Mysql group by
Содержание:
- MySQL GROUP BY examples
- Чистая группировка с помощью group by
- Операторы GROUP BY и HAVING
- Introduction to SQL GROUP BY clause
- Группировка
- Example — Using GROUP BY with the MAX function
- Пример — использование GROUP BY с функцией MAX
- Примеры использования оператора GROUP BY
- SQL GROUP BY examples
- SQL Справочник
- Пример — две таблицы в операторе FROM (OUTER JOIN)
- Introduction to MySQL GROUP BY clause
MySQL GROUP BY examples
Let’s take some example of using the clause.
A) Simple MySQL example
Let’s take a look at the table in the sample database.
Suppose you want to group values of the order’s status into subgroups, you use the clause with the column as the following query:
As you can see, the clause returns unique occurrences of values. It works like the operator as shown in the following query:
B) Using MySQL with aggregate functions
The aggregate functions allow you to perform the calculation of a set of rows and return a single value. The clause is often used with an aggregate function to perform calculation and return a single value for each subgroup.
For example, if you want to know the number of orders in each status, you can use the function with the clause as follows:
See the following and table.
To get the total amount of all orders by status, you join the table with the table and use the function to calculate the total amount. See the following query:
Similarly, the following query returns the order numbers and the total amount of each order.
C) MySQL with expression example
In addition to columns, you can group rows by expressions. The following query gets the total sales for each year.
In this example, we used the function to extract year data from order date ( ). We included only orders with status in the total sales. Note that the expression which appears in the clause must be the same as the one in the clause.
D) Using MySQL with clause example
To filter the groups returned by clause, you use a clause. The following query uses the clause to select the total sales of the years after 2003.
Чистая группировка с помощью group by
Представим, что нам необходимо узнать ценность каждой группы, а именно среднее значение рейтинга пользователей в группе и общее число сообщений, оставленных в форуме.
Вначале, небольшое словесное описание, чтобы легче было понимать SQL-запрос. Итак, вам нужно найти вычисляемые значения по группам форума. Соответственно, вам нужно поделить все эти десять строк на три разные группы: admin, moder, user. Чтобы это сделать, нужно в конце запроса добавить группировку по значениям поля forum_group. А так же добавить в select вычисляемые выражения с использованием так называемых агрегатных функций.
Вот как будет выглядеть SQL-запрос
-- Указываем поля и вычисляемые столбцы select forum_group, avg(raiting) as avg_raiting, sum(mess_count) as total_mess_count -- Указываем таблицу from userstat -- Указываем группировку по полю group by forum_group
Обратите внимание, что после того, как вы использовали конструкцию group by в запросе, можно без применения агрегатных функций использовать только те поля в select, которые были указаны после group by. Остальные поля должны быть указаны внутри агрегатных функций
Так же я воспользовался двумя агрегатными функциями. AVG — вычисляет среднее значение. И SUM — вычисляет сумму.
Вот какой получился результат:
| forum_group | avg_raiting | total_mess_count |
|---|---|---|
| admin | 4 | 50 |
| moder | 3 | 50 |
| user | 3 | 150 |
Давайте разберем по шагам, как получился данный результат.
1. Вначале все строки исходной таблицы были разбиты на три группы по значениям поля forum_group. Например, внутри группы admin было три пользователя. Внутри moder так же 3 строки. А внутри группы user было 4 строки (четыре пользователя).
2. Затем для каждой группы применялись агрегатные функции. Например, для группы admin средний рейтинг вычислялся так (2 + 5 + 5)/3 = 4. Количество сообщений вычислялось так (10 + 15 + 25) = 50.
Как видите, ничего сложного. Однако, мы применили всего одно условие группировки и не применяли фильтрацию по группам. Поэтому перейдем к следующему примеру.
Операторы GROUP BY и HAVING
Последнее обновление: 19.07.2017
Для группировки данных в T-SQL применяются операторы GROUP BY и HAVING, для использования которых применяется следующий формальный синтаксис:
SELECT столбцы FROM таблица
GROUP BY
Оператор GROUP BY определяет, как строки будут группироваться.
