take hours to
review for correctness (the time it takes is exponentially
proportional to the size of the patch, or something).Small patches also make it very easy to debug when something goes
wrong. It’s much easier to back out patches one by one than it is
to dissect a very large patch after it’s been applied (and broken
something). -
It’s important not only to send small patches, but also to rewrite
and simplify (or simply re-order) patches before submitting them.
Here is an analogy from kernel developer Al Viro:
It may be challenging to keep the balance between presenting an elegant
solution and working together with the community and discussing your
unfinished work. Therefore it is good to get early in the process to
get feedback to improve your work, but also keep your changes in small
chunks that they may get already accepted, even when your whole task is
not ready for inclusion now.
Introduction¶
So, you want to learn how to become a Linux kernel developer? Or you
have been told by your manager, “Go write a Linux driver for this
device.” This document’s goal is to teach you everything you need to
know to achieve this by describing the process you need to go through,
and hints on how to work with the community. It will also try to
explain some of the reasons why the community works like it does.
The kernel is written mostly in C, with some architecture-dependent
parts written in assembly. A good understanding of C is required for
kernel development. Assembly (any architecture) is not required unless
you plan to do low-level development for that architecture. Though they
are not a good substitute for a solid C education and/or years of
experience, the following books are good for, if anything, reference:
The kernel is written using GNU C and the GNU toolchain. While it
adheres to the ISO C89 standard, it uses a number of extensions that are
not featured in the standard. The kernel is a freestanding C
environment, with no reliance on the standard C library, so some
portions of the C standard are not supported. Arbitrary long long
divisions and floating point are not allowed. It can sometimes be
difficult to understand the assumptions the kernel has on the toolchain
and the extensions that it uses, and unfortunately there is no
definitive reference for them. Please check the gcc info pages (info
gcc) for some information on them.
Package management tools (Linux only command)
You can list all installed kernel and its version with the following command under RHEL / CentOS / Suse / Fedora Linux : Output:
kernel-2.6.18-53.el5 kernel-2.6.18-53.1.4.el5
If you are using Debian / Ubuntu, try: Output:
ii linux-image 2.6.22.14.21 Generic Linux kernel image. rc linux-image-2.6.20-15-generic 2.6.20-15.27 Linux kernel image for version 2.6.20 on x86/ ii linux-image-2.6.20-16-generic 2.6.20-16.32 Linux kernel image for version 2.6.20 on x86/ ii linux-image-2.6.22-14-generic 2.6.22-14.47 Linux kernel image for version 2.6.22 on x86/ ii linux-image-generic 2.6.22.14.21 Generic Linux kernel image
1.2. The Real-Mode Kernel Header¶
In the following text, and anywhere in the kernel boot sequence, “a
sector” refers to 512 bytes. It is independent of the actual sector
size of the underlying medium.
The first step in loading a Linux kernel should be to load the
real-mode code (boot sector and setup code) and then examine the
following header at offset 0x01f1. The real-mode code can total up to
32K, although the boot loader may choose to load only the first two
sectors (1K) and then examine the bootup sector size.
