Генеративно-состязательная сеть
Содержание:
Генератор логотипов
Если у вас нет 100000 рублей на экспресс-дизайн в дизайнерской студии, но вам нужен логотип, попробуйте сервис Looka. Он спросит у вас название, любимые цвета, сферу деятельности и выяснит, какой стиль вам нравится, а потом выдаст много разных вариантов.
Вы можете выбрать любой из них, а можно взять один и допилить его в этом же сервисе и получить полноценный брендбук с визитками, лого на сайте, конвертами и прочими бизнес-атрибутами. Качество получается не хуже, чем у нейронки в студии дизайна, но даже платная подписка стоит гораздо дешевле, чем услуги дизайнера.
 Можно выбрать любой логотип и сразу использовать его для компании
Можно выбрать любой логотип и сразу использовать его для компании
От медицины до астрономии?
Если нейросеть не способна восстановить оригинальный портрет лица, то может делать прямо противоположное: видоизменять лица людей, где это требуется.
Метод пригодится полицейским, которым нужно скрыть лица информаторов или ключевых свидетелей, журналистам, не желающим раскрывать портреты анонимных или уязвимых собеседников. До сих пор лица таких людей приходилось размывать в фоторедакторе, при этом существовали опасения, что этот процесс может быть обратимым.
Система PULSE изящно решает эту задачу: вы видите четкий портрет, но узнать в нем реального человека невозможно.
Семейство этих методов может совершить прорыв в сфере медиа и кино, где достоверность образа не так важна.
Например, можно будет прогонять через модель старые фильмы, архивные кадры кинохроники или мультфильмы, получая на выходе формат сверхвысокого разрешения — 4-8 тысяч пикселей, что будет эстетически красиво, даже если герои не на 100% будут выглядеть, как в оригинале.
«Если мы возьмем за основу не крохотное изображение 16×16, как в этом исследовании, а разрешение с камеры в метро 254х254 и прогоним его через алгоритм, на выходе может получиться что-то правдоподобное», — отмечает Володин.
Генеративная сеть может взять за основу фотографии низкого разрешения почти любого содержания и превратить их в четкие изображения, утверждают исследователи.
Image caption
До сих пор получить подобное крупное четкое изображение лица из маленькой размытой фотографии, как сделал Декарт, казалось невозможным.
Сфера применения технологии потенциально может быть чрезвычайно широкой — от компьютерных изображений в медицине или астрономии до спутниковых снимков земных ландшафтов.
«Это возможно благодаря ограниченному числу возможных вариантов изображений. Почти все фотографии из астрономии — «черный фон и белые точки», или снимки с МРТ в медицине. В таких случаях нейросеть может быстро выучить эти вещи», — говорит Андрей Володин.
Вопрос только в доменах данных различных объектов, которые сейчас ограничены.
«Но если же мы говорим о бесконечном пространстве изображений, куда входят все фотографии всех лиц на Земле, метод авторов точно неприменим», — подводит итог ученый.
Если какая-либо информация отсутствует в исходном изображении — например, совершенно неразличимый номер на фотографии машины или маленькое пятнышко на отражении в зеркале, как в «Бегущем по лезвию», из которого вырастают все последующие события фильма, то восстановить это изображение до степени полного сходства, скорее всего, окажется невозможно в принципе.
Примечания
-
↑ Goodfellow, Ian J.; Pouget-Abadie, Jean; Mirza, Mehdi; Xu, Bing; Warde-Farley, David; Ozair, Sherjil; Courville, Aaron & Bengio, Yoshua (2014), «Generative Adversarial Networks»,
-
Salimans, Tim; Goodfellow, Ian; Zaremba, Wojciech; Cheung, Vicki; Radford, Alec & Chen, Xi (2016), «Improved Techniques for Training GANs»,
- Luc, Pauline (2016-11-25). «Semantic Segmentation using Adversarial Networks». NIPS Workshop on Adversarial Training, Dec , Barcelona, Spain 2016. arXiv:1611.08408.
- Andrej Karpathy, Pieter Abbeel, Greg Brockman, Peter Chen, Vicki Cheung, Rocky Duan, Ian Goodfellow, Durk Kingma, Jonathan Ho, Rein Houthooft, Tim Salimans, John Schulman, Ilya Sutskever, And Wojciech Zaremba, , OpenAI. Проверено 7 апреля 2016.