Например, сгруппируем товары по производителю
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer
Первый столбец в выражении SELECT — Manufacturer представляет название группы, а второй столбец — ModelsCount представляет результат функции Count,
которая вычисляет количество строк в группе.
Стоит учитывать, что любой столбец, который используется в выражении SELECT (не считая столбцов, которые хранят результат агрегатных функций),
должны быть указаны после оператора GROUP BY. Так, например, в случае выше столбец Manufacturer указан и в выражении SELECT, и в выражении
GROUP BY.
И если в выражении SELECT производится выборка по одному или нескольким столбцам и также используются агрегатные функции, то необходимо использовать
выражение GROUP BY. Так, следующий пример работать не будет, так как он не содержит выражение группировки:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products
Другой пример, добавим группировку по количеству товаров:
SELECT Manufacturer, ProductCount, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer, ProductCount
Оператор может выполнять группировку по множеству столбцов.
Если столбец, по которому производится группировка, содержит значение NULL, то строки со значением NULL составят
отдельную группу.
Следует учитывать, что выражение должно идти после выражения , но до выражения
:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products WHERE Price > 30000 GROUP BY Manufacturer ORDER BY ModelsCount DESC
Фильтрация групп. HAVING
Оператор HAVING определяет, какие группы будут включены в выходной результат, то есть выполняет фильтрацию групп.
Применение HAVING во многом аналогично применению WHERE. Только есть WHERE применяется к фильтрации строк, то HAVING используется для фильтрации групп.
Например, найдем все группы товаров по производителям, для которых определено более 1 модели:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer HAVING COUNT(*) > 1
При этом в одной команде мы можем использовать выражения WHERE и HAVING:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products WHERE Price * ProductCount > 80000 GROUP BY Manufacturer HAVING COUNT(*) > 1
То есть в данном случае сначала фильтруются строки: выбираются те товары, общая стоимость которых больше 80000. Затем выбранные товары
группируются по производителям. И далее фильтруются сами группы — выбираются те группы, которые содержат больше 1 модели.
Если при этом необходимо провести сортировку, то выражение ORDER BY идет после выражения HAVING:
SELECT Manufacturer, COUNT(*) AS Models, SUM(ProductCount) AS Units FROM Products WHERE Price * ProductCount > 80000 GROUP BY Manufacturer HAVING SUM(ProductCount) > 2 ORDER BY Units DESC
В данном случае группировка идет по производителям, и также выбирается количество моделей для каждого производителя (Models)
и общее количество всех товаров по всем этим моделям (Units). В конце группы сортируются по количеству товаров по убыванию.
НазадВперед
Introduction to SQL GROUP BY clause
Grouping is one of the most important tasks that you have to deal with while working with the databases. To group rows into groups, you use the GROUP BY clause.
The GROUP BY clause is an optional clause of the SELECT statement that combines rows into groups based on matching values in specified columns. One row is returned for each group.
You often use the GROUP BY in conjunction with an aggregate function such as MIN, MAX, AVG, SUM, or COUNT to calculate a measure that provides the information for each group.
The following illustrates the syntax of the GROUP BY clause.
It is not mandatory to include an aggregate function in the SELECT clause. However, if you use an aggregate function, it will calculate the summary value for each group.
If you want to filter the rows before grouping, you add a WHERE clause. However, to filter groups, you use the HAVING clause.
It is important to emphasize that the WHERE clause is applied before rows are grouped whereas the HAVING clause is applied after rows are grouped. In other words, the WHERE clause is applied to rows whereas the HAVING clause is applied to groups.
To sort the groups, you add the ORDER BY clause after the GROUP BY clause.
The columns that appear in the GROUP BY clause are called grouping columns. If a grouping column contains NULL values, all NULL values are summarized into a single group because the GROUP BY clause considers NULL values are equal.
