Опыт эксплуатации ceph
Содержание:
Настройка кластера Ceph
Выполним начальную настройку сервера монитора Ceph:
ceph-deploy mon create-initial
Подготовка дисков
Диски, доступные на сервере можно посмотреть следующей командой:
ceph-deploy disk list server1
Готовим диски для использования их системой Ceph:
ceph-deploy osd prepare server1:sdb server1:sdc server2:sdb server2:sdc server3:sdb server3:sdc
* в данном примере на каждом из серверов есть по два диска — sdb и sdc. Их мы и задействеум в качестве Ceph-хранилища.
И активируем их:
ceph-deploy osd activate server1:sdb1 server1:sdc1 server2:sdb1 server2:sdc1 server3:sdb1 server3:sdc1
* обратите внимание, что при активации мы уже добавляем 1 к дискам, так как в процессе подготовки система создает два раздела — 1 для данных, 2 для журнала
Storage Classes
StorageClass позволяет описать классы хранения, которые предлагают хранилища. Например, они могут отличаться по скорости, по политикам бэкапа, либо какими-то еще произвольными политиками. Каждый StorageClass содержит поля provisioner, parameters и reclaimPolicy, которые используются, чтобы динамически создавать PersistentVolume.
Можно создать дефолтный StorageClass для тех PVC, которые его вообще не указывают. Так же storage class хранит параметры подключения к реальному хранилищу. PVC используют эти параметры для подключения хранилища к подам.
Важный нюанс. PVC зависим от namespace. Если у вас SC будет с секретом, то этот секрет должен быть в том же namespace, что и PVC, с которого будет запрос на подключение.
Настройка кластера
Построение кластерной системы выполняется в 2 этапа — сначала мы создаем кластер на любой из нод, затем присоединяем к данному кластеру остальные узлы.
Создание кластера
Переходим в панель управления Proxmox на любой их нод кластера. Устанавливаем курсов на Датацентр — кликаем по Кластер — Создать кластер:
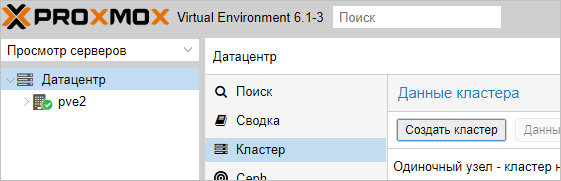
Для создания кластера нам нужно задать его имя и, желательно, выбрать IP-адрес интерфейса, на котором узел кластера будет работать:
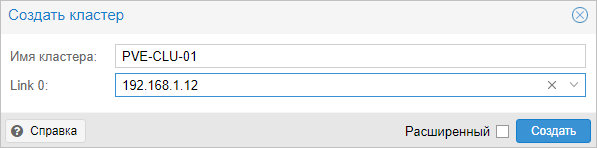
… кликаем Создать — процесс не должен занять много времени. В итоге, мы должны увидеть «TASK OK»:
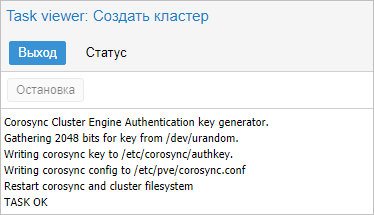
Присоединение ноды к кластеру
На первой ноде, где создали кластер, в том же окне станет активна кнопка Данные присоединения — кликаем по ней:
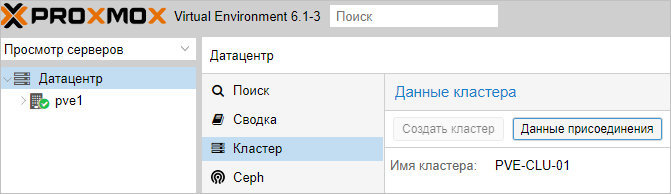
В открывшемся окне копируем данные присоединения:
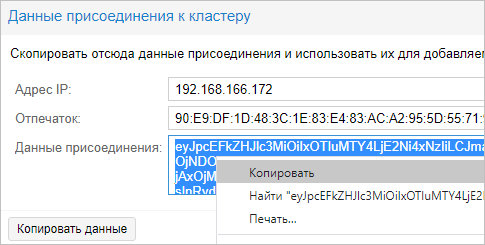
Теперь переходим в панель управления нодой, которую хотим присоединить к кластеру. Переходим в Датацентр — Кластер — кликаем по Присоединить к кластеру:

В поле «Данные» вставляем данные присоединения, которые мы скопировали с первой ноды — поля «Адрес сервера» и «Отпечаток заполняться автоматически». Заполняем пароль пользователя root первой ноды и кликаем Присоединение:
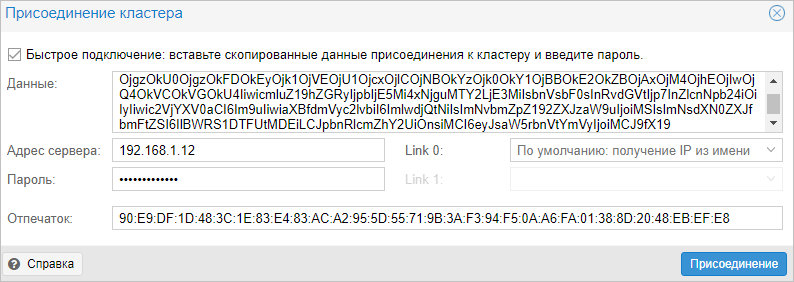
Присоединение также не должно занять много времени. Ждем несколько минут для завершения репликации всех настроек. Кластер готов к работе — при подключении к любой из нод мы будем подключаться к кластеру:
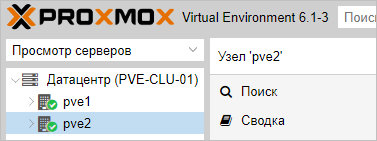
Готово. Данный кластер можно использовать для централизованного управления хостами Proxmox.