-
Schawinski, Kevin; Zhang, Ce; Zhang, Hantian; Fowler, Lucas & Santhanam, Gokula Krishnan (2017-02-01), «Generative Adversarial Networks recover features in astrophysical images of galaxies beyond the deconvolution limit»,
Обучение с подкреплением
Видеоигры основаны на системе стимулов. Завершите уровень и получите награду. Победите всех монстров и заработаете бонус. Попали в ловушку – конец игры, не попадайте. Эти стимулы помогают игрокам понять, как лучше действовать в следующем раунде игры. Без обратной связи люди бы просто принимали случайные решения и надеялись перейти на следующий игровой уровень.
Обучение с подкреплением (reinforcement learning) действует по тому же принципу. Видеоигры — популярная тестовая среда для исследований.
 Результат обучения с подкреплением — «агент» проходит трассу, не выезжая за ее пределы. Далее можно добивиться повышения скорости прохождения трассы.
Результат обучения с подкреплением — «агент» проходит трассу, не выезжая за ее пределы. Далее можно добивиться повышения скорости прохождения трассы.
Агенты ИИ пытаются найти оптимальный способ достижения цели или улучшения производительности для конкретной среды. Когда агент предпринимает действия, способствующие достижению цели, он получает награду. Глобальная цель — предсказывать следующие шаги, чтобы заработать максимальную награду в конечном итоге.
При принятии решения агент изучает обратную связь, новые тактики и решения способные привести к большему выигрышу. Этот подход использует долгосрочную стратегию — так же как в шахматах: следующий наилучший ход может не помочь выиграть в конечном счете. Поэтому агент пытается максимизировать суммарную награду.
Это итеративный процесс. Чем больше уровней с обратной связи, тем лучше становится стратегия агента. Такой подход особенно полезен для обучения роботов, которые управляют автономными транспортными средствами или инвентарем на складе.
Так же, как и ученики в школе, каждый алгоритм учится по-разному. Но благодаря разнообразию доступных методов, вопрос в том, чтобы выбрать подходящий и научить вашу нейронную сеть разбираться в среде.
Интересные статьи:
- Метод 3D-реконструкции волос по одному входному изображению
- Редактировать изображения стало проще с семантической разметкой, создаваемой нейросетью
- Реконструкция фотографий методом частичной свертки от Nvidia
Генератор текста
В сети есть много сервисов, которые делают «рыбный текст» — бессмысленный набор случайных слов, который просто похож на настоящий. По отдельности каждое слово что-то значит, но вместе это читается как ересь. Чтобы получился нормальный текст, одних случайных подстановок недостаточно — нужны нейросети.
Самой известной нейронкой, которая умеет строить осмысленный текст, стала GPT-2. Если её обучить на огромном количестве разных произведений, то она сможет написать продолжение любого текста за вас. Работает так: вы пишете начало, буквально абзац или пару предложений, и задаёте нужный размер. После этого нейронка читает, что написано у вас, и пишет продолжение в том же стиле. Если обучение прошло хорошо, то она выдаст такой текст, который сложно будет отличить от текста, написанного человеком.
У проекта GPT-2 есть только один недостаток: он отлично работает на английском и плохо — на других языках. Разработчик Михаил Гранкин решил это исправить и сделал сервис «Порфирьевич». Внутри та же GPT-2, но модифицированная для русского языка и обученная на художественной литературе и стихах. От вас нужно только начало, а дальше нейронка сделает всё сама.
 Мы отправили в сервис начало нашей статьи и получили вполне читабельный текст. Пока непонятно, к чему он приведёт, но логика в тексте есть
Мы отправили в сервис начало нашей статьи и получили вполне читабельный текст. Пока непонятно, к чему он приведёт, но логика в тексте есть
Просто покажите код
Вот пример GAN, запрограммированной в библиотеке Keras, из которой модели могут в дальнейшем быть импортированы в Deeplearning4j.