Группировка
Последнее обновление: 21.05.2018
Операторы GROUP BY и HAVING позволяют сгруппировать данные. Они употребляются в рамках команды SELECT:
SELECT столбцы FROM таблица
GROUP BY
Оператор GROUP BY определяет, как строки будут группироваться.
Например, сгруппируем товары по производителю
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer
Первый столбец в выражении SELECT — Manufacturer представляет название группы, а второй столбец — ModelsCount представляет результат функции Count,
которая вычисляет количество строк в группе.
И если в выражении SELECT производится выборка по одному или нескольким столбцам и также используются агрегатные функции, то необходимо использовать
выражение GROUP BY. Так, следующий пример работать не будет, так как он не содержит выражение группировки:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products
Оператор может выполнять группировку по множеству столбцов. Так, добавим группировку по количеству товаров:
SELECT Manufacturer, ProductCount, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer, ProductCount
Следует учитывать, что выражение должно идти после выражения , но до выражения
:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products WHERE Price > 30000 GROUP BY Manufacturer ORDER BY ModelsCount DESC
Фильтрация групп. HAVING
Оператор HAVING позволяет выполнить фильтрацию групп, то есть определяет, какие группы будут включены в выходной результат.
Использование HAVING во многом аналогично применению WHERE. Только есть WHERE применяется для фильтрации строк, то HAVING — для фильтрации групп.
Например, найдем все группы товаров по производителям, для которых определено более 1 модели:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer HAVING COUNT(*) > 1
В одной команде также можно сочетать выражения WHERE и HAVING:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products WHERE Price * ProductCount > 80000 GROUP BY Manufacturer HAVING COUNT(*) > 1;
То есть в данном случае сначала фильтруются строки: выбираются те товары, общая стоимость которых больше 80000. Затем выбранные товары
группируются по производителям. И далее фильтруются сами группы — выбираются те группы, которые содержат больше 1 модели.
Если при этом необходимо провести сортировку, то выражение ORDER BY идет после выражения HAVING:
SELECT Manufacturer, COUNT(*) AS Models, SUM(ProductCount) AS Units FROM Products WHERE Price * ProductCount > 80000 GROUP BY Manufacturer HAVING SUM(ProductCount) > 2 ORDER BY Units DESC;
Здесь группировка идет по производителям, и также выбирается количество моделей для каждого производителя (Models)
и общее количество всех товаров по всем этим моделям (Units). В конце группы сортируются по количеству товаров по убыванию.
НазадВперед
Example — Using GROUP BY with the MAX function
Finally, let’s look at how to use the GROUP BY clause with the MAX function.
Let’s use the employees table again, but this time find the highest salary for each dept_id:
| employee_number | last_name | first_name | salary | dept_id |
|---|---|---|---|---|
| 1001 | Smith | John | 62000 | 500 |
| 1002 | Anderson | Jane | 57500 | 500 |
| 1003 | Everest | Brad | 71000 | 501 |
| 1004 | Horvath | Jack | 42000 | 501 |
Enter the following SQL statement:
Try It
SELECT dept_id, MAX(salary) AS highest_salary FROM employees GROUP BY dept_id;
There will be 2 records selected. These are the results that you should see:
| dept_id | highest_salary |
|---|---|
| 500 | 62000 |
| 501 | 71000 |
In this example, we’ve used the MAX function to return the highest salary for each dept_id and we’ve aliased the results of the MAX function as highest_salary. The dept_id column must be listed in the GROUP BY clause because it is not encapsulated in the MAX function.
Пример — использование GROUP BY с функцией MAX
Наконец, давайте посмотрим, как использовать предложение GROUP BY с функцией MAX.
Давайте снова воспользуемся таблицей employees, но на этот раз найдем самую максимальную зарплату для каждого dept_id:
| employee_number | first_name | last_name | salary | dept_id |
|---|---|---|---|---|
| 1001 | Justin | Bieber | 62000 | 500 |
| 1002 | Selena | Gomez | 57500 | 500 |
| 1003 | Mila | Kunis | 71000 | 501 |
| 1004 | Tom | Cruise | 42000 | 501 |
Введите следующий SQL оператор:
PgSQL
SELECT dept_id,
MAX(salary) AS highest_salary
FROM employees
GROUP BY dept_id;
|
1 2 3 4 |
SELECTdept_id, MAX(salary)AShighest_salary FROMemployees GROUP BYdept_id; |
Будет выбрано 2 записи. Вот результаты, которые вы должны получить:
| dept_id | highest_salary |
|---|---|
| 500 | 62000 |
| 501 | 71000 |
В этом примере мы использовали функцию MAX, чтобы вернуть самое максимальное значение salary для каждого dept_id, и мы присвоили псевдоним «highest_salary» результату функции MAX. Столбец dept_id должен быть указан в предложении GROUP BY, поскольку он не инкапсулирован в функции MAX.
Примеры использования оператора GROUP BY
И для начала давайте создадим и заполним тестовую таблицу с данными, которой мы будет посылать наши запросы select с использованием группировки group by. Таблица и данные конечно выдуманные, чисто для примера.
Создаем таблицу
CREATE TABLE .(
NULL,
(50) NULL,
NULL,
NULL
) ON
GO
Я ее заполнил следующими данными:
Где,
- Id –идентификатор записи;
- Name – фамилия сотрудника;
- Summa- денежные средства;
- Priz – признак денежных средств (допустим 1- Оклад; 2-Премия).
Группируем данные с помощью запроса group by
И в самом начале давайте разберем синтаксис group by, т.е. где писать данную конструкцию:
Синтаксис:
Select агрегатные функции
From источник
Where Условия отбора
Group by поля группировки
Having Условия по агрегатным функциям

Order by поля сортировки
Теперь если нам необходимо просуммировать все денежные средства того или иного сотрудника без использования группировки мы пошлем вот такой запрос:
SELECT SUM(summa)as summa FROM test_table WHERE name='Иванов'
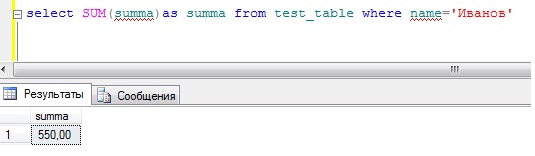
А если нужно просуммировать другого сотрудника, то мы просто меняем условие. Согласитесь, если таких сотрудников много, зачем суммировать каждого, да и это как-то не наглядно, поэтому нам на помощь приходит оператор group by. Пишем запрос:
SELECT SUM(summa)as summa, name FROM test_table GROUP BY name
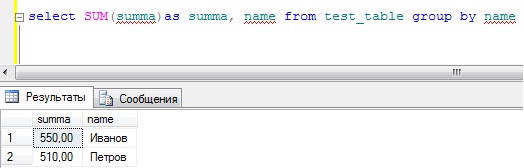
Как Вы заметили, мы не пишем никаких условий, и у нас отображаются сразу все сотрудники с просуммированным количеством денежных средств, что более наглядно.
Также можно использовать и другие функции, например, подсчитать сколько раз поступали денежные средства тому или иному сотруднику с общей суммой поступивших средств. Для этого мы кроме функции sum будем еще использовать функцию count.
