Calculating innodb buffer pool size for your mysql server
Содержание:
4 ответа
25
ВАШ ВОПРОС
На первый взгляд этот запрос должен касаться только 1.1597% (62510 из 5390146) таблицы. Он должен быть быстрым, учитывая ключевое распределение threadid 51506.
ПРОВЕРКА РЕАЛЬНОСТИ
Независимо от того, какую версию MySQL (Oracle, Percona, MariaDB) вы используете, ни один из них не может сражаться с одним врагом, с которым они имеют общее: архитектура InnoDB.

КЛАСТЕРИРОВАННЫЙ ИНДЕКС
Пожалуйста, имейте в виду, что каждая запись потока содержит первичный ключ. Это означает, что при чтении из индекса он должен выполнять поиск первичного ключа внутри ClusteredIndex (внутренне названный gen_clust_index) . В ClusteredIndex каждая страница InnoDB содержит как данные, так и данные индекса PRIMARY KEY. Для получения дополнительной информации см. Мой пост .
ПОСЛЕДНИЕ УСЛОВИЯ
У вас много помех в таблице, потому что некоторые индексы имеют одни и те же ведущие столбцы. MySQL и InnoDB должны перемещаться по беспорядку индекса, чтобы добраться до необходимых узлов BTREE. Вы должны уменьшить этот беспорядок, выполнив следующее:
Зачем снимать эти индексы?
- Первые три индекса начинаются с threadid
- и начинаются с тех же трех столбцов
- не нужен postid, так как это PRIMARY KEY и встроенный
БУФЕР КАШИНГ
Только в этой области MyISAM не тратит время на кеширование данных. Это потому, что он не предназначен для кэширования данных. InnoDB кэширует каждую страницу данных и индексную страницу (и ее бабушку), к которой она прикасается. Если ваш буферный пул InnoDB слишком мал, вы можете кэшировать страницы, недействительные страницы и удалять страницы в одном запросе.
ТАБЛИЧ. LAYOUT
Вы могли бы сбрить некоторое пространство из строки, рассмотрев и . У вас их как BIGINT. Они берут 16 байтов в ClusteredIndex за строку.
Вы должны запустить этот
Это будет рекомендовать, какие типы данных должны быть для этих столбцов для данного набора данных.
Заключение
MyISAM имеет гораздо меньше препятствий, чем InnoDB, особенно в области кэширования.
Пока вы указали объем ОЗУ () и версию MySQL (), есть еще другие части этой головоломки, которые вы не обнаружили.
- Настройки InnoDB
- Число ядер
- Другие настройки из
Если вы можете добавить эти вещи к вопросу, я могу подробнее разобраться.
ОБНОВЛЕНИЕ 2014-08-28 11:27 EDT
Вы должны увеличить поток
Я бы рассмотрел возможность отключения кеша запросов (см. недавнее сообщение )
Я бы сохранил буферный пул
Увеличить (если вы сделать DML на нескольких таблицах)
ДАЙТЕ ЭТО ПОВРЕЖДЕНИЕ !!!
7
@RolandMySQLDBA дал правильный намек, чтобы ответить на вопрос. Проблема заключается в том, что проблема заключается в запросе и что для того, чтобы результаты были возвращены, каждое из этих полей должно быть прочитано (как-то из базы данных).
Я сбросил все индексы, но , и вставил этот новый индекс:
Эта ссылка объясняет, что происходит здесь ( покрытие index ): запрашиваемые поля запроса, которые теперь могут быть извлечены из самого ключа. Это экономит проверку реальных данных и использование ввода-вывода на жесткий диск.
Все запросы теперь выполняются с 0.00 секунд ..:)
Большое спасибо за вашу помощь.
Изменить . Фактическая основная проблема не решена, я просто обошел ее с помощью этой техники. InnoDB нуждается в серьезной фиксации в этой области.
На основе вашего запроса и таблицы кажется, что вы выбрали данные из таблицы временных рядов. Таким образом, может случиться так, что время запроса медленное, потому что вы вставляете одновременно?
Если эти две вещи верны, чем я могу предложить посмотреть в ScaleDB в качестве альтернативы? Вы все равно будете на MariaDB, просто (может быть) более подходящим движком.
Оба механизма быстрее выполнят запрос much с
Это потому, что он будет «охватывающим» индексом и будет работать практически одинаково (с использованием индекса BTree).
Кроме того, я скажу, что это невозможно для двигателя на «холодном» сервере:
Пожалуйста, используйте при выполнении таймингов — мы не хотим, чтобы кэш запросов загрязнял выводы.
Еще один быстрый подход (без кэширования ввода-вывода):
Используйте InnoDB и измените с на
Причина в том, что это приведет к смещению всех соответствующих строк, что потребует меньше ввода-вывода и т. д. должен содержать счастливый. Предостережение: это бесполезно со всеми вторичными ключами — некоторые будут быстрее, некоторые будут медленнее.
TokuDB
TokuDB è un nuovo Storage Engine per MySQL/MariaDB sviluppato da Percona, creato per diventare il sostituto di InnoDB con un occhio al mondo del big data. Esso ha alcune funzionalità comuni a InnoDB, come la possibilità di modificare le tabelle dopo la creazione con nuovi indici, nonchè quella di aggiungere ed eliminare campi, il supporto pieno alle transazioni e quello a MVCC. Manca invece il supporto alle foreign keys esplicite.
La caratteristica che lo differenzia dagli altri Storage Engine è l’utilizzo di un indice ad albero frattale che permette:
- prestazioni aumentate in scrittura e lettura (fino a 20 volte superiori a InnoDB senza operazioni di tuning particolari);
- teoricamente l’eliminazione dei lag nella replicazione verso server slave;
- marcato risparmio di spazio su disco (fino ad un livello di compressione 25 volte maggiore rispetto a InnoDB).
Negli ultimi anni TokuDB sta riscuotendo molto successo, ed alcuni sistemi hanno iniziato ad includerlo di default nelle proprie distribuzioni. Ad esempio, MariaDB viene rilasciato con questo Storage Engine disabilitato ma pronto per essere abilitato dal file di configurazione.
Memory
Questo storage engine ha la caratteristica di non salvare i dati in maniera persistente su disco, ma di mantenerli in memoria. La conseguenza sarà di avere a disposizione tabelle molto veloci, ottime come supporto allo svolgimento di operazioni piuttosto lunghe. Al contrario, non è utilizzabile per il salvataggio duraturo dei dati. Il loro utilizzo si è ridotto nel tempo grazie ad un’altra caratteristica molto importante di InnoDB, che consiste nell’utilizzare come cache un buffer pool in memoria per agevolare operazioni di lettura che coinvolgono grandi quantità di dati. L’avvertenza doverosa nei confronti di Memory, che rimane comunque una tecnologia molto utile, è di non far assumere a questo tipo di tabelle dimensioni eccessive, che potrebbero penalizzare le prestazioni dell’intero DBMS.
Журналирование
Предположим, вы хотите использовать MySQL для ведения в режиме реального времени журнала всех телефонных звонков, поступивших с центрального телефонного коммутатора. Или, возможно, вы установили утилиту для Apache и теперь можете хранить сведения обо всех посещениях сайта прямо в таблице. В таких приложениях, вероятно, самым важным является обеспечение быстродействия.
Вы же не хотите, чтобы база данных оказалась узким местом. Подсистемы хранения данных MyISAM и будут очень хорошо работать, поскольку характеризуются небольшими издержками, и вы сможете осуществлять тысячи операций записи в секунду.
Однако все становится гораздо интереснее, когда приходит время генерировать отчеты на основе записанных в журнал данных. В зависимости от того, какие запросы вы используете, велика вероятность, что сбор данных для отчета значительно замедлит процесс добавления новых записей. Что можно сделать в этой ситуации?
Например, можно использовать встроенную функцию репликации MySQL для дублирования данных на второй сервер, где затем будут запущены запросы, активно потребляющие ресурсы центрального процессора (ЦП). Таким образом, главный сервер останется свободным для вставки записей и вы сможете делать любые запросы, не беспокоясь о том, как создание отчета повлияет на ведение журнала в реальном времени.
Также вы можете запускать запросы в периоды низкой загрузки, правда, по мере развития приложения эта стратегия может стать неработоспособной.
Другой вариант — вести журнал в таблице, имя которой составлено из года и названия или номера месяца, например или . Если вы будете адресовать запросы к таблицам, в которые уже не производится запись, то приложение сможет непрерывно сохранять новые данные журнала в текущую таблицу.
Зачем может понадобиться смена формата таблиц?
У каждой из таблиц есть свои преимущества и недостатки. В целом считается, что InnoDB более надежная база для больших структур, чем MyISAM.
Однако на деле, в привычной жизни рядового вебмастера таблицы с InnoDB приносят больше проблем, чем MyISAM. Потому что последние чинить гораздо проще.
Ниже ошибка в базе данных InnoDB, которая не чинится встроенными инструментами SQL, phpMyAdmin или WordPress.
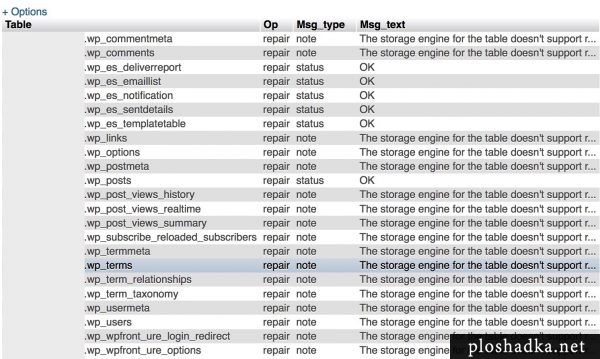
Вы будете получать уведомления:
the storage engine for the table doesn’t support repair wordpress
Также в логах можно увидеть ошибки от InnoDB такого рода:
171027 15:11:53 InnoDB: The InnoDB memory heap is disabled 171027 15:11:53 InnoDB: Mutexes and rw_locks use GCC atomic builtins 171027 15:11:53 InnoDB: Compressed tables use zlib 1.2.7 171027 15:11:53 InnoDB: Using Linux native AIO 171027 15:11:53 InnoDB: Initializing buffer pool, size = 128.0M 171027 15:11:53 InnoDB: Completed initialization of buffer pool 171027 15:11:53 InnoDB: highest supported file format is Barracuda. InnoDB: The log sequence number in ibdata files does not match InnoDB: the log sequence number in the ib_logfiles! 171027 15:11:53 InnoDB: Database was not shut down normally! InnoDB: Starting crash recovery. InnoDB: Reading tablespace information from the .ibd files… InnoDB: Restoring possible half-written data pages from the doublewrite InnoDB: buffer… 171027 15:11:54 InnoDB: Waiting for the background threads to start 171027 15:11:55 Percona XtraDB (http://www.percona.com) 5.5.49-MariaDB-38.0 started; log sequence number 402087117
Для починки таких ошибок нужно заходить через SHH, создавать DUMP InnoDB и затем его восстанавливать. А это несколько замороченее, чем починка таблиц MyISAM.
Решение 3
Here are 3 MySQL performance tuning settings that you should always look at. If you do not, you are very likely to run into problems very quickly.
innodb_buffer_pool_size: this is the #1 setting to look at for any installation using InnoDB. The buffer pool is where data and indexes are cached: having it as large as possible will ensure you use memory and not disks for most read operations. Typical values are 5-6GB (8GB RAM), 20-25GB (32GB RAM), 100-120GB (128GB RAM).
innodb_log_file_size: this is the size of the redo logs. The redo logs are used to make sure writes are fast and durable and also during crash recovery. Up to MySQL 5.1, it was hard to adjust, as you wanted both large redo logs for good performance and small redo logs for fast crash recovery. Fortunately crash recovery performance has improved a lot since MySQL 5.5 so you can now have good write performance and fast crash recovery. Until MySQL 5.5 the total redo log size was limited to 4GB (the default is to have 2 log files). This has been lifted in MySQL 5.6.
Starting with innodb_log_file_size = 512M (giving 1GB of redo logs) should give you plenty of room for writes. If you know your application is write-intensive and you are using MySQL 5.6, you can start with innodb_log_file_size = 4G.
max_connections: if you are often facing the ‘Too many connections’ error, max_connections is too low. It is very frequent that because the application does not close connections to the database correctly, you need much more than the default 151 connections. The main drawback of high values for max_connections (like 1000 or more) is that the server will become unresponsive if for any reason it has to run 1000 or more active transactions. Using a connection pool at the application level or a thread pool at the MySQL level can help here.