class GAN():
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=)
# Build and compile the generator
self.generator = self.build_generator()
self.generator.compile(loss='binary_crossentropy', optimizer=optimizer)
# The generator takes noise as input and generated imgs
z = Input(shape=(100,))
img = self.generator(z)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The valid takes generated images as input and determines validity
valid = self.discriminator(img)
# The combined model (stacked generator and discriminator) takes
# noise as input => generates images => determines validity
self.combined = Model(z, valid)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
noise_shape = (100,)
model = Sequential()
model.add(Dense(256, input_shape=noise_shape))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
model.summary()
noise = Input(shape=noise_shape)
img = model(noise)
return Model(noise, img)
def build_discriminator(self):
img_shape = (self.img_rows, self.img_cols, self.channels)
model = Sequential()
model.add(Flatten(input_shape=img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=img_shape)
validity = model(img)
return Model(img, validity)
def train(self, epochs, batch_size=128, save_interval=50):
# Load the dataset
(X_train, _), (_, _) = mnist.load_data()
# Rescale -1 to 1
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3)
half_batch = int(batch_size / 2)
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random half batch of images
idx = np.random.randint(0, X_train.shape, half_batch)
imgs = X_train
noise = np.random.normal(0, 1, (half_batch, 100))
# Generate a half batch of new images
gen_imgs = self.generator.predict(noise)
# Train the discriminator
d_loss_real = self.discriminator.train_on_batch(imgs, np.ones((half_batch, 1)))
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, np.zeros((half_batch, 1)))
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
noise = np.random.normal(0, 1, (batch_size, 100))
# The generator wants the discriminator to label the generated samples
# as valid (ones)
valid_y = np.array( * batch_size)
# Train the generator
g_loss = self.combined.train_on_batch(noise, valid_y)
# Plot the progress
print ("%d " % (epoch, d_loss, 100*d_loss, g_loss))
# If at save interval => save generated image samples
if epoch % save_interval == 0:
self.save_imgs(epoch)
def save_imgs(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, 100))
gen_imgs = self.generator.predict(noise)
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs.imshow(gen_imgs, cmap='gray')
axs.axis('off')
cnt += 1
fig.savefig("gan/images/mnist_%d.png" % epoch)
plt.close()
if __name__ == '__main__':
gan = GAN()
gan.train(epochs=30000, batch_size=32, save_interval=200)
Может быть интересно:
- Как работает нейронная сеть
- Рекуррентная нейронная сеть
- Как создать собственную нейронную сеть с нуля на языке Python
Новый подход к генерации изображений от Nvidia
Исследователи NVIDIA и Университета Аалто разработали инновационный подход к решению этих проблем, описанный в работе “Progressive Growing of GANs”. Идея проста: во время обучения обе нейросети (Генератор и Дискриминатор) развиваются посредством добавления новых слоёв. Помимо этого, исследователи ввели и другие улучшения в процесс обучения для генерации более реалистичных изображений в высоком разрешении.
 Предлагаемый метод последовательного развития GANs
Предлагаемый метод последовательного развития GANs
Развитие в процессе обучения
Идея заключается в том, чтобы позволить нейросети изучить сначала крупные структуры на изображении, а затем более мелкие. Это делает процесс обучения более стабильным, а также улучшает качество конечных изображений за счёт природы генеративных сетей, которые осуществляют сложное проецирование пространства скрытых переменных на реалистичное изображение. Поэтапное выполнение этого процесса легче, чем выполнение за один подход. В предлагаемой работе авторы используют зеркальные нейросети Генератора и Дискриминатора, начиная с очень малого разрешения (4х4 пикселя) и последовательно развивая нейросеть для работы с высоким разрешением (1024х1024).
Нормировка в генераторе и дискриминаторе
Для дальнейшего улучшения параметров генерируемого изображения авторы применяют нормировку данных в Генераторе и Дискриминаторе. Они выяснили, что деструктивная конкуренция между двумя нейросетями (Генератором и Дискриминатором) приводит к проблемам в обучении, и поэтому они предлагают ограничивать конкуренцию и амплитуду весов для более стабильного и быстрого обучения. Для достижения этой цели были использованы два метода: особая инициализация весов и попиксельная нормировка вектора особенностей изображения. Таким образом, в процессе обучения развивается не только нейросеть, но также и набор весов. Интересно, что такой подход улучшает результат, добавляя динамики в систему.
Инициализация весов заключается в следующем: веса инициализируются с помощью нормального распределения с нулевой средней и единичной дисперсией, и далее во время работы происходит их масштабирование. Это и есть ограничение амплитуды, о котором говорилось ранее. Такой подход улучшает процесс обучения в случае, если оптимизатор инвариантен относительно изменения масштаба весов (как RMSProp, ADAM и т.д.).
Идея попиксельной нормализации вектора особенностей заключается в приведении длины характеристического вектора к единице. Нормировка производится в Генераторе после каждого свёрточного слоя.
Предлагаемый метод прошёл испытания на датасете CELEBA, который содержит 30000 изображений лиц знаменитостей высокого разрешения (1024х1024) и поэтому хорошо подходит для проверки метода. Рассматриваемый метод показал более высокую реалистичность и гораздо большую вариативность изображений, чем существующие методы. Версия CELEBA с изображениями более высокого качества будет опубликована авторами в ближайшее время.
 Постепенное улучшение результатов при внесении различных улучшений. MS-SSIM — Multi-Scale Structural Similarity score — Мультимасштабная оценка структурного сходства. Тестирование проводилось с использованием датасетов CELEBA и LSUN
Постепенное улучшение результатов при внесении различных улучшений. MS-SSIM — Multi-Scale Structural Similarity score — Мультимасштабная оценка структурного сходства. Тестирование проводилось с использованием датасетов CELEBA и LSUN Сравнение качества генерируемых изображений на примере датасета LSUN
Сравнение качества генерируемых изображений на примере датасета LSUN
Концепт прогрессивной генеративной нейросети показал многообещающие результаты, и в ближайшее время мы можем ожидать появления новых приложений и улучшений данного подхода. Несмотря на это, нам предстоит ещё долгий путь к генерации изображений, которые будут неотличимы от реальных фотографий.
Оригинал — Dane Mitriev
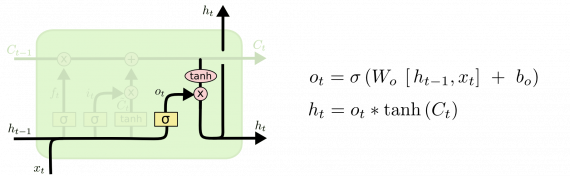
Пошаговая схема работы LSTM сети
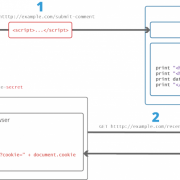
LSTM имеет три таких гейта для контроля состояния ячейки.
Слой утраты
На первом этапе LSTM нужно решить, какую информацию мы собираемся выбросить из состояния ячейки. Это решение принимается сигмовидным слоем, называемым «слоем гейта утраты». Он получает на вход h и x и выдает число от 0 до 1 для каждого номера в состоянии ячейки C. 1 означает «полностью сохранить», а — «полностью удалить».
Вернемся к нашему примеру лингвистической модел. Попытаемся предсказать следующее слово, основанное на всех предыдущих. В такой задаче состояние ячейки включает языковой род подлежащего, чтобы использовать правильные местоимения. Когда появляется новое подлежащее, уже требуется забыть род предыдущего подлежащего.
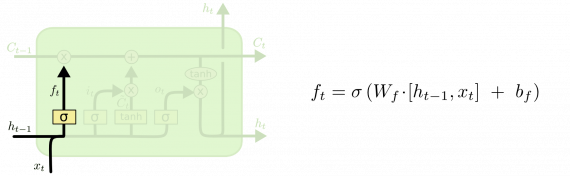
Слой сохранения
На следующем шаге нужно решить, какую новую информацию сохранить в состоянии ячейки. Разобьем процесс на две части. Сначала сигмоидный слой, называемый «слоем гейта входа», решает, какие значения требуется обновить. Затем слой tanh создает вектор новых значений-кандидатов C, которые добавляются в состояние. На следующем шаге мы объединим эти два значения для обновления состояния.
В примере нашей лингвистической модели мы хотели бы добавить род нового подлежащего в состояние ячейки, чтобы заменить им род старого.
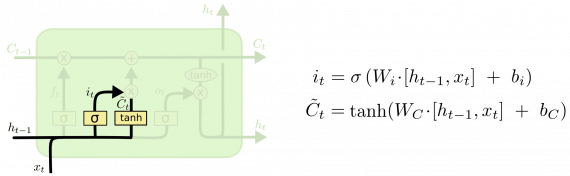
Новое состояние
Теперь обновим предыдущее состояние ячейки для получения нового состояния C. Способ обновления выбран, теперь реализуем само обновление.
Умножим старое состояние на f, теряя информацию, которую решили забыть. Затем добавляем i*C. Это новые значения кандидатов, масштабируемые в зависимости от того, как мы решили обновить каждое значение состояния.
В случае с лингвистической моделью мы отбросим информацию о роде старого субъекта и добавим новую информацию.
Наконец, нужно решить, что хотим получить на выходе. Результат будет являться отфильтрованным состоянием ячейки. Сначала запускаем сигмоидный слой, который решает, какие части состояния ячейки выводить. Затем пропускаем состояние ячейки через tanh (чтобы разместить все значения в интервале ) и умножаем его на выходной сигнал сигмовидного гейта.
Для лингвистической модели, так как сеть работала лишь с подлежащим, она может вывести информацию, относящуюся к глаголу. Например, сеть выведет информацию о том, в каком числе представлено подлежащее (единственное или множественное) для правильного спряжения глагола.
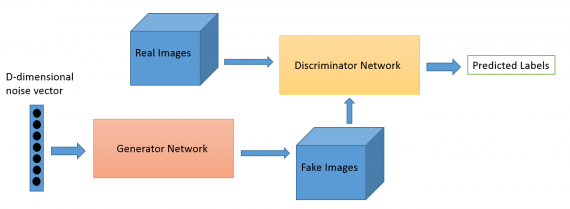
Как работают GAN
Одна нейронная сеть, называемая генератором, генерирует новые экземпляры данных, а другая — дискриминатор, оценивает их на подлинность; т.е. дискриминатор решает, относится ли каждый экземпляр данных, который он рассматривает, к набору тренировочных данных или нет.
Предположим, мы пытаемся сделать что-то более банальное, чем повторить портрет Моны Лизы. Мы сгенерируем рукописные цифры, подобные тем, что имеются в наборе данных MNIST. Цель дискриминатора — распознать подлинные экземпляры из набора.
Между тем, генератор создает новые изображения, которые он передает дискриминатору. Он делает это в надежде, что они будут приняты подлинными, хотя являются поддельными. Цель генератора состоит в том, чтобы генерировать рукописные цифры, которые будут пропущены дискриминатором. Цель дискриминатора — определить, является ли изображение подлинным.
Шаги, которые проходит GAN:
- Генератор получает рандомное число и возвращает изображение.
- Это сгенерированное изображение подается в дискриминатор наряду с потоком изображений, взятых из фактического набора данных.
- Дискриминатор принимает как реальные, так и поддельные изображения и возвращает вероятности, числа от 0 до 1, причем 1 представляет собой подлинное изображение и 0 представляет фальшивое.
Таким образом, у есть двойной цикл обратной связи:
- Дискриминатор находится в цикле с достоверными изображениями.
- Генератор находится в цикле вместе с дискриминатором
Вы можете представить GAN как фальшивомонетчика и полицейского, играющих в кошки мышки, где фальсификатор учится изготавливать ложные купюры, а полицейский учится их обнаруживать. Оба динамичны; т. е. полицейский тоже тренируется (возможно, центральный банк отмечает пропущенные купюры), и каждая сторона приходит к изучению методов другого в постоянной эскалации.
Сеть дискриминаторов представляет собой стандартную сверточную сеть, которая может классифицировать изображения, подаваемые на нее с помощью биномиального классификатора, распознающего изображения как реальные или как поддельные. Генератор в некотором смысле представляет собой обратную сверточную сеть: хотя стандартный сверточный классификатор принимает изображение и уменьшает его разрешение, чтобы получить вероятность, генератор принимает вектор случайного шума и преобразует его в изображение. Первый отсеивает данные с помощью методов понижения дискретизации, таких как maxpooling, а второй генерирует новые данные.
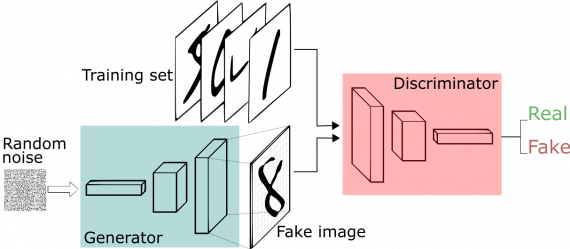
Обе сети пытаются оптимизировать целевую функцию или функцию потерь в игре zero-zum. Это, по сути, модель актера-критика (actor-critic). Когда дискриминатор меняет свое поведение, то и генератор меняет, и наоборот.
Генеративная и дискриминативная модели
Предположим, у нас есть два множества:
-
$O$ — множество наблюдаемых (observed) величин,
-
$H$ — множество скрытых (hidden) величин.
Тогда наличие генеративной (generative) модели означает, что мы знаем вероятность совместного распределения $P(o, h), o \in O, h \in H$. Таким
образом мы можем генерировать события при помощи данной модели.
Дискриминативная (discriminative) же модель означает, что мы знаем условную вероятность $P(h | o)$ и соответственно, можем, например,
классифицировать явление (найти наиболее вероятное значение скрытой переменной $h$), наблюдая нечто (зная значение наблюдаемой переменно $o \in O$)
Если генеративная модель известна, то используя формулу Байеса, можно получить дискриминативную модель.
Обычно по теме генеративных vs дискриминативных моделей ссылаются на статью .
Примеры
-
Если множества наблюдаемых и скрытых переменных конечны, то генеративную модель можно описать в виде таблицы:
$h_1$ $h_2$ … $h_N$ $o_1$ $P(o_1, h_1) = p_{11}$ $P(o_1, h_2) = p_{12}$ … $P(o_1, h_N) = p_{1N}$ $o_2$ $P(o_2, h_1) = p_{21}$ $P(o_2, h_2) = p_{22}$ … $P(o_2, h_N) = p_{2N}$ … … … … … $o_M$ $P(o_M, h_1) = p_{M1}$ $P(o_M, h_2) = p_{M2}$ … $P(o_M, h_N) = p_{MN}$ Дискриминативная модель получается из данной таблицы, применением формулы Байеса. Обозначим
$Z_i = \sum_{j=1}^N p_{ij}$
и получим:
$h_1$ $h_2$ … $h_N$ $o_1$ $P(h_1 \vert o_1) = p_{11} / Z_1$ $P(h_2 \vert o_1) = p_{12} / Z_1$ … $P(h_N \vert o_1) = p_{1N} / Z_1$ $o_2$ $P(h_1 \vert o_2) = p_{21} / Z_2$ $P(h_2 \vert o_2) = p_{22} / Z_2$ … $P(h_N \vert o_2) = p_{2N} / Z_2$ … … … … … $o_M$ $P(h_1 \vert o_M) = p_{M1} / Z_M$ $P(h_2 \vert o_M) = p_{M2} / Z_M$ … $P(h_N \vert o_M) = p_{MN} / Z_M$ -
Еще один пример описан раньше — это картинки рукописных цифр. Наблюдаемая величина это собственно картинка: 28 х 28, а скрытая величина — это
нарисована ли на картинке цифра. -
Хороший пример, это тексты на разных языках. Допустим, что в качестве наблюдаемой величины у нас выступает текст на каком-то языке, а в качестве
скрытой — собственно язык на котором текст написан.Генеративным подходом в данном случае будет: выучить все возможные языки и тогда мы будем иметь для каждого языка и текста вероятность их
совместимости. Дискриминативным же подходом будет только понять как языки отличаются, и приписывать текст к языку на базе этого знания. Можно,
например, ограничиться только текстами на двух языках: английском и русском и тогда для генеративного подхода надо всё равно изучить оба языка, а вот
для дискриминативного достаточно будет научиться отличать латиницу от кирилицы.
Zao
Платформа: | Цена: бесплатно
Технология глубокого подделки Zao позволяет вам модулировать голоса знаменитостей и накладывать свое лицо на тело актера в сцене.
Просто нажмите на одну фотографию и попробуйте тысячи модных причесок, одежды и макияжа. Приложение предоставляет вам множество видеоклипов, нарядов и буквально неограниченные возможности для изучения.
В 2019 году Zao за короткое время приобрел значительную популярность, позволив пользователям обмениваться лицами с любимыми актерами в коротких клипах из телепередач и фильмов. За месяц он стал самым загружаемым бесплатным приложением в Китае. С ростом популярности, его разработчики также столкнулись с критикой политики конфиденциальности приложения.
Это займет всего несколько секунд, чтобы поменять ваше лицо, но так как алгоритм в основном обучен на китайских лицах, это может выглядеть не так естественно, как вы ожидаете.
Тем не менее, все эти инструменты демонстрируют, как быстро развивался базовый ИИ: то, что раньше требовало тысячи картинок, чтобы сделать достаточно убедительное глубокое поддельное видео, теперь требует только одного изображения и дает лучшие результаты.
Состязательная сеть
Итак формально мы имеем некоторое множество $X$ примеров, и подмножество $Y \subset X$ позитивных примеров (например, $X$ множество всех картинок
размера 28 x 28, а подмножество $Y$ — набор MNIST картинок с рукописными цифрами), таким образом на множестве $X$ определено вероятностное
распределение $p_{data}(x)$. Мы хотим отыскать две функции (обе функции мы аппроксимируем при помощи многослойной нейронной сети):
-
$G(z, \theta_g)$. $z$ — случайный шум с каким-то наперёд заданным распределением $p_z(z)$. $\theta_g$ — параметры, которые будем тренировать. На
выходе функция $G$ будет выдавать элемент из множества $X$. Таким образом функция $G$ задаёт распределение $p_g(x)$. -
$D(x, \theta_d)$. $x \in X$, а $\theta_d$ — параметры дискриминативной сети. $D(x)$ — вещественное число — вероятность того, что $x$ взято из
подмножество $Y$, а не сгенерировано сетью $G$.
Мы одновременно тренируем сети представляющие функции $D$ и $G$. При этом мы ищем такие параметры $\theta_d$, чтобы максимизировать вероятность
правильного разделения функцией $D$ позитивных примеров и примеров сгенерированных функцией $G$. И такие параметры $\theta_g$, которые минимизируют
функцию $\log(1 — D(G(z)))$.
Можно переформулировать задачу как минимаксную игру для двух игроков с целевой функцией $V(G, D)$:
В работе теоретически обосновывается, что данная задача имеет глобальный оптимум $-\log(4)$ при $p_g(x) = p_{data}(x)$. Т.е. мы можем
натренировать такую функцию $G$, которая будет выдавать исходное распределение, и функция $D$ уже не сможет отличить примеры из тестового набора от
примеров генерируемых функцией $G$, а значит будет выдавать вероятность $0.5$ для всех примеров, что собственно и даёт нам в результате $-\log(4)$.
Алгоритм решающий задачу оптимизации, попеременно оптимизирует функцию $G$ при фиксированной $D$, а затем фиксируя $D$ улучшает функцию $G$. При
этом, так как на начальном этапе функция $G$ еще не достаточно хорошо умеет генерировать примеры похожие на тестовые, и $D$ назначает им очень
маленькую вероятность, то $\log(1-D(G(z)))$ близок к нулю, соответственно обучение параметров функции $G$ будет происходить медленно,
поэтому авторы предлагают вместо того, чтобы минимизировать $\log(1-D(G(z)))$ искать максимум $\log(D(G(z)))$. Это
эквивалентная задача, но при этом мы будем иметь, на начальном этапе обучения, большие по величине градиенты.
Итак в конечном итоге приходим к следующему алгоритму обучения:
Алгоритм тренировки генеративно-состязательных сетей
-
Для каждого шага тренировки:
-
Делаем $k$ итераций, оптимизируя дискриминатор $D$.
-
Генерируем $m$ примеров $\{z^{(1)}, z^{(2)}, …, z^{(m)}\}$, при помощи текущего варианта функции $G$.
-
Набираем $m$ позитивных примеров $\{x^{(1)}, x^{(2)}, …, x^{(m)}\}$ из тренировочного набора.
-
Обновляем параметры дискриминатора используя градиент:
\
-
-
Генерируем $m$ примеров $\{z^{(1)}, z^{(2)}, …, z^{(m)}\}$, при помощи текущего варианта функции $G$.
-
Обновляем параметры генератора используя градиент:
\
-
Гиперпараметр $k$ — количество шагов оптимизации дискриминатора на каждый шаг оптимизации генератора. Авторы предлагают использовать $k=1$
Результаты выдаваемые генеративной сетью, натренированной по описанному выше алгоритму на наборе MNIST
код для тренировки (не мой):

Здесь и дискриминативная и генеративная сети содержат два полносвязных слоя. А шум, подаваемый на вход генеративной сети, представляет из себя
случайный вектор размерности $100$, элементы которого соответствуют равномерному распределению на отрезке $$.
Литература
-
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio,
“Generative Adversarial Nets” arXiv:1406.2661 2014 -
Andrew Y. Ng, Michael I. Jordan, “On Discriminative vs. Generative classifiers: A comparison of logistic regression and naive Bayes”
NIPS