SELECT SUM(summa)as ,
COUNT(*) as ,
Name
FROM test_table
GROUP BY name
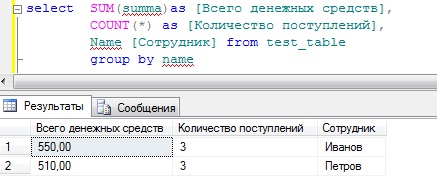
Но допустим для начальства этого недостаточно, они еще просят, просуммировать также, но еще с группировкой по признаку, т.е. что это за денежные средства (оклад или премия), для этого мы просто добавляем в группировку еще одно поле, и для лучшего восприятия добавим сортировку по сотруднику, и получится следующее:
SELECT SUM(summa)as ,
COUNT(*) as ,
Name ,
Priz
FROM test_table
GROUP BY name, priz
ORDER BY name
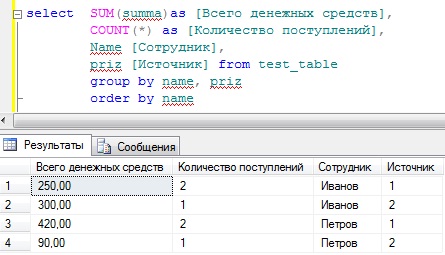
Теперь у нас все отображается, т.е. сколько денег поступило сотруднику, сколько раз, а также из какого источника.
А сейчас для закрепления давайте напишем еще более сложный запрос с группировкой, но еще добавим названия этого источника, так как согласитесь по идентификаторам признака не понятно из какого источника поступили средства. Для этого мы используем конструкцию case.
SELECT SUM(summa) AS ,
COUNT(*) AS ,
Name ,
CASE WHEN priz = 1 then 'Оклад'
WHEN priz = 2 then 'Премия'
ELSE 'Без источника'
END AS
FROM test_table
GROUP BY name, priz
ORDER BY name
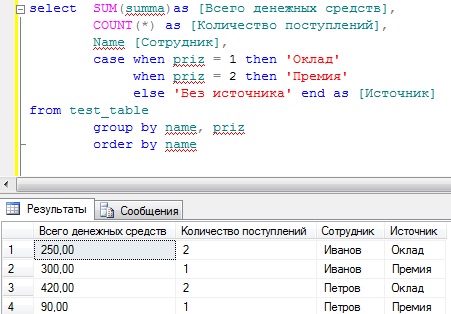
Вот теперь все достаточно наглядно и не так уж сложно, даже для начинающих.
Также давайте затронем условия по итоговым результатам агрегатных функций (having). Другими словами, мы добавляем условие не по отбору самих строк, а уже на итоговое значение функций, в нашем случае это sum или count. Например, нам нужно вывести все то же самое, но только тех, у которых «всего денежных средств» больше 200. Для этого добавим условие having:
SELECT SUM(summa)as ,
COUNT(*) as ,
Name ,
CASE WHEN priz = 1 then 'Оклад'
WHEN priz = 2 then 'Премия'
ELSE 'Без источника'
END AS
FROM test_table
GROUP BY name, priz --группируем
HAVING SUM(summa) > 200 --отбираем
ORDER BY name -- сортируем
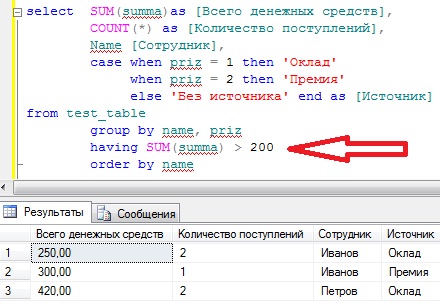
Теперь у нас вывелись все значения sum(summa), которые больше 200, все просто.
Надеюсь, после сегодняшнего урока Вам стало понятно, как и зачем использовать конструкцию group by. Удачи! А SQL мы продолжим изучать в следующих статьях.
Нравится2Не нравится
SQL GROUP BY examples
We will use the and tables in the sample database to demonstrate how the GROUP BY clause works.
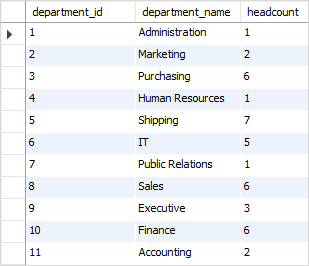
To find the headcount of each department, you group the employees by the column, and apply the COUNT function to each group as the following query:
To get the department name, you join the table with the table as follows:
SQL GROUP BY with ORDER BY example
To sort the departments by headcount, you add an ORDER BY clause as the following statement:
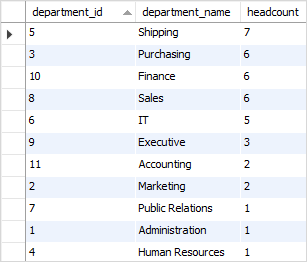
Note that you can use either the alias or the in the ORDER BY clause.
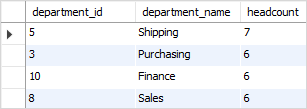
To find the department whose headcount is greater than 5, you use the HAVING clause as the following query:
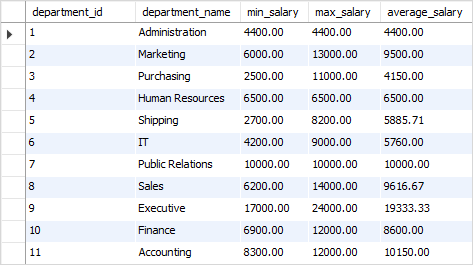
The following query returns the minimum, maximum, and average salary of employees in each department.
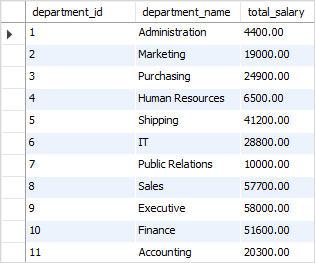
SQL GROUP BY with SUM function example
To get the total salary per department, you apply the SUM function to the column and group employees by the column as follows:
SQL Справочник
SQL Ключевые слова
ADD
ADD CONSTRAINT
ALTER
ALTER COLUMN
ALTER TABLE
ALL
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Функции
Функции строк
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Функции дат
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Функции расширений
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server функции
Функции строк
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Функции чисел
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Функции дат
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Функции расширений
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access функции
Функции строк
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Функции чисел
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Функции дат
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Другие функции
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL ОператорыSQL Типы данныхSQL Краткий справочник
Пример — две таблицы в операторе FROM (OUTER JOIN)
Рассмотрим как использовать FROM, когда мы соединяем вместе две таблицы, используя OUTER JOIN. В этом случае мы рассмотрим LEFT OUTER JOIN.
Давайте использовать те же таблицы products и categories, что и в примере INNER JOIN выше, но на этот раз мы объединим таблицы, используя LEFT OUTER JOIN. Введите следующий SQL оператор:
PgSQL
SELECT products.product_name, categories.category_name
FROM products
LEFT OUTER JOIN categories
ON products.category_id = categories.category_id
WHERE product_name <> ‘Pear’;
|
1 2 3 4 5 |
SELECTproducts.product_name,categories.category_name FROMproducts LEFT OUTER JOINcategories ONproducts.category_id=categories.category_id WHEREproduct_name<>’Pear’; |
Будет выбрано 6 записей. Вот результаты, которые вы должны получить:
| product_name | category_name |
|---|---|
| Banana | Produce |
| Orange | Produce |
| Apple | Produce |
| Bread | Bakery |
| Sliced Ham | Deli |
| Kleenex | NULL |
В этом примере FROM используется LEFT OUTER JOIN с таблицами products и categories на основе category_id в обеих таблицах.
Теперь в нашем наборе результатов появится последняя запись с product_name ‘Kleenex’ со значением NULL для category_name. Эта запись не появилась в наших результатах, когда мы выполняли INNER JOIN.
Introduction to MySQL GROUP BY clause
The clause groups a set of rows into a set of summary rows by values of columns or expressions. The clause returns one row for each group. In other words, it reduces the number of rows in the result set.
You often use the clause with aggregate functions such as , , , , and . The aggregate function that appears in the clause provides information about each group.
The clause is an optional clause of the statement. The following illustrates the clause syntax:
The clause must appear after the and clauses. Following the keywords is a list of comma-separated columns or expressions that you want to use as criteria to group rows.
MySQL evaluates the clause after the , and clauses and before the , and clauses:






