Учебник по языку sql (ddl, dml) на примере диалекта ms sql server. часть третья
Содержание:
Непротиворечивость чтения и пользовательские функции
Модель непротиворечивости чтения в базе данных Oracle проста и понятна: после выполнения запрос «видит» данные в том состоянии, в котором они существовали (были зафиксированы в базе данных) на момент начала запроса, с учетом результатов изменений, вносимых командами текущей транзакции. Таким образом, если мой запрос был выполнен в 9:00 и продолжает работать в течение часа, даже если за это время другой пользователь внесет в данные изменения, они не отразятся в моем запросе.
Но если не принять специальных мер предосторожности с пользовательскими функциями в ваших запросах, может оказаться, что ваш запрос будет нарушать (по крайней мере на первый взгляд) модель непротиворечивости чтения базы данных Oracle. Чтобы понять этот аспект, рассмотрим следующую функцию и запрос, в котором она вызывается:. Таблица account содержит 5 миллионов активных строк, а таблица orders — 20 миллионов
Я запускаю запрос в 10:00, на его завершение уходит около часа. В 10:45 приходит некто, обладающий необходимыми привилегиями, удаляет все строки из таблицы orders и закрепляет транзакцию. По правилам модели непротиворечивости чтения Oracle сеанс, в котором выполняется запрос, не должен рассматривать эти строки как удаленные до завершения запроса. Но при следующем вызове из запроса функция total_sales не найдет ни одной строки и вернет — и так будет происходить до завершения запроса
Таблица account содержит 5 миллионов активных строк, а таблица orders — 20 миллионов. Я запускаю запрос в 10:00, на его завершение уходит около часа. В 10:45 приходит некто, обладающий необходимыми привилегиями, удаляет все строки из таблицы orders и закрепляет транзакцию. По правилам модели непротиворечивости чтения Oracle сеанс, в котором выполняется запрос, не должен рассматривать эти строки как удаленные до завершения запроса. Но при следующем вызове из запроса функция total_sales не найдет ни одной строки и вернет — и так будет происходить до завершения запроса.
При выполнении запросов из функций, вызываемых в коде SQL, необходимо внимательно следить за непротиворечивостью чтения. Если эти функции вызываются в продолжительных запросах или транзакциях, вероятно, вам стоит выполнить следующую команду для обеспечения непротиворечивости чтения между командами SQL текущей транзакции:
В этом случае необходимо позаботиться о наличии достаточного табличного пространства отмены.
Расширенные функции
| Функция | Описание |
|
BIN |
Преобразует десятичное число в двоичное число |
|
BINARY |
Преобразует значение в двоичную строку |
|
CASE |
Позволяет вам оценить условия и вернуть значение при выполнении первого условия |
|
CAST |
Преобразует значение из одного типа данных в другой тип данных |
|
COALESCE |
Возвращает первое ненулевое выражение в списке |
|
CONNECTION_ID |
Возвращает уникальный идентификатор соединения для текущего соединения |
|
CONV |
Преобразует число из одной базы чисел в другую |
|
CONVERT |
Преобразует значение из одного типа данных в другой или один набор символов в другой |
|
CURRENT_USER |
Возвращает имя пользователя и имя хоста для учетной записи MySQL, используемой сервером, для проверки подлинности текущего клиента |
|
DATABASE |
Возвращает имя базы данных по умолчанию |
|
IF |
Возвращает одно значение, если условие TRUE или другое значение, если условие FALSE |
|
IFNULL |
Позволяет вернуть альтернативное значение, если выражение равно NULL |
|
ISNULL |
Проверяет, является ли выражение NULL |
|
LAST_INSERT_ID |
Возвращает первое значение AUTO_INCREMENT, заданное последним оператором INSERT или UPDATE |
|
NULLIF |
Сравнивает два выражения |
|
SESSION_USER |
Возвращает имя пользователя и имя хоста для текущего пользователя MySQL |
|
SYSTEM_USER |
Возвращает имя пользователя и имя хоста для текущего пользователя MySQL |
|
USER |
Возвращает имя пользователя и имя хоста для текущего пользователя MySQL |
|
VERSION |
Возвращает версию базы данных MySQL |
Секционирование
Элемент секционирования реализован как предложение PARTITION BY и поддерживается всеми оконными функциями. Он ограничивает текущее окно только теми строками результирующего набора запроса, у которых те же значения в столбцах секционирования, что и в текущей строке. Если, к примеру, в функции присутствует предложение PARTITION BY и значение custid в текущей строке равно 1, окно, связанное с текущей строкой, обеспечит выбор из результирующего набора всех строк, у которых значение custid равно 1. Если значение custid текущей строки равно 2, в окно войдут все строки с custid равным 2.
Если предложение PARTITION BY отсутствует, окно ничем не ограничивается. Можно относиться к этому по другому и считать, что явно секционирование не задано, а секционирование по умолчанию предусматривает, что весь результирующий набор запроса является одной секцией.
Если это не очевидно, то я замечу, что разные функции в одном запросе могут использовать разные определения секционирования. Посмотрите на следующий пример запроса с двумя функциями RANK:
Заметьте, что первая функция RANK (которая создает атрибут rnkall) полагается на секционирование по умолчанию, а во вторая — (она создает rnkcust) используется явное секционирование по custid. Следующий рисунок наглядно иллюстрирует секции, созданные в этом примере на основе трех результатов вычислений в запросе: одного результата вычисления значения rnkall и двух результатов — rnkcust:
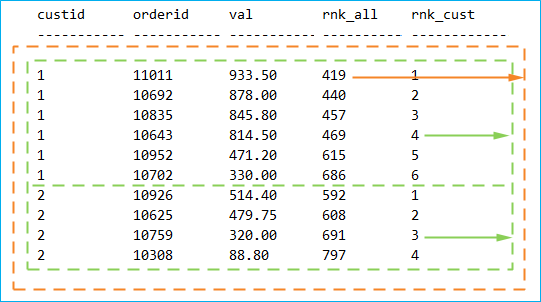
Стрелки показывают от результирующих значений функций на секции окон, которые были использованы для вычисления этих значений.
MAX() function with Having
In this article we have discussed how SQL HAVING CLAUSE can be used along with the SQL MAX() to find the maximum value of a column over each group. The SQL HAVING CLAUSE is reserved for aggregate function.
The usage of WHERE clause along with SQL MAX() have also described in this page.
The SQL IN OPERATOR which checks a value within a set of values and retrieve the rows from the table can also be used with MAX function.
Example :
Sample table :customer
To get data of ‘cust_city’, ‘cust_country’ and maximum ‘outstanding_amt’
from the customer table with following conditions —
1. the combination of ‘cust_country’ and ‘cust_city’ should make a group’
the following SQL statement can be used :
Output :
CUST_CITY CUST_COUNTRY MAX(OUTSTANDING_AMT) ----------------------------------- -------------------- -------------------- Bangalore India 12000 Chennai India 11000 London UK 11000 Mumbai India 12000 Torento Canada 11000
Pictorial Presentation :
Команда RETURN
В исполняемом разделе функции должна находиться по меньшей мере одна команда . Команд может быть и несколько, но в одном вызове функции должна выполняться только одна из них. После обработки команды выполнение функции прекращается, и управление передается вызывающему блоку.
Если ключевое слово в заголовке определяет тип данных возвращаемого значения, то команда RETURN в исполняемом разделе задает само это значение. При этом тип данных, указанный в заголовке, должен быть совместим с типом данных выражения, возвращаемого командой .
Любое допустимое выражение
Команда может возвращать любое выражение, совместимое с типом, обозначенным в секции. Это выражение может включать вызовы других функций, сложные вычисления и даже преобразования данных. Все следующие примеры использования допустимы:
Вы также можете возвращать сложные типы данных — экземпляры объектных типов, коллекции и записи.
Выражение в команде вычисляется в момент выполнения . При возврате управления в вызывающий блок также передается результат вычисленного выражения.
множественные команды
В функции total_sales на рис. 2 я использую две разные команды для обработки разных ситуаций в функции: если из курсора не удалось получить информацию, возвращается (не нуль). Если же от курсора было получено значение, оно возвращается вызывающей программе. В обоих случаях команда возвращает значение: в одном случае, в другом — переменную return_value.
Конечно, наличие нескольких команд в исполняемом разделе функции разрешено, однако лучше ограничиться одной командой RETURN, размещаемой в последней строке исполняемого раздела. Причины объясняются в следующем разделе.
как последняя исполняемая команда
В общем случае команду желательно делать последней исполняемой командой; это лучший способ гарантировать, что функция всегда возвращает значение. Объявите переменную с именем return_value (которое четко указывает, что в переменной будет храниться возвращаемое значение функции), напишите весь код вычисления этого значения, а затем в самом конце функции верните значение return_value командой:
Переработанная версия логики на рис. 2, в которой решена проблема множественных команд , выглядит так:
Остерегайтесь исключений! Помните, что инициированное исключение может «перепрыгнуть» через последнюю команду прямо в обработчик. Если обработчик исключения не содержит команды , то будет выдана ошибка ORA-06503: независимо от того, как было обработано исходное исключение.
Вас заинтересует / Intresting for you:
Встроенные методы коллекций PL… 4432 просмотров sepia Tue, 29 Oct 2019, 09:54:01
Управление приложениями PL/SQL… 2182 просмотров Rasen Fasenger Thu, 16 Jul 2020, 06:20:48
Символьные функции и аргументы… 7478 просмотров Анатолий Wed, 23 May 2018, 18:54:01
Тип данных RAW в PL/SQL 3606 просмотров Doctor Thu, 12 Jul 2018, 08:41:33
Author: Анатолий
Другие статьи автора:
SQL Server String Functions
| Function | Description |
|---|---|
| ASCII | Returns the ASCII value for the specific character |
| CHAR | Returns the character based on the ASCII code |
| CHARINDEX | Returns the position of a substring in a string |
| CONCAT | Adds two or more strings together |
| Concat with + | Adds two or more strings together |
| CONCAT_WS | Adds two or more strings together with a separator |
| DATALENGTH | Returns the number of bytes used to represent an expression |
| DIFFERENCE | Compares two SOUNDEX values, and returns an integer value |
| FORMAT | Formats a value with the specified format |
| LEFT | Extracts a number of characters from a string (starting from left) |
| LEN | Returns the length of a string |
| LOWER | Converts a string to lower-case |
| LTRIM | Removes leading spaces from a string |
| NCHAR | Returns the Unicode character based on the number code |
| PATINDEX | Returns the position of a pattern in a string |
| QUOTENAME | Returns a Unicode string with delimiters added to make the string a valid SQL Server delimited identifier |
| REPLACE | Replaces all occurrences of a substring within a string, with a new substring |
| REPLICATE | Repeats a string a specified number of times |
| REVERSE | Reverses a string and returns the result |
| RIGHT | Extracts a number of characters from a string (starting from right) |
| RTRIM | Removes trailing spaces from a string |
| SOUNDEX | Returns a four-character code to evaluate the similarity of two strings |
| SPACE | Returns a string of the specified number of space characters |
| STR | Returns a number as string |
| STUFF | Deletes a part of a string and then inserts another part into the string, starting at a specified position |
| SUBSTRING | Extracts some characters from a string |
| TRANSLATE | Returns the string from the first argument after the characters specified in the second argument are translated into the characters specified in the third argument. |
| TRIM | Removes leading and trailing spaces (or other specified characters) from a string |
| UNICODE | Returns the Unicode value for the first character of the input expression |
| UPPER | Converts a string to upper-case |
Функции распределения рангов
В соответствии со стандартом SQL, аналитические функции вычисляют относительный ранг строки в секции окна, выраженный как дробное число от нуля до единицы, которое большинство воспринимает как процент. Две разновидности — PERCENT_RANK и CUME_DIST — выполняют вычисления немного по-разному.
Допустим, rk это RANK строки, в котором используется то же определение окна, что и в определении окна в аналитической функции. Также допустим, что nr — число строк в секции окна. Еще представим, что np — число строк, которое предшествует или находится на одном уровне с текущей строкой (то же самое, что минимальное значение rk, которое больше, чем текущее значение rk за вычетом единицы или nr, если текущее значение rk является максимальным).
Тогда PERCENT_RANK вычисляется так: (rk — 1) / (nr — 1). A CUME_DIST рассчитывается так: np / nr. Следующий запрос вычисляет как процентильный ранг, так и интегральное распределение результатов студентов, секционированных по testid и упорядоченных по score:
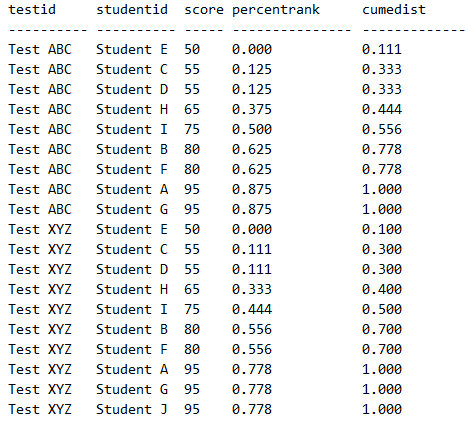
Тем, кто не знаком со статистическим анализом, будет сложно понять смысл этих вычислений. Грубо говоря, процентильный ранг в данном примере можно считать долей студентов, у которых результаты меньше текущего результата, а интегральное распределение — долей студентов, у которых результаты меньше или равны текущему результату.
До SQL Server 2012 вычисление процентильного ранга выполнялось довольно прямолинейно, потому что rk можно вычислить с помощью оконной функции RANK, а nr — с помощью агрегирующей оконной функции COUNT, обе эти функции имеются в SQL Server, начиная с SQL Server 2005. С вычислением интегрального распределения сложнее, потому что для обсчета текущей строки требуется значение rk, связанное с другой строкой. В результате вычисления мы должны получать минимальный rk, который больше текущего rk, или nr, если текущий rk является максимальным. Решить задачу можно с помощью связанного вложенного запроса.
Вот запрос (его можно выполнять в SQL Server 2005 и последующих версиях), вычисляющий как процентильный ранг, так и интегральное распределение:
Причина использования числового значения «1.0» во второй части в том, чтобы принудительно выполнить неявное преобразование целочисленных операндов в числовые, потому что в противном случае мы получим целочисленное деление.
Вот еще один пример — запрос вычисляет процентильный ранг и интегральное распределение числа заказов у сотрудников:
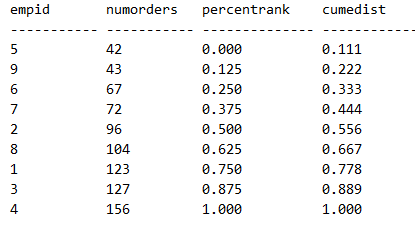
Обратите внимание на совмещение функций групповых агрегатов с оконными функциями распределения рангов — это очень похоже на ранее обсуждаемое совмещение функций групповых агрегатов и агрегирующих оконных функций






