Node.js + face-recognition.js: простое и надёжное распознавание лиц с помощью глубокого обучения
Содержание:
- Результаты
- 4.9.Inductive Learning:-
- How the Face Detection Works:-
- Фейс-хакинг (активизм)
- Обещанная история про кражу личности сотрудника «Лаборатории Касперского»
- 1. Demo for API Usage
- Краткая справка
- AdaGrad
- Камера
- Детектор лиц
- Система распознавания пользователей в соц сети
- Терминология
- DNN Face Detector in OpenCV
- Заключение. А напоследок я скажу, что…
Результаты
В результате мы запилили систему, натренированную на реальных данных социальной сети, дающую хорошие результаты при ограниченных ресурсах.
Качество распознавания на датасете, построенном на реальных профилях из ОК, составило TP=97.5% при FP=0.1%. Среднее время обработки одной фотографии составляет 120 мс, а 99 перцентиль укладывается в 200 мс. Система самообучающаяся, и чем больше тегируют пользователя на фото, тем точнее становится его профиль.
Теперь после загрузки фото пользователи, найденные на них, получают уведомления и могут подтвердить себя на фотографии или удалить, если фото им не нравится.
Автоматическое распознавание привело к 2-кратному росту показов событий в ленте об отметках на фотографиях, а количество кликов на эти события выросло в 3 раза. Интерес пользователей к новой фиче очевиден, но мы планируем вырастить активность еще больше за счет улучшения UX и новых точек применения, таких как Starface.
Флешмоб StarFace
Для того чтобы познакомить пользователей соцсети с новой функциональностью, ОК объявили конкурс: пользователи загружают свои фотографии со звездами российского спорта, шоу-бизнеса и популярными блоггерами, ведущими свои аккаунты в Одноклассниках, и получают бейдж на аватарку или подписку на платные сервисы. Подробности тут: https://insideok.ru/blog/odnoklassniki-zapustili-raspoznavanie-lic-na-foto-na-osnove-neyrosetey
За первые дни акции пользователи уже загрузили более 10 тысяч фото со знаменитостями. Выкладывали селфи и фотографии со звездами, фото на фоне афиш и, конечно, “фотошоп”. Фото пользователей, получивших ВИП-статус:
4.9.Inductive Learning:-
This approach has been used to detect faces. Algorithms like Quinlan’s C4.5 or Mitchell’s FIND-S used for this purpose.
How the Face Detection Works:-
There are many techniques to detect faces, with the help of these techniques, we can identify faces with higher accuracy. These techniques have an almost same procedure for Face Detection such as OpenCV, Neural Networks, Matlab, etc. The face detection work as to detect multiple faces in an image. Here we work on OpenCV for Face Detection, and there are some steps that how face detection operates, which are as follows-
Firstly the image is imported by providing the location of the image. Then the picture is transformed from RGB to Grayscale because it is easy to detect faces in the grayscale.

Converting RGB image to Grayscale
After that, the image manipulation used, in which the resizing, cropping, blurring and sharpening of the images done if needed. The next step is image segmentation, which is used for contour detection or segments the multiple objects in a single image so that the classifier can quickly detect the objects and faces in the picture.
The next step is to use Haar-Like features algorithm, which is proposed by Voila and Jones for face detection. This algorithm used for finding the location of the human faces in a frame or image. All human faces shares some universal properties of the human face like the eyes region is darker than its neighbour pixels and nose region is brighter than eye region.
Фейс-хакинг (активизм)
Механика учит, что каждое действие создает противодействие, и быстрое развитие систем наблюдения и идентификации личности не исключение. Сегодня нейросети позволяют сопоставить случайную смазанную фотографию с улицы со снимками, загруженными в аккаунты социальных сетей и за секунды выяснить личность прохожего. В то же время художники, активисты и специалисты по машинному зрению создают средства, способные вернуть людям приватность, личное пространство, которое сокращается с такой головокружительной скоростью.
Помешать идентификации можно на разных этапах работы алгоритмов. Как правило, атакам подвергаются первые шаги процесса распознавания — обнаружение фигур и лиц на изображении. Как военный камуфляж обманывает наше зрение, скрывая объект, нарушая его геометрические пропорции и силуэт, так и машинное зрение стараются запутать цветными контрастными пятнами, которые искажают важные для него параметры: овал лица, расположение глаз, рта и т. д. По счастью, компьютерное зрение пока не столь совершенно, как наше, что оставляет большую свободу в выборе расцветок и форм такого «камуфляжа».

Розовые и фиолетовые, желтые и синие тона доминируют в линейке одежды HyperFace, первые образцы которой дизайнер Адам Харви и стартап Hyphen Labs представили в январе 2017 года. Пиксельные паттерны предоставляют машинному зрению идеальную — с ее точки зрения — картинку человеческого лица, на которую компьютер ловится, как на ложную цель. Несколько месяцев спустя московский программист Григорий Бакунов и его коллеги даже разработали специальное приложение, которое генерирует варианты макияжа, мешающего работе систем идентификации. И хотя авторы, подумав, решили не выкладывать программу в открытый доступ, тот же Адам Харви предлагает несколько готовых вариантов.

Человек в маске или со странным гримом на лице, может, и будет незаметен для компьютерных систем, но другие люди наверняка обратят на него внимание. Однако появляются способы сделать и наоборот
Ведь с точки зрения нейросети изображение не содержит образов в обычном для нас понимании; для нее картинка — это набор чисел и коэффициентов. Поэтому совершенно различные предметы могут выглядеть для нее чем-то вполне сходным. Зная эти нюансы работы ИИ, можно вести более тонкую атаку и подправлять изображение лишь слегка — так, что человеку перемены будут почти незаметны, зато машинное зрение обманется полностью. В ноябре 2017 года исследователи показали, как небольшие изменения в окраске черепахи или бейсбольного мяча заставляют систему Google InceptionV3 уверенно видеть вместо них ружье или чашку эспрессо. А Махмуд Шариф и его коллеги из Университета Карнеги — Меллон спроектировали пятнистый узор для оправы очков: на восприятие лица окружающими он почти не влияет, а вот компьютерная идентификация средствами Face++ уверенно путает его с лицом человека, «под которого» спроектирован паттерн на оправе.
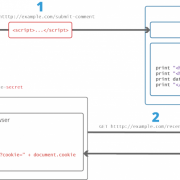
Обещанная история про кражу личности сотрудника «Лаборатории Касперского»
То есть что, вообще не публиковать фото в соцсетях? Один наш сотрудник так и делал. Паранойя, понимаете ли.
Однако FindFace его нашла. И нельзя сказать, что она ошиблась, — фотография действительно его. Просто этот снимок некий «Витёк Тизинксилов» скопировал из галереи другого пользователя в совершенно другой социальной сети. Попросту использовал чужой портрет для своего профиля.
Более того, быстрый поиск по картинке в Google показал, что эта фотография используется не только как аватар для «ВКонтакте», но и в некоей социальной сети «Фотострана». Согласитесь, не слишком приятно обнаружить комментарии от неведомого человека, прикрывающегося вашим лицом?
В общем, не стоит думать, что если у вас нет фотографий в профиле, то и беспокоиться не о чем. Ваши друзья могут выложить ваш портрет (или групповую фотографию) в свободный доступ. После этого предсказать дальнейшую судьбу изображения просто нереально.
Совет: пока «ВКонтакте» не прикрыла API, через который работает эта программа, может, имеет смысл «пробить» и свою фотографию. Мало ли где вы найдете собственных «клонов»?
Дисклеймер: мы удалили всю информацию о попавших в кадр прохожих, которые не давали своего согласия на участие в эксперименте.