The header looks like:
| Offset/Size | Proto | Name | Meaning |
|---|---|---|---|
| 01F1/1 | ALL(1) | setup_sects | The size of the setup in sectors |
| 01F2/2 | ALL | root_flags | If set, the root is mounted readonly |
| 01F4/4 | 2.04+(2) | syssize | The size of the 32-bit code in 16-byte paras |
| 01F8/2 | ALL | ram_size | DO NOT USE — for bootsect.S use only |
| 01FA/2 | ALL | vid_mode | Video mode control |
| 01FC/2 | ALL | root_dev | Default root device number |
| 01FE/2 | ALL | boot_flag | 0xAA55 magic number |
| 0200/2 | 2.00+ | jump | Jump instruction |
| 0202/4 | 2.00+ | header | Magic signature “HdrS” |
| 0206/2 | 2.00+ | version | Boot protocol version supported |
| 0208/4 | 2.00+ | realmode_swtch | Boot loader hook (see below) |
| 020C/2 | 2.00+ | start_sys_seg | The load-low segment (0x1000) (obsolete) |
| 020E/2 | 2.00+ | kernel_version | Pointer to kernel version string |
| 0210/1 | 2.00+ | type_of_loader | Boot loader identifier |
| 0211/1 | 2.00+ | loadflags | Boot protocol option flags |
| 0212/2 | 2.00+ | setup_move_size | Move to high memory size (used with hooks) |
| 0214/4 | 2.00+ | code32_start | Boot loader hook (see below) |
| 0218/4 | 2.00+ | ramdisk_image | initrd load address (set by boot loader) |
| 021C/4 | 2.00+ | ramdisk_size | initrd size (set by boot loader) |
| 0220/4 | 2.00+ | bootsect_kludge | DO NOT USE — for bootsect.S use only |
| 0224/2 | 2.01+ | heap_end_ptr | Free memory after setup end |
| 0226/1 | 2.02+(3) | ext_loader_ver | Extended boot loader version |
| 0227/1 | 2.02+(3) | ext_loader_type | Extended boot loader ID |
| 0228/4 | 2.02+ | cmd_line_ptr | 32-bit pointer to the kernel command line |
| 022C/4 | 2.03+ | initrd_addr_max | Highest legal initrd address |
| 0230/4 | 2.05+ | kernel_alignment | Physical addr alignment required for kernel |
| 0234/1 | 2.05+ | relocatable_kernel | Whether kernel is relocatable or not |
| 0235/1 | 2.10+ | min_alignment | Minimum alignment, as a power of two |
| 0236/2 | 2.12+ | xloadflags | Boot protocol option flags |
| 0238/4 | 2.06+ | cmdline_size | Maximum size of the kernel command line |
| 023C/4 | 2.07+ | hardware_subarch | Hardware subarchitecture |
| 0240/8 | 2.07+ | hardware_subarch_data | Subarchitecture-specific data |
| 0248/4 | 2.08+ | payload_offset | Offset of kernel payload |
| 024C/4 | 2.08+ | payload_length | Length of kernel payload |
| 0250/8 | 2.09+ | setup_data | 64-bit physical pointer to linked list of struct setup_data |
| 0258/8 | 2.10+ | pref_address | Preferred loading address |
| 0260/4 | 2.10+ | init_size | Linear memory required during initialization |
| 0264/4 | 2.11+ | handover_offset | Offset of handover entry point |
| 0268/4 | 2.15+ | kernel_info_offset | Offset of the kernel_info |
Note
- For backwards compatibility, if the setup_sects field contains 0, the
real value is 4. - For boot protocol prior to 2.04, the upper two bytes of the syssize
field are unusable, which means the size of a bzImage kernel
cannot be determined. - Ignored, but safe to set, for boot protocols 2.02-2.09.
If the “HdrS” (0x53726448) magic number is not found at offset 0x202,
the boot protocol version is “old”. Loading an old kernel, the
following parameters should be assumed:
Image type = zImage initrd not supported Real-mode kernel must be located at 0x90000.
1) Indentation¶
Tabs are 8 characters, and thus indentations are also 8 characters.
There are heretic movements that try to make indentations 4 (or even 2!)
characters deep, and that is akin to trying to define the value of PI to
be 3.
Rationale: The whole idea behind indentation is to clearly define where
a block of control starts and ends. Especially when you’ve been looking
at your screen for 20 straight hours, you’ll find it a lot easier to see
how the indentation works if you have large indentations.
Now, some people will claim that having 8-character indentations makes
the code move too far to the right, and makes it hard to read on a
80-character terminal screen. The answer to that is that if you need
more than 3 levels of indentation, you’re screwed anyway, and should fix
your program.
In short, 8-char indents make things easier to read, and have the added
benefit of warning you when you’re nesting your functions too deep.
Heed that warning.
The preferred way to ease multiple indentation levels in a switch statement is
to align the and its subordinate labels in the same column
instead of the labels. E.g.:
switch (suffix) {
case 'G'
case 'g'
mem <<= 30;
break;
case 'M'
case 'm'
mem <<= 20;
break;
case 'K'
case 'k'
mem <<= 10;
/* fall through */
default
break;
}
Don’t put multiple statements on a single line unless you have
something to hide:
if (condition) do_this; do_something_everytime;
Don’t put multiple assignments on a single line either. Kernel coding style
is super simple. Avoid tricky expressions.
Outside of comments, documentation and except in Kconfig, spaces are never
used for indentation, and the above example is deliberately broken.
1.4. The kernel_info¶
The relationships between the headers are analogous to the various data
sections:
What is missing from the above list? That’s right:
We have been (ab)using .data for things that could go into .rodata or .bss for
a long time, for lack of alternatives and – especially early on – inertia.
Also, the BIOS stub is responsible for creating boot_params, so it isn’t
available to a BIOS-based loader (setup_data is, though).
setup_header is permanently limited to 144 bytes due to the reach of the
2-byte jump field, which doubles as a length field for the structure, combined
with the size of the “hole” in struct boot_params that a protected-mode loader
or the BIOS stub has to copy it into. It is currently 119 bytes long, which
leaves us with 25 very precious bytes. This isn’t something that can be fixed
without revising the boot protocol entirely, breaking backwards compatibility.
boot_params proper is limited to 4096 bytes, but can be arbitrarily extended
by adding setup_data entries. It cannot be used to communicate properties of
the kernel image, because it is .bss and has no image-provided content.
kernel_info solves this by providing an extensible place for information about
the kernel image. It is readonly, because the kernel cannot rely on a
bootloader copying its contents anywhere, but that is OK; if it becomes
necessary it can still contain data items that an enabled bootloader would be
expected to copy into a setup_data chunk.
All kernel_info data should be part of this structure. Fixed size data have to
be put before kernel_info_var_len_data label. Variable size data have to be put
after kernel_info_var_len_data label. Each chunk of variable size data has to
be prefixed with header/magic and its size, e.g.:
kernel_info:
.ascii "LToP" /* Header, Linux top (structure). */
.long kernel_info_var_len_data - kernel_info
.long kernel_info_end - kernel_info
.long 0x01234567 /* Some fixed size data for the bootloaders. */
kernel_info_var_len_data:
example_struct: /* Some variable size data for the bootloaders. */
.ascii "0123" /* Header/Magic. */
.long example_struct_end - example_struct
.ascii "Struct"
.long 0x89012345
example_struct_end:
example_strings: /* Some variable size data for the bootloaders. */
.ascii "ABCD" /* Header/Magic. */
.long example_strings_end - example_strings
.asciz "String_0"
.asciz "String_1"
example_strings_end:
kernel_info_end:
This way the kernel_info is self-contained blob.
1.12. Running the Kernel¶
The kernel is started by jumping to the kernel entry point, which is
located at segment offset 0x20 from the start of the real mode
kernel. This means that if you loaded your real-mode kernel code at
0x90000, the kernel entry point is 9020:0000.
At entry, ds = es = ss should point to the start of the real-mode
kernel code (0x9000 if the code is loaded at 0x90000), sp should be
set up properly, normally pointing to the top of the heap, and
interrupts should be disabled. Furthermore, to guard against bugs in
the kernel, it is recommended that the boot loader sets fs = gs = ds =
es = ss.
In our example from above, we would do:
/* Note: in the case of the "old" kernel protocol, base_ptr must be == 0x90000 at this point; see the previous sample code */ seg = base_ptr >> 4; cli(); /* Enter with interrupts disabled! */ /* Set up the real-mode kernel stack */ _SS = seg; _SP = heap_end; _DS = _ES = _FS = _GS = seg; jmp_far(seg+0x20, 0); /* Run the kernel */
Introduction¶
The Linux kernel uses Sphinx to generate pretty documentation from
reStructuredText files under . To build the documentation in
HTML or PDF formats, use or . The generated
documentation is placed in .
The reStructuredText files may contain directives to include structured
documentation comments, or kernel-doc comments, from source files. Usually these
are used to describe the functions and types and design of the code. The
kernel-doc comments have some special structure and formatting, but beyond that
they are also treated as reStructuredText.
There is also the deprecated DocBook toolchain to generate documentation from
DocBook XML template files under . The DocBook files
are to be converted to reStructuredText, and the toolchain is slated to be
removed.
Break up your changes¶
The reasons for breaking things up are the following:
-
Small patches increase the likelihood that your patches will be
applied, since they don’t take much time or effort to verify for
correctness. A 5 line patch can be applied by a maintainer with
barely a second glance. However, a 500 line patch may take hours to
review for correctness (the time it takes is exponentially
proportional to the size of the patch, or something).Small patches also make it very easy to debug when something goes
wrong. It’s much easier to back out patches one by one than it is
to dissect a very large patch after it’s been applied (and broken
something). -
It’s important not only to send small patches, but also to rewrite
and simplify (or simply re-order) patches before submitting them.
Here is an analogy from kernel developer Al Viro:
It may be challenging to keep the balance between presenting an elegant
solution and working together with the community and discussing your
unfinished work. Therefore it is good to get early in the process to
get feedback to improve your work, but also keep your changes in small
chunks that they may get already accepted, even when your whole task is
not ready for inclusion now.
Conclusion
We have shown you how to find the version of the Unix and Linux kernel running on your server/desktop/laptop/workstion from the command line. See uname man page here and here for more info.
This entry is 3 of 8 in the Linux/Unix Kernel Version Tutorial series. Keep reading the rest of the series:
- How To Find Out FreeBSD Version and Patch Level Number
- How To Find Which Linux Kernel Version Is Installed On My System
- Find Linux / UNIX Kernel Version Command
- How To Find Out If 32 or 64 bit Unix OS Installed On Server
- Linux: Find If Processor (CPU) is 64 bit / 32 bit
- List or Check Installed Linux Kernels
- Find Linux Kernel Version Command
- Linux Command: Show Linux Version
ioctls: Not writing a new system call¶
A system call generally looks like this:
asmlinkage long sys_mycall(int arg)
{
return 0;
}
First, in most cases you don’t want to create a new system call. You
create a character device and implement an appropriate ioctl for it.
This is much more flexible than system calls, doesn’t have to be entered
in every architecture’s and
file, and is much more likely to be accepted by
Linus.
If all your routine does is read or write some parameter, consider
implementing a interface instead.
Inside the ioctl you’re in user context to a process. When a error
occurs you return a negated errno (see
,
and ),
otherwise you return 0.
After you slept you should check if a signal occurred: the Unix/Linux
way of handling signals is to temporarily exit the system call with the
error. The system call entry code will switch back to
user context, process the signal handler and then your system call will
be restarted (unless the user disabled that). So you should be prepared
to process the restart, e.g. if you’re in the middle of manipulating
some data structure.
if (signal_pending(current))
return -ERESTARTSYS;
If you’re doing longer computations: first think userspace. If you
really want to do it in kernel you should regularly check if you need
to give up the CPU (remember there is cooperative multitasking per CPU).
Idiom:
cond_resched(); /* Will sleep */
1.7. The Kernel Command Line¶
The kernel command line has become an important way for the boot
loader to communicate with the kernel. Some of its options are also
relevant to the boot loader itself, see “special command line options”
below.
The kernel command line is a null-terminated string. The maximum
length can be retrieved from the field cmdline_size. Before protocol
version 2.06, the maximum was 255 characters. A string that is too
long will be automatically truncated by the kernel.
If the boot protocol version is 2.02 or later, the address of the
kernel command line is given by the header field cmd_line_ptr (see
above.) This address can be anywhere between the end of the setup
heap and 0xA0000.
If the protocol version is not 2.02 or higher, the kernel
command line is entered using the following protocol:
Documentation¶
The Linux kernel source tree has a large range of documents that are
invaluable for learning how to interact with the kernel community. When
new features are added to the kernel, it is recommended that new
documentation files are also added which explain how to use the feature.
When a kernel change causes the interface that the kernel exposes to
userspace to change, it is recommended that you send the information or
a patch to the manual pages explaining the change to the manual pages
maintainer at mtk.manpages@gmail.com, and CC the list
linux-api@vger.kernel.org.
Here is a list of files that are in the kernel source tree that are
required reading:
The kernel also has a large number of documents that can be
automatically generated from the source code itself or from
ReStructuredText markups (ReST), like this one. This includes a
full description of the in-kernel API, and rules on how to handle
locking properly.
All such documents can be generated as PDF or HTML by running:
make pdfdocs make htmldocs
respectively from the main kernel source directory.
The documents that uses ReST markup will be generated at Documentation/output.
They can also be generated on LaTeX and ePub formats with:
8) Commenting¶
Comments are good, but there is also a danger of over-commenting. NEVER
try to explain HOW your code works in a comment: it’s much better to
write the code so that the working is obvious, and it’s a waste of
time to explain badly written code.
Generally, you want your comments to tell WHAT your code does, not HOW.
Also, try to avoid putting comments inside a function body: if the
function is so complex that you need to separately comment parts of it,
you should probably go back to chapter 6 for a while. You can make
small comments to note or warn about something particularly clever (or
ugly), but try to avoid excess. Instead, put the comments at the head
of the function, telling people what it does, and possibly WHY it does
it.
When commenting the kernel API functions, please use the kernel-doc format.
See the files at and
for details.
The preferred style for long (multi-line) comments is:
/* * This is the preferred style for multi-line * comments in the Linux kernel source code. * Please use it consistently. * * Description: A column of asterisks on the left side, * with beginning and ending almost-blank lines. */
For files in net/ and drivers/net/ the preferred style for long (multi-line)
comments is a little different.
/* The preferred comment style for files in net/ and drivers/net * looks like this. * * It is nearly the same as the generally preferred comment style, * but there is no initial almost-blank line. */
Atomic Operations¶
Certain operations are guaranteed atomic on all platforms. The first
class of operations work on ();
this contains a signed integer (at least 32 bits long), and you must use
these functions to manipulate or read variables.
and get and set
the counter, , ,
, , and
(returns true if it was
decremented to zero).
Yes. It returns true (i.e. != 0) if the atomic variable is zero.
Note that these functions are slower than normal arithmetic, and so
should not be used unnecessarily.
The second class of atomic operations is atomic bit operations on an
, defined in . These
operations generally take a pointer to the bit pattern, and a bit
number: 0 is the least significant bit. ,
and set, clear,
and flip the given bit. ,
and
do the same thing, except return
true if the bit was previously set; these are particularly useful for
atomically setting flags.
Introduction¶
So, you want to learn how to become a Linux kernel developer? Or you
have been told by your manager, “Go write a Linux driver for this
device.” This document’s goal is to teach you everything you need to
know to achieve this by describing the process you need to go through,
and hints on how to work with the community. It will also try to
explain some of the reasons why the community works like it does.
The kernel is written mostly in C, with some architecture-dependent
parts written in assembly. A good understanding of C is required for
kernel development. Assembly (any architecture) is not required unless
you plan to do low-level development for that architecture. Though they
are not a good substitute for a solid C education and/or years of
experience, the following books are good for, if anything, reference:
The kernel is written using GNU C and the GNU toolchain. While it
adheres to the ISO C89 standard, it uses a number of extensions that are
not featured in the standard. The kernel is a freestanding C
environment, with no reliance on the standard C library, so some
portions of the C standard are not supported. Arbitrary long long
divisions and floating point are not allowed. It can sometimes be
difficult to understand the assumptions the kernel has on the toolchain
and the extensions that it uses, and unfortunately there is no
definitive reference for them. Please check the gcc info pages (info
gcc) for some information on them.
Working with the community¶
The goal of the kernel community is to provide the best possible kernel
there is. When you submit a patch for acceptance, it will be reviewed
on its technical merits and those alone. So, what should you be
expecting?
Remember, this is part of getting your patch into the kernel. You have
to be able to take criticism and comments about your patches, evaluate
them at a technical level and either rework your patches or provide
clear and concise reasoning as to why those changes should not be made.
If there are no responses to your posting, wait a few days and try
again, sometimes things get lost in the huge volume.
What should you not do?
In a community that is looking for the best technical solution possible,
there will always be differing opinions on how beneficial a patch is.
You have to be cooperative, and willing to adapt your idea to fit within
the kernel. Or at least be willing to prove your idea is worth it.
Remember, being wrong is acceptable as long as you are willing to work
toward a solution that is right.