Посмотреть статус работы кластера можно командой в SSH:
pvecm status
Настройка сети
Теперь важный момент, настало время поговорить о сети для ceph. Ceph для работы использует две сети public network и cluster network
Как видно из схемы public network это уровень пользователя и приложений, а cluster network это сеть по которой происходит репликация данных.
Очень желательно отделять эти две сети друг от друга. Также скорость сети cluster network желательна не меньше 10 Gb.
Конечно, можно все держать в одной сети. Но это черевато тем, что как только возрастет объем репликаций между OSD, например, при падении или добавлении новых OSD (дисков), то нагрузка на сеть ОЧЕНЬ сильно возрастет. Так что скорость и стабильность вашей инфраструктуры, будет сильно зависеть от сети используемой ceph.
На моем кластере виртуализации к сожалению нет отдельной сети, и я буду использовать общий сегмент сети.
Настройка сети для кластера производится через конфиг файл, который мы сгенерировали предыдущей командой.
Как мы видим цеф деплой не создал нам настройки сети по умолчанию, по этому я добавлю в конфиг в раздел global параметр public network = {public-network/netmask}. Моя сеть 10.73.0.0/16 по этому после добавления мой конфиг будет выглядеть следующим образом
Если Вы хотите отделить сеть cluster от public, то добавьте параметр cluster network = {cluster-network/netmask}
Более подробно про сети можно почитать в документации
Data Lake и корпоративное хранилище данных: как работать с Big Data
В 2010-х годах, с наступлением эпохи Big Data, фокус внимания от традиционных DWH сместился озерам данных (Data Lake). Однако, считать озеро данных новым поколением КХД не совсем корректно по следующим причинам:
разное целевое назначение – DWH используется менеджерами, аналитиками и другими конечными бизнес-пользователями, тогда как озеро данных – в основном Data Scientist’ами. Напомним, в Data Lake хранится неструктурированная, т.н. сырая информация: видеозаписи с беспилотников и камер наружного наблюдения, транспортная телеметрия, графические изображения, логи пользовательского поведения, метрики сайтов и информационных систем, а также прочие данные с разными форматами хранения (схемами представления). Они пока непригодны для ежедневной аналитики в BI-системах, но могут использоваться Data Scientist’ами для быстрой отработки новых бизнес-гипотез с помощью алгоритмов машинного обучения ;
разные подходы к проектированию. Дизайн DWH основан на реляционной логике работы с данными – третья нормальная форма для нормализованных хранилищ, схемы звезды или снежинки для хранилищ с измерениями
При проектировании озера данных архитектор Big Data и Data Engineer большее внимание уделяют ETL-процессам с учетом многообразия источников и приемников разноформатной информации. А вопрос ее непосредственного хранения решается достаточно просто – требуется лишь масштабируемая, отказоустойчивая и относительно дешевая файловая система, например, HDFS или Amazon S3 ;
наконец, цена – обычно Data Lake строится на базе бюджетных серверов с Apache Hadoop, без дорогостоящих лицензий и мощного оборудования, в отличие от больших затрат на проектирование и покупку специализированных платформ класса Data Warehouse, таких как SAP, Oracle, Teradata и пр.
Таким образом, озеро данных существенно отличается от КХД. Тем не менее, архитектурный подход LSA может использоваться и при построении Data Lake. Например, именно такая слоенная структура была принята за основу озера данных в Тинькоф-банке :
- на уровне RAW хранятся сырые данные различных форматов (tsv, csv, xml, syslog, json и т.д.);
- на операционном уровне (ODD, Operational Data Definition) сырые данные преобразуются в приближенный к реляционному формат;
- на уровне детализации (DDS, Detail Data Store) собирается консолидированная модель детальных данных;
- наконец, уровень MART выполняет роль прикладных витрин данных для бизнес-пользователей и моделей машинного обучения.
В данном примере для структурированных запросов к большим данным используется Apache Hive – популярное средство класса SQL-on-Hadoop. Само файловое хранилище организовано в кластере Hadoop на основе коммерческого дистрибутива от Cloudera (CDH). Традиционное DWH банка реализовано на массивно-параллельной СУБД Greenplum . От себя добавим, что альтернативой Apache Hive могла выступить Cloudera Impala, которая также, как Greenplum, Arenadata DB и Teradata, основана на массивно-параллельной архитектуре. Впрочем, выбор Hive обоснован, если требовалась высокая отказоустойчивость и большая пропускная способность. Подробнее о сходствах и различиях Apache Hive и Cloudera Impala мы рассказывали здесь. Возвращаясь к кейсу Тинькофф-банка, отметим, что BI-инструменты считывают данные из озера и классического DWH, обогащая типичные OLAP-отчеты информацией из хранилища Big Data. Это используется для анализа интересов, прогнозирования поведения, а также выявления текущих и будущих потребностей, которые возникают у посетителей сайта банка .
LSA-архитектура корпоративного Data Lake в Тинькоф-банке
В следующей статье мы продолжим разговор про архитектурные особенности современных DWH с учетом потребности работы с Big Data и рассмотрим еще несколько примеров таких гибридных подходов. А технические подробности реализации КХД и другие актуальные вопросы управления бизнес-данными вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Модели Данных
- Hadoop для инженеров данных
- Cloudera Impala Data Analytics
- Hadoop SQL администратор Hive
Смотреть расписание
Записаться на курс
Источники
- https://ru.wikipedia.org/wiki/Хранилище_данных
- https://habr.com/ru/post/269727/
- https://habr.com/ru/post/281553/
- https://habr.com/ru/post/495670/
- https://chernobrovov.ru/articles/kuda-slit-big-data-ili-zachem-vam-ozero-dannyh.html
- https://habr.com/ru/company/tinkoff/blog/259173/
Ceph RBD
Теперь давайте создадим rbd диск в кластере ceph и подключим его к целевому серверу. Для этого идем в консоль на любую ноду кластера. Создаем pool для rbd дисков.
# ceph osd pool create rbdpool 32
| rbdpool | название пула, может быть любым |
| 32 | 32 — кол-во pg (placement groups) в пуле |
Проверим список пулов кластера.
# rados lspools
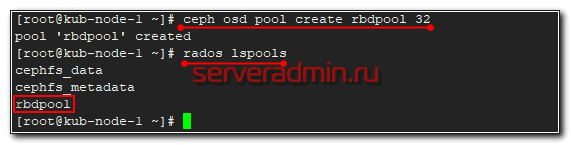
Создаем в этом пуле rbd диск на 10G.
# rbd create disk1 --size 10G --pool rbdpool
Добавим пользователя с разрешениями на использование этого пула. Делается точно так же, как в случае с cephfs, что мы проделали ранее.
# ceph auth get-or-create client.rbduser mon 'allow r, allow command "osd blacklist"' osd 'allow rwx pool=rbdpool'
В консоли увидите ключ пользователя rbduser для подключения пула rbdpool.
Перемещаемся на целевой сервер, куда мы будем подключать rbd диск кластера ceph. Для подключения blockdevice нам необходимо поставить программное обеспечение из репозитория ceph-luminous на сервер, где будет использоваться rbd.
# yum install centos-release-ceph-luminous # yum install ceph-common
Так же запишем на целевой сервер ключ клиента, который имеет доступ к пулу с дисками. Создаем файл /etc/ceph/ceph.client.rbduser.keyring следующего содержания.
key = AQCW5DFeXNy2JRAAWnCU/DpZhuNHmNcI5l1sEQ==
Там же создаем конфигурационный файл /etc/ceph/ceph.conf, где нам необходимо указать ip адреса мониторов ceph.
mon host = 10.1.4.32,10.1.4.33,10.1.4.39
В конце конфигурационного файла должен быть переход на новую строку. Если его не сделать, диск не смаппится, будет ошибка.
Пробуем подключить блочное устройство.
# rbd map disk1 --pool rbdpool --id rbduser rbd: sysfs write failed RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable rbdpool/disk1 object-map fast-diff deep-flatten". In some cases useful info is found in syslog - try "dmesg | tail". rbd: map failed: (6) No such device or address
Скорее всего получите такую же или подобную ошибку. Суть ее в том, что текущее ядро поддерживает не все возможности образа RBD, поэтому их нужно отключить. Как это сделать показано в подсказке. Для отключения нужен администраторский доступ в кластер. Так что идем на любую ноду пула и выполняем там предложенную команду.
# rbd feature disable rbdpool/disk1 object-map fast-diff deep-flatten
Не должно быть никаких ошибок, как и любого вывода после работы команды. Возвращаемся на целевой сервер и пробуем подключить rbd диск еще раз.
# rbd map disk1 --pool rbdpool --id rbduser /dev/rbd0
Все в порядке. В системе появился новый диск — /dev/rbd0. Создадим на нем файловую систему и подмонтируем к серверу.
# mkfs.xfs -f /dev/rbd0 # mkdir /mnt/rbd # mount /dev/rbd0 /mnt/rbd # df -h | grep rbd
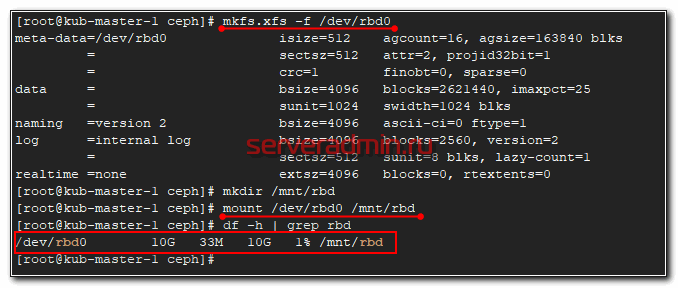
Можно попробовать туда что-то записать и посмотреть на скорость.
# dd if=/dev/zero of=/mnt/rbd/testfile bs=10240 count=100000 100000+0 records in 100000+0 records out 1024000000 bytes (1.0 GB) copied, 6.88704 s, 149 MB/s
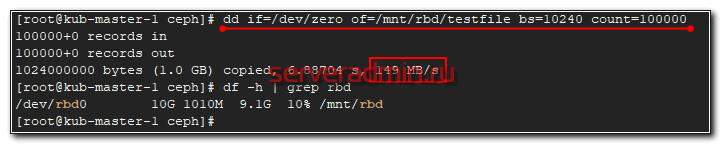
Не знаю, что я измерил 🙂 На самом деле это скорость одиночного sata диска, на котором установлена система сервера, которому я подключил диск. Так понимаю, запись вся ушла в буфер, а потом началась синхронизация по кластеру.
Настроим теперь автоматическое подключение rbd диска при старте системы. Для начала надо настроить mapping диска. Для этого создаем конфиг файл /etc/ceph/rbdmap следующего содержания.
rbdpool/disk1 id=rbduser,keyring=/etc/ceph/ceph.client.rbduser.keyring
Запускаем скрипт rbdmap и добавляем в автозапуск.
# systemctl enable --now rbdmap Created symlink from /etc/systemd/system/multi-user.target.wants/rbdmap.service to /usr/lib/systemd/system/rbdmap.service.
Проверяем статус.
# systemctl status rbdmap
Осталось добавить монтирование блочного устройства rbd в /etc/fstab.
/dev/rbd/rbdpool/disk1 /mnt/rbd xfs noauto,