1. Demo for API Usage
TL;DR: Talk is cheap, show me the code!
import{Facenet}from'facenet'constfacenet=newFacenet()constimageFile=`${__dirname}/../tests/fixtures/two-faces.jpg`constfaceList=awaitfacenet.align(imageFile)for(constfaceoffaceList){console.log('bounding box:',face.boundingBox)console.log('landmarks:',face.facialLandmark)constembedding=awaitfacenet.embedding(face)console.log('embedding:',embedding)}faceList.embedding=awaitfacenet.embedding(faceList)faceList1.embedding=awaitfacenet.embedding(faceList1)console.log('distance between the different face: ',faceList.distance(faceList1))console.log('distance between the same face: ',faceList.distance(faceList))
The output should be something like:
image file: /home/zixia/git/facenet/examples/../tests/fixtures/two-faces.jpgface file: 1-1.jpgbounding box: { p1: { x: 360, y: 95 }, p2: { x: 589, y: 324 } }landmarks: { leftEye: { x: 441, y: 181 }, rightEye: { x: 515, y: 208 }, nose: { x: 459, y: 239 }, leftMouthCorner: { x: 417, y: 262 }, rightMouthCorner: { x: 482, y: 285 } }embedding: array()face file: 1-2.jpgbounding box: { p1: { x: 142, y: 87 }, p2: { x: 395, y: 340 } }landmarks: { leftEye: { x: 230, y: 186 }, rightEye: { x: 316, y: 197 }, nose: { x: 269, y: 257 }, leftMouthCorner: { x: 223, y: 273 }, rightMouthCorner: { x: 303, y: 281 } }embedding: array()
Краткая справка
ООО «Сибнефтьинвест» зарегистрирована 13 ноября 2009 г. регистратором Межрайонная инспекция Федеральной налоговой службы №1 по Ямало-Ненецкому автономному округу. Руководитель организации: генеральный директор Якимович Александр Антонович. Юридический адрес ООО «Сибнефтьинвест» — 629804, Ямало-Ненецкий автономный округ, город Ноябрьск, поселок УТДС, 29, 1.
Основным видом деятельности является «Деятельность по созданию и использованию баз данных и информационных ресурсов», зарегистрировано 8 дополнительных видов деятельности. Организации ОБЩЕСТВО С ОГРАНИЧЕННОЙ ОТВЕТСТВЕННОСТЬЮ «СИБИРСКАЯ НЕФТЯНАЯ ИНВЕСТИЦИОННАЯ КОМПАНИЯ» присвоены ИНН 3234111641, ОГРН 3608523655109.
Организация ОБЩЕСТВО С ОГРАНИЧЕННОЙ ОТВЕТСТВЕННОСТЬЮ «СИБИРСКАЯ НЕФТЯНАЯ ИНВЕСТИЦИОННАЯ КОМПАНИЯ» ликвидирована 28 декабря 2016 г. Причина: Прекращение деятельности юридического лица в связи с исключением из ЕГРЮЛ на основании п.2 ст.21.1 Федерального закона от 08.08.2001 №129-ФЗ.
AdaGrad
AdaGrad is used to generate variable learning rates. Fixed learning rates do not work well in deep learning. In case of CNNs where each layer is used to detect a different feature (edges, patterns etc.), a fixed learning will just not work, as different layers in our network require different learning rates to work optimally. To better understand AdaGrad, let’s look at few equations.

Fig 7 : AdaGrad
If you are still reading this article even after seeing so much maths, then I guess you are pretty inquisitive. So let me help you better understand these equations by breaking them up and explaining them.
Eq (1) — It is just the regular weight update equation of SGD. Here we are using a fixed learning rate (η).
Eq (2) — It is the weight update equation of AdaGrad. In this case we are using a variable learning rate (η’t).
Eq (3) — It determines the formula for calculating the variable learning rate.
Eq (4) — It determines the formula for calculating Ɑt-1.
Ɑt-1 is just the sum of squares of gradients upto t-1. ‘t’ is the iteration number. So we just calculate the gradient at each step and add their squares together to generate Ɑt-1 and since Ɑt-1 will change with every iteration, our learning rate will also change.
Камера
Я выбрал недорогую, но при этом функциональную камеру Intel RealSense SR305, которая может снимать и цветное изображение, и глубинное изображение в разрешении 640 на 480 пикселей с частотой до 60 кадров в секунду.
Чтобы получать трехмерное изображение, камера использует маленький инфракрасный излучатель, который проецирует равномерные линии на предметы перед ней. По искривлению этих линий камера понимает, насколько далеко или близко находятся эти объекты.
Так выглядит камера, установленная на треногу
Рабочее расстояние камеры небольшое: излучатель расположен так, что объекты, которые находятся ближе двадцати сантиметров, не будут освещены и, соответственно, не будут просканированы. Слишком далеко расположенные предметы — дальше двух метров — тоже окажутся не видны, поскольку мощность лазера не позволит спроецировать на них инфракрасную сетку.
В комплекте с камерой идет провод USB и инструкция со ссылкой на официальный SDK в репозитории на GitHub.
Детектор лиц
Первую версию детектора лиц ОК запустили в 2013 году на базе стороннего решения, схожего по характеристикам с детектором на базе метода Виолы — Джонса. За 5 лет это решение устарело, современные решения, основанные на MTCNN, показывают точность в два раза выше. Поэтому мы решили следовать трендам и построили свой каскад из сверточных нейронных сетей (MTCNN).
Для работы старого детектора мы использовали более 100 “стареньких” серверов с CPU. Практически все современные алгоритмы нахождения лиц на фото основаны на свёрточных нейронных сетях, которые наиболее эффективно работают на GPU. Закупить большое число видеокарт мы не имели возможности по объективным причинам: дорого все скупили майнеры. Решено было запускаться c детектором на CPU (ну не выкидывать же сервера).
Для детектирования лиц на заливаемых фотографиях мы используем кластер из 30 машин (остальные пропили сдали в утиль). Детектирование при построении пользовательских векторов (итерации по аккаунтам) мы делаем на 1000 виртуальных ядрах с низким приоритетом в нашем облаке. Облачное решение детально описано в докладе Олега Анастасьева: One-cloud — ОС уровня дата-центра в Одноклассниках.
При анализе времени работы детектора мы столкнулись с таким худшим случаем: сеть верхнего уровня пропускает слишком много кандидатов на следующий уровень каскада, и детектор начинает работать долго. Например, время поиска достигает 1.5 секунд на таких фотографиях:
Рисунок 4. Примеры большого количества кандидатов после первой сети в каскаде
Оптимизируя этот случай, мы высказали предположение, что на фотографии обычно немного лиц. Поэтому, после первого этапа каскада мы оставляем не больше 200 кандидатов, опираясь на уверенность соответствующей нейросети в том, что это лицо.
Такая оптимизация уменьшила время худшего случая до 350 мс, то есть в 4 раза.
Применив пару оптимизаций (например, заменив Non-Maximum Suppression после первой ступени каскада на фильтрацию на основе Blob detection), разогнали детектор ещё в 1.4 раза без потери качества.
Впрочем прогресс на месте тоже не стоял, и сейчас искать лица на фото принято более элегантными методами — см. FaceBoxes. Не исключаем, что в ближайшее время и мы переедем на нечто подобное.
Система распознавания пользователей в соц сети
Распознавание лиц на загруженном фото
Пользователь загружает фото с любого клиента (с браузера или мобильных приложений iOS, Android), оно попадает на детектор, задача которого найти лица и выровнять их.
После детектора нарезанные и предобработанные лица попадают на нейросетевой распознаватель, который строит характеристический профиль лица пользователя. После этого происходит поиск наиболее похожего профиля в базе. Если степень похожести профилей больше граничного значения, то пользователь автоматически детектируется, и мы отсылаем ему уведомление, что он есть на фото.
Рисунок 1. Распознавание пользователей на фото
Перед тем, как запустить автоматические распознавание, нужно создать профиль каждого пользователя и заполнить базу.
Построение пользовательских профилей
Для работы алгоритмов распознавания лиц, достаточно всего одной фотографии, например аватарки. Но будет ли эта аватарка содержать фото профиля? Пользователи ставят на аватарки фотографии звёзд, а профили изобилуют мемасиками или содержат только групповые фотографии.
Рисунок 2. Трудный профиль
Рассмотрим профиль пользователя, состоящий только из групповых фотографий.
Определить владельца аккаунта (рис. 2) можно если учитывать его пол и возраст, а также друзей, профили которых были построены ранее.
Рисунок 3. Построение пользовательских профилей
Мы строили профиль пользователя следующим образом (Рис. 3):
1) Выбирали наиболее качественные фотографии пользователя
Если фотографий было слишком много, мы использовали не более ста лучших.
Качество фотографий определяли на основе:
- наличия отметок пользователей на фото (фотопинов) ручным способом;
- метаинформации фотографии (фото загружено с мобильного телефона, снято на фронтальную камеру, в отпуске, …);
- фото было на аватарке
2) Искали на этих фотографиях лица
3) Вычисляли характеристический вектор лица
4) Производили кластеризацию векторов
Задача этой кластеризации – определить, какой именно набор векторов принадлежит владельцу аккаунта. Основная проблема – это наличие друзей и родственников на фотографиях. Для кластеризации мы используем алгоритм DBScan.
5) Определяли лидирующий кластер
Для каждого кластера мы считали вес на основании:
- размера кластера;
- качества фотографий, по которым построены эмбеддинги в кластере;
- наличия фотопинов, привязанных к лицам из кластера;
- соответствия пола и возраста лиц в кластере с информаций из профиля;
- близость центроида кластера к профилям друзей, вычисленным ранее.
Коэффициенты параметров, участвующих в вычислении веса кластера обучим линейной регрессией. Честный пол и возраст профиля – отдельная сложная задача, об этом расскажем далее.
Чтобы кластер считался лидером, нужно чтобы его вес был больше ближайшего конкурента на константу, рассчитанную на обучающей выборке. Если лидер не найден, мы еще раз переходим к пункту 2, но используем большее число фотографий. Для некоторых пользователей мы сохраняли два кластера. Такое бывает для совместных профилей — некоторые семьи имеют общий профиль.
6) Получали эмбеддинги пользователя по его кластерам
Эмбеддинг пользователя – это центроид отобранного для него (лидирующего) кластера.
Строить центроиды можно множеством разных способов. После многочисленных экспериментов мы вернулись к самому простому из них: усреднение входящих в кластер векторов.
Как и кластеров, эмбеддингов у пользователя может быть несколько.
За время итерации мы обработали восемь миллиардов фото, проитерировали 330 млн профилей и построили эмбеддинги для трехсот миллионов аккаунтов. В среднем, для построения одного профиля мы обрабатывали 26 фотографий. При этом для построения вектора достаточно даже одной фотографии, но чем больше фото, тем больше наша уверенность, что построенный профиль принадлежит именно владельцу аккаунта.
Процесс построения всех профилей на портале мы производили несколько раз, так как наличие информации о друзьях повышает качество выбора кластера.
Объем данных необходимый для хранения векторов ~300 GB.
Терминология
Область исследования face anti-spoofing довольно новая и пока еще не может похвастаться даже сложившейся терминологией.
Условимся называть попытку обмана системы идентификации путем предъявления ей поддельного биометрического параметра (в данном случае — лица) spoofing attack.
Соответственно, комплекс защитных мер, чтобы противостоять такому обману, будем называть anti-spoofing. Он может быть реализован в виде самых разных технологий и алгоритмов, встраиваемых в конвейер системы идентификации.
В предлагается несколько расширенный набор терминологии, с такими терминами, как presentation attack — попытки заставить систему неверно идентифицировать пользователя или дать ему возможность избежать идентификации, с помощью демонстрации картинки, записанного видео и так далее. Normal (Bona Fide) – соответствует обычному алгоритму работы системы, то есть всему, что НЕ является атакой. Presentation attack instrument означает средство совершения атаки, например, искусственно изготовленную часть тела. И, наконец, Presentation attack detection — автоматизированные средства обнаружения таких атак. Впрочем, сами стандарты все еще находятся в разработке, поэтому говорить о каких-либо устоявшихся понятиях нельзя. Терминология на русском языке отсутствует почти полностью.
Для определения качества работы системы часто пользуются метрикой HTER (Half-Total Error Rate – половина полной ошибки), которую вычисляют в виде суммы коэффициентов ошибочно разрешенных идентификаций (FAR – False Acceptance Rate) и ошибочно запрещенных идентификаций (FRR – False Rejection Rate), деленной пополам.
HTER=(FAR+FRR)/2
Стоит сказать, что в системах биометрии обычно самое большое внимание уделяют FAR, с целью сделать всё возможное, чтобы не допустить злоумышленника в систему. И добиваются в этом неплохих успехов (помните одну миллионную из начала статьи?) Обратной стороной оказывается неизбежное возрастание FRR – количества обычных пользователей, ошибочно классифицированных как злоумышленников
Если для государственных, оборонных и прочих подобных систем этим можно пожертвовать, то мобильные технологии, работающие с их огромными масштабами, разнообразием абонентских устройств и, вообще, user-perspective ориентированные, очень чувствительны к любым факторам, которые могут заставить пользователей отказаться от услуг. Если вы хотите уменьшить количество разбитых об стену телефонов после десятого подряд отказа в идентификации, стоит обратить внимание на FRR!
DNN Face Detector in OpenCV
This model was included in OpenCV from version 3.3. It is based on Single-Shot-Multibox detector and uses ResNet-10 Architecture as backbone. The model was trained using images available from the web, but the source is not disclosed. OpenCV provides 2 models for this face detector.
- Floating point 16 version of the original caffe implementation ( 5.4 MB )
- 8 bit quantized version using Tensorflow ( 2.7 MB )
We have included both the models along with the code.
Code
Python
DNN = "TF"
if DNN == "CAFFE":
modelFile = "res10_300x300_ssd_iter_140000_fp16.caffemodel"
configFile = "deploy.prototxt"
net = cv2.dnn.readNetFromCaffe(configFile, modelFile)
else:
modelFile = "opencv_face_detector_uint8.pb"
configFile = "opencv_face_detector.pbtxt"
net = cv2.dnn.readNetFromTensorflow(modelFile, configFile)
C++
const std::string caffeConfigFile = "./deploy.prototxt"; const std::string caffeWeightFile = "./res10_300x300_ssd_iter_140000_fp16.caffemodel"; const std::string tensorflowConfigFile = "./opencv_face_detector.pbtxt"; const std::string tensorflowWeightFile = "./opencv_face_detector_uint8.pb"; #ifdef CAFFE Net net = cv::dnn::readNetFromCaffe(caffeConfigFile, caffeWeightFile); #else Net net = cv::dnn::readNetFromTensorflow(tensorflowWeightFile, tensorflowConfigFile); #endif
We load the required model using the above code. If we want to use floating point model of Caffe, we use the caffemodel and prototxt files. Otherwise, we use the quantized tensorflow model. Also note the difference in the way we read the networks for Caffe and Tensorflow.
Python
blob = cv2.dnn.blobFromImage(frameOpencvDnn, 1.0, (300, 300), , False, False)
net.setInput(blob)
detections = net.forward()
bboxes = []
for i in range(detections.shape):
confidence = detections
if confidence > conf_threshold:
x1 = int(detections * frameWidth)
y1 = int(detections * frameHeight)
x2 = int(detections * frameWidth)
y2 = int(detections * frameHeight)
C++
#ifdef CAFFE
cv::Mat inputBlob = cv::dnn::blobFromImage(frameOpenCVDNN, inScaleFactor, cv::Size(inWidth, inHeight), meanVal, false, false);
#else
cv::Mat inputBlob = cv::dnn::blobFromImage(frameOpenCVDNN, inScaleFactor, cv::Size(inWidth, inHeight), meanVal, true, false);
#endif
net.setInput(inputBlob, "data");
cv::Mat detection = net.forward("detection_out");
cv::Mat detectionMat(detection.size, detection.size, CV_32F, detection.ptr<float>());
for(int i = 0; i < detectionMat.rows; i++)
{
float confidence = detectionMat.at<float>(i, 2);
if(confidence > confidenceThreshold)
{
int x1 = static_cast<int>(detectionMat.at<float>(i, 3) * frameWidth);
int y1 = static_cast<int>(detectionMat.at<float>(i, 4) * frameHeight);
int x2 = static_cast<int>(detectionMat.at<float>(i, 5) * frameWidth);
int y2 = static_cast<int>(detectionMat.at<float>(i, 6) * frameHeight);
cv::rectangle(frameOpenCVDNN, cv::Point(x1, y1), cv::Point(x2, y2), cv::Scalar(0, 255, 0),2, 4);
}
}
In the above code, the image is converted to a blob and passed through the network using the forward() function. The output detections is a 4-D matrix, where
- The 3rd dimension iterates over the detected faces. (i is the iterator over the number of faces)
- The fourth dimension contains information about the bounding box and score for each face. For example, detections gives the confidence score for the first face, and detections give the bounding box.
The output coordinates of the bounding box are normalized between . Thus the coordinates should be multiplied by the height and width of the original image to get the correct bounding box on the image.
Pros
The method has the following merits :
- Most accurate out of the four methods
- Runs at real-time on CPU
- Works for different face orientations – up, down, left, right, side-face etc.
- Works even under substantial occlusion
- Detects faces across various scales ( detects big as well as tiny faces )
The DNN based detector overcomes all the drawbacks of Haar cascade based detector, without compromising on any benefit provided by Haar. We could not see any major drawback for this method except that it is slower than the Dlib HoG based Face Detector discussed next.
It would be safe to say that it is time to bid farewell to Haar-based face detector and DNN based Face Detector should be the preferred choice in OpenCV.
Заключение. А напоследок я скажу, что…
Локальные бинарные паттерны, отслеживание моргания, дыхания, движений и прочие сконструированные вручную признаки совершенно не потеряли значимости. Это вызвано, прежде все тем, что глубокое обучение в области face anti-spoofing все еще весьма наивно.
Совершенно очевидно, что в «том самом» решении будет выполняться слияние нескольких методов. Анализ отражения, рассеяния, карты глубины должны использоваться вместе. Скорее всего, поможет добавление дополнительного канала данных, например, запись голоса и какие-то системные подходы, которые позволят собрать несколько технологий в единую систему
Практически все технологии, используемые для распознавания лица, находят применение в face anti-spoofing (кэп!) Все, что было разработано для распознавания лиц, в том или ином виде нашло применение и для анализа атак
Существующие датасеты достигли насыщения. Из десяти основных наборов данных в пяти удалось достичь нулевой ошибки. Это уже говорит, например, о работоспособности методов на основе карт глубины, но не позволяет улучшить обобщающую способность. Нужны новые данные и новые эксперименты на них
Есть явный дисбаланс между степенью развития распознавания лиц и face anti-spoofing. Технологии распознавания существенно опережают системы защиты. Более того, именно отсутствие надежных систем защиты тормозит практическое применение систем распознавания лиц
Так получилось, что основное внимание уделялось именно распознаванию лиц, а системы обнаружения атак остались несколько в стороне
Есть сильная потребность системного подхода в области face anti-spoofing. Прошедший конкурс университета Оулу показал, что при использовании нерепрезентативного набора данных вполне возможно победить простой грамотной настройкой устоявшихся решений, без разработки новых
Возможно, новое соревнование сможет переломить ситуацию
С возрастанием интереса к тематике и внедрением технологий распознавания по лицу крупными игроками появились «окна возможностей» для новых амбициозных команд, поскольку есть серьезная потребность в новом решении на уровне архитектуры