Основы linux от основателя gentoo. часть 4 (1/4): файловые системы, разделы и блочные устройства
Содержание:
Файловые системы ext3 и ext4
Дисковые файловые системы и расширенные файловые системы
По большей части в этой статье обсуждается работа с семейством расширенных файловых систем Linux (ext). Однако среди прочих файловых систем Linux поддерживает и множество дисковых файловых систем, например, XFS, ReiserFS, Btrfs (B-tree File System) и JFS (IBM Journaled File System). В зависимости от задач, выполняемых на вашем компьютере и в вашей рабочей среде, какие-то из этих файловых систем могут оказаться более подходящими, чем расширенная файловая система. Тем не менее знакомство с расширенной файловой системой является хорошей отправной точкой, поскольку в большинстве дистрибутивов Linux по умолчанию используется файловая система ext3 или ext4.
Файловая система ext3 является результатом дальнейшего развития более ранней файловой системы ext2 и широко используется в настоящее время. Одним из важных принципиальных отличий ext3 от ext2 является наличие журналирования. Файловая система ext3 обратно совместима с ext2, поэтому для перехода с ext2 на ext3 нет необходимости повторно разбивать диск на разделы. Обычно для этого достаточно запустить команду с привилегиями пользователя root. Например, если файловая система ext2 используется на втором разделе первого жесткого диска, то для ее преобразования в ext3 достаточно запустить команду .
Помимо журналирования, в ext3 реализован и ряд других улучшений по сравнению с ext2, например, повышенная скорость и надежность. Не обладая возможностями журналирования, файловая система ext2 страдала из-за «грязных» перезагрузок операционной системы (например, в случае непредвиденного отключения электропитания или краха системы). Во время загрузки компьютера каждую файловую систему ext2 нужно было проверять перед ее монтированием. Учитывая современные объемы файловых систем, время проверки целостности в большинстве случаев оказывается неприемлемым, поскольку этот долгий процесс существенно снижает доступность системы. В журналируемых файловых системах (как, например, NTFS) данные записываются на диск и помечаются либо как целостные, либо как нецелостные. Поэтому при «грязной» перезагрузке проверяются только те файлы, помеченные как нецелостные, что устраняет необходимость проверки всей файловой системы. В ext3 предусмотрено три режима журналирования:
- Journal. Полное журналирование данных. Записываются не только метаданные, но и сами данные. Это самый медленный режим.
- Ordered. Формально записываются только метаданные, но этот способ может устранять повреждения, связанные с отложенной записью, поскольку сначала выполняется запись в блоки данных.
- Writeback. Журналируются только метаданные, но не сами данные. Это самый быстрый режим.
Последней версией расширенной файловой системы на сегодняшней день является файловая система ext4, обратно совместимая с ext2 и ext3. По сравнению с ext3 в ext4 реализован ряд улучшений, в основном касающихся скорости и надежности. Файловая система ext4 имеется в Linux с версией ядра 2.6.28 и выше.
В таблице 1 показаны некоторые основные характеристики наиболее распространенных файловых систем Linux, которые помогут вам планировать схемы разделов или преобразовывать существующие разделы.
Таблица 1. Эволюция расширенной файловой системы
| Файловая система | |
|---|---|
| Extended file system | (приблизительно с 1991 г.) Самая ранняя файловая система Linux. Недостатком этой файловой системы является чрезмерная фрагментация. |
| Ext2 | (приблизительно с 1993 г.) Эта файловая система обладает высокой надежностью, но в ней отсутствует журналирование. После внезапной перезагрузки или сбоя системы для всей файловой системы запускается команда . |
| Ext3 | (приблизительно с 2001 г.) Эта файловая система может содержать 32 000 поддиректорий, поддерживает журналирование и обратно совместима с файловой системой ext2. |
| Ext4 | (приблизительно с 2008 г.) Эта файловая система может содержать 64 000 поддиректорий, позволяет полностью отключить журналирование (в отличие от ext3) и обратно совместима с файловыми системами ext2 и ext3. |
Файловые системы для флэш-носителей
В Linux доступно несколько таких файловых систем. В следующих разделах вы узнаете об их архитектуре и преимуществах.
Журналируемая файловая система для флэш-носителей
Журналируемая файловая система для флэш-носителей (Journaling Flash File System, JFFS) является одной из первых систем для флэш в Linux. JFFS, в основе структуры которой лежит журнал, предназначалась для NOR-устройств. Система на тот момент являлась уникальной и разрешала множество проблем флэш-носителей, но имела один существенный недостаток.
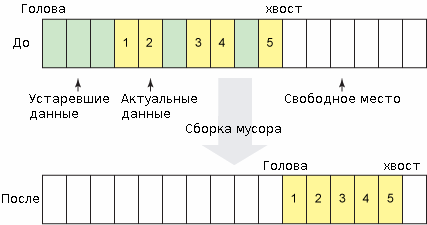
JFFS оперирует флэш-памятью на основе циклического журнала блоков. Данные на запись пишутся в блоки из хвоста журнала, а головные блоки готовятся для повторного использования. Диапазон между хвостом и головой журнала означает свободное место. Когда его становится слишком мало, в дело вступает сборщик мусора, который находит среди устаревших и дефектных блоков блоки с актуальными данными, перемещает их в хвост, а затем освободившееся место стирает (рис. 2). В результате такого подхода происходит как статическая, так и динамическая оптимизация износа. Проблема данного метода состоит в том, что отсутствует эффективная стратегия стирания — флэш-память слишком часто подвергается стиранию. Поэтому износ устройства происходит слишком быстро.
Рисунок 2. Циклический журнал до и после срабатывания сборщика мусора
Во время монтирования структура и расположение блоков считываются в память, поэтому монтирование JFFS-раздела происходит медленно; также можно заметить, что при этом потребляется довольно много оперативной памяти.
Снижая срок службы NOR-носителей из-за своего алгоритма оптимизации износа, система JFFS тем не менее довольно широко применялась. В результате было решено переработать ее алгоритм и отказаться от циклического журнала. Так появилась JFFS2, ориентированная на NAND-память. Эта система демонстрирует более высокую скорость работы и имеет функцию сжатия.
JFFS2 рассматривает каждый блок флэш-памяти независимо от других. Для эффективной оптимизации износа ведутся специальные списки. Список чистых блоков соответствует блокам, которые содержат только пакеты с актуальными данными. Список грязных блоков содержит блоки, каждый из которых имеет хотя бы один пакет с устаревшими данными. Список свободных блоков хранит сведения о блоках, которые были стерты и уже готовы к использованию.
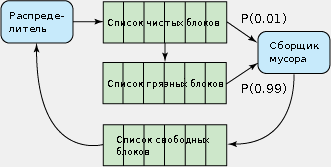
В этих условиях алгоритм сборки мусора может в зависимости от ситуации эффективно принимать решение о том, какие блоки готовить к повторному использованию. В текущих реализациях алгоритм выбирает их из списков либо чистых, либо грязных блоков на основе заданной вероятности. В 99% случаев используется список грязных блоков (при этом актуальные данные переносятся в другой блок). В 1% случаев берется список чистых блоков (при этом все содержимое просто переносится в новый блок). В любом случае целевой блок стирается и заносится в список свободных блоков (рис. 3). Все это позволяет сборщику мусора повторно использовать блоки с неактуальными данными (или частично неактуальными), в то время как данные все равно «проходят» всю память, что и дает статическую оптимизацию износа.
Рисунок 3. Управление блоками и сборка мусора в JFFS2
Альтернативная файловая система для флэш-носителей (YAFFS, Yet Another Flash File System)
YAFFS была разработана для флэш-памяти NAND-типа. Первая реализация системы поддерживает устройства, имеющие размер страницы 512 байт, а более новая — современные носители с большим размером страницы и более серьезными ограничениями записи.
В большинстве файловых систем для флэш-памяти блоки с неактуальной информацией просто помечаются как таковые. Однако в YAFFS2 эти блоки дополнительно маркируются числами возрастающей арифметической прогрессии. Во время монтирования происходит сканирование файловой системы, при котором пакеты с актуальными данными легко идентифицируются. Расположение блоков хранится в виде деревьев в оперативной памяти, что позволяет значительно ускорить монтирование за счет снимков. Снимок подразумевает сохранение этих деревьев во флэш-память при размонтировании. Тогда при последующем монтировании эти структуры быстро считываются и восстанавливаются в памяти (рис. 4). Быстрое монтирование — одно из главных преимуществ YAFFS2 перед аналогами.
Going further
Journaling file systems provide reliability and protect against corruption in the
face of system crash or power loss. Additionally, the crash recovery time for
journaling file systems is dramatically reduced compared to more traditional file
system methods (such as those that rely on ).
Development of new journaling capabilities continues to look to the future at new
algorithms and structures as well as to the past, where features of JFS and XFS
are incorporated. How journaling file systems will evolve in the future is
unclear, but their usefulness is clear, and they are the new file system standard.
Related topics
- The
list
of file systems on Wikipedia ranges
from the earliest DEC file systems of the 1960s to the latest BufferFS
from Oracle. To round out your file system knowledge, also check out this
file system reading
list,
which covers a wide range of file system topics. -
JFS
(and its successor, JFS2)
were the earliest journaled file systems. They continue to be used in Linux and
the AIX operating systems. -
XFS was the earliest journaling
file system that focused on high performance. Learn more about the
development and future of XFS
at the SGI home page. - The current leader in Linux journaling file
systems (as far as deployments go) is the
third extended file system
(successor to the
second extended file
system).
Read more about the transformation of ext2 to ext3 in the interesting
paper,
«Journaling
the Linux ext2fs Filesystem» (PDF),
or in this
talk
given by the ext3fs designer, Dr. Stephen Tweedie. - The
Reiser file system was the
first journaling file system to be adopted into the mainline Linux kernel. -
On 28 April 2008,
Hans Reiser
(owner of Namesys, developer of Reiser file systems) was convicted for the murder
of his estranged wife. Namesys has ceased to exist, and work on the Reiser4 file
system has also stopped (although there is
speculation about the future of Reiser4
in the Linux kernel). -
Tim’s «Anatomy
of the Linux file system»
(developerWorks, Oct 2007) introduces you to the VFS
and its major structures. The Linux VFS layer provides an abstraction
using a common application program interface (API) to the various supported
underlying file systems. - The future of journaling file systems is
ext4fs. The presentation,
«Ext4: The
Next Generation of Ext2/3 Filesystem» (PDF),
provides a wealth of technical details for ext4fs. Finally, you can learn more
about the development of ext4fs from the
development wiki and
also about the
online
defragmentation approach. - Read
all
of Tim’s Anatomy of… articles
on developerWorks. - Read
all
of Tim’s Linux articles
on developerWorks. - In the
developerWorks Linux zone,
find more resources for Linux developers, and scan our
most popular articles and
tutorials. - See all
Linux tips
andLinux tutorials
on developerWorks.
Устройство файловых систем ОС Linux
А сам по себя список inodes, соответствующих как существующим файлам, так и независимым блокам дискового раздела, и определяет границы файловой системы, то имеется сколько файлов может быть в ней создано. В данном разделе будет говориться о предметах, общих для абсолютно всех Linux. Все файлы в Linux физически состоят из 2 частей, реально локализованных в различных блоках атриторного накопителя, но обязательно находящихся в одном дисковом разделе, основном или логическом. Первая часть файла — его так называемые метаданные, какие содержат файловый дескриптор (это просто некое чудесное число), сведения о его атрибутах (принадлежности, правах доступа, времени изменения и т.д.), а также информацию о том, в каких блоках атриторного раздела (которые так и называются — блоки данных) физиологически размещено содержимое файла — те самые последовательности б, которые образуют доступный пользователю ASCII-текст или выполняемый модуль программы. Метаданные каждого файла вписаны в специальной области диска, называемой суперблоком, где образуют т.н. inodes (от information nodes — информативные узлы). Каждому существующему файлу соответствует собственный inode, и именно он однозначно идентифицируется файловым дескриптором.
Так вот, сущность процесса создания файловой системы на дисковом разделе (или, в осмысливании DOS/Windows, его форматирования) — в создании на нем суперблока (или, в некоторых файловых системах, многих его копий), списка inodes и отведении дискового места под блоки данных (а также загрузочного блока, о каком будет сказано ниже), а устройством этих атриторных областей определяются различия между файловыми системами разных типов. В результате на новом разделе образуется один-единственный файл — каталог корневого (для данной файловой системы) разоблачила (в некоторых случаях создается еще и каталог /lost+found, нужный для хранения нарушенных файлов).
Ответ прост: в Linux имя представляет собой атрибут не файла, но файловой системы (в 5-ом, логическом, понимании термина). Поэтому идущая от MacOS и деятельно используемая в Windows метафора каталога как папки с бумагами — в Linux только затемняет суть дела: тут это скорее именно каталожный ящик в библиотеке. Выясняет вопрос, почему такой, казалось бы неотъемлемый, свойство файла, как его имя, не обнаруживается ни в его метаданных, ни, тем более, среди его этих. Они представляют собой просто списки файловых дескрипторов идентификаторов и определенных им имен файлов. И для хранения имен файлов нужны файлы особого типа — каталоги (в Linux имеется и другие типы файлов, например, упомянутые реке файлы устройств).
Не смотря на столь простое механизм, роль каталогов в файловой системе Linux нелегко переоценить: имена файлов, через которые они врубаются в файловую систему (и через которые пользователь приобретает доступ к их содержимому), фигурируют только в составе каталога, к какому файл приписан — и больше нигде в системе. Только так осуществляется удаление файла командой rm или файловым клерком типа Midnoght Commander. Так что удаление имени файла (или подсправочника) из списка, представляющего собой данные его родительского каталога (какой, конечно, также имеет свой inode и файловый дескриптор, сваленный к каталогу, расположенному уровнем выше в иерархии файловой системы, и так дальше) равносильно тому, что метаданные файла становится недосягаемыми, а приписанные к его inode блоки данных помечаются как независимые.
Кроме того, в inode ее корневого каталога ставится т.н. бит чистого размонтирования (clean bit). Пока же рассмотрим характерные черты файловых систем, используемых в Linux’е. Обратный процесс — размонтирование, последствием чего является отсоединение от точки монтирования бревна смонтированной файловой системы. Из сказанного понятно, что для данного она со всем ее содержимым (суперблоком, списком inode, блоками этих) должна быть включена в состав какого-либо из имеющийся каталогов, называемого точкой монтирования. Именно это и сочиняет суть процесса монтирования. Впрочем, вопросам монтирования и размонтирования файловых систем станет посвящена специальная статья. Результат же для монтируемой файловой системы — в том, что ее крупнокорневой каталог (до сих пор безымянный) получает имя каталога — точки монтирования (mount point), содержание которого отныне составляет список имен ее файлов и подсправочников. Нас, однако, сейчас интересует прямо противоположное — делать файловую систему доступной.
Архитектура высокого уровня
Хотя большая часть кода файловой системы реализована в ядре (за исключением файловых систем пространства пользователя, о которых я расскажу ниже), архитектура, показанная на рисунке 1, характеризует отношения между основными компонентами файловой системы, как в пространстве пользователя, так и в ядре.
Рисунок 1. Архитектурное представление компонентов файловой системы Linux
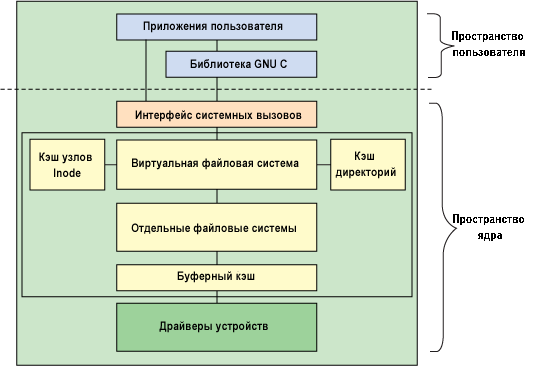
В пространстве пользователя размещаются приложения (в этом примере — пользователь файловой системы) и библиотека GNU C (glibc), которые предоставляют интерфейс для вызова файловой системы (открытие, чтение, запись, закрытие). Интерфейс системных вызовов действует как коммутатор, направляющий системные вызовы из пространства пользователя в соответствующую точку пространства ядра.
VFS является основным интерфейсом к файловым системам нижнего уровня. Этот компонент экспортирует набор интерфейсов и после этого абстрагирует их в отдельные файловые системы, образ поведения которых может быть весьма различным. Для объектов файловой системы (узлов inodes и записей dentries) существуют два кэша, о которых я скоро расскажу. Каждый из них предоставляет пул недавно использованных объектов файловой системы.
Реализация каждой файловой системы, например, ext2, JFS и так далее, экспортирует общий массив интерфейсов, который используется (и ожидается) VFS. Буферный кэш буферизирует запросы между файловыми системами и блочными устройствами, которыми они могут управлять. Например, через буферный кэш проходят запросы на чтение и запись к драйверам устройств. Это позволяет кэшировать запросы для более быстрого доступа (вместо обращения к физическому устройству). Буферный кэш управляется набором списков последних использованных элементов (least recently used, LRU)
Обратите внимание, что командой можно сбросить буферный кэш на носитель (принудительно отправить все незаписанные данные на драйверы устройств и, в дальнейшем, на устройства хранения)
Что такое блочное устройство?
Блочным называется устройство, данные на которое и с которого передаются блоками (например, секторами диска), и которое поддерживает такие атрибуты, как буферизация и прямой доступ (устройство не требует последовательного доступа к блокам при чтении — любой блок может быть доступен в любое время). К блочным устройствам относятся жесткие диски, CD-ROM и диски в оперативной памяти. Они являются противоположностью символьным устройствам, отличие которых состоит в том, что у них нет носителя с физической адресацией. К символьным устройствам относятся последовательные порты и ленточные устройства, в которых данные передаются посимвольно.
Это был общий взгляд на компоненты файловой системы и VFS. Давайте теперь рассмотрим основные структуры, составляющие эту подсистему.
Как хранятся данные
В файловой системе Linux хранятся два типа данных. Первый тип – это пользовательские данные (обычные файлы и директории, с которыми работают пользователи). Файлы также могут быть четырех типов: обычные файлы, ссылки, именованные каналы (FIFO) и сокеты.
Возможно, вы слышали выражение «В Linux все является файлами или процессами». Это выражение подразумевает тот факт, что в Linux отсутствует концепция системного реестра. Вместо этого все объекты хранятся в виде одного из четырех типов файлов. Другой тип данных, хранящихся в файловой системе – это метаданные, являющиеся индексными дескрипторами (index node) и обычно называемые inode. Индексные дескрипторы являются способом индексации атрибутов файлов в Linux. Каждый файл имеет свой inode, который обычно содержит следующую информацию:
Учетная запись обычного пользователя и команды с привилегиями пользователя root
Обратите внимание на то, что все команды в листингах этой статьи начинаются с символов или , которые имеют в командном интерпретаторе Linux определенные значения. Символ в командной строке означает, что пользователь работает с обычными правами, тогда как символ означает, что пользователь имеет привилегии учетной записи root (т
е. является администратором). Когда вы встречаете в листингах команду, начинающуюся с символа , то для ее выполнения у вас должен быть доступ к команде или к учетной записи пользователя root, позволяющей выполнить команду напрямую.
- Размер файла.
- Владельцы файла (пользователь и группа).
- Файловые разрешения.
- Количество жестких и мягких ссылок.
- Время последнего доступа и изменения файла.
- Информацию о списке контроля доступа (ACL).
- Любые дополнительные атрибуты, определенные для файла (например, признак неизменяемости).
В листинге 1 приведен пример использования команды , позволяющей получить информацию, хранящуюся в inode.
Листинг 1. Использование команды stat
$ stat /etc/services File: `/etc/services' Size: 362031 Blocks: 728 IO Block: 4096 regular file Device: fd00h/64768d Inode: 1638437 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root) Access: 2011-12-19 00:01:25.000000000 -0600 Modify: 2006-02-23 07:09:23.000000000 -0600 Change: 2011-09-18 17:29:37.000000000 -0500
В листинге 1 команда была выполнена для файла /etc/services. В результате ее выполнения мы получили в наглядном виде всю информацию индексного дескриптора и файловые атрибуты.
Директории
При работе в командной строке Linux вы будете видеть файловые папки, часто называемые директориями. Директории служат для тех же целей, что и папки Windows или папки графического интерфейса Linux. Но в действительности директории – это всего лишь пустые файлы для упорядочения других файлов или даже директорий.
Все директории упорядочены в иерархическую структуру, начинающуюся с корневой директории (/). В действительности это лишь логическое упорядочение, поскольку не все директории располагаются в одном разделе файловой системы. Фактически, если вы монтируете сетевую файловую систему (например, NFS), точка монтирования будет располагаться где-то в этой иерархической структуре ниже корневой директории. В этом заключается существенное отличие от Windows, где вы привыкли к тому, что диск C обычно содержит дисковую файловую систему, а последующие файловые системы (подключенные сетевые ресурсы, дисководы CD-ROM и USB-накопители) смонтированы в виде отдельных дисков — D, E, F и так далее.
Суперблок
На самом верхнем уровне вся информация о самой файловой системе хранится в т. н. суперблоке. Хотя работа с суперблоком может не представлять особого интереса, понимание концепции использования команды может помочь вам получить полное представление о концепциях хранения данных в файловой системе.
В листинге 2 приведен пример, в котором мы получаем информацию о разделе, расположенном на устройстве /dev/sda1 (в нашем случае это раздел /boot). В конструкции мы используем команду без учета регистра для вывода информации, содержащей строку .
Листинг 2. Использование dumpe2fs для получения информации суперблока
# dumpe2fs /dev/sda1 | grep -i superblock Primary superblock at 1, Group descriptors at 2-2 Backup superblock at 8193, Group descriptors at 8194-8194 Backup superblock at 24577, Group descriptors at 24578-24578 Backup superblock at 40961, Group descriptors at 40962-40962 Backup superblock at 57345, Group descriptors at 57346-57346 Backup superblock at 73729, Group descriptors at 73730-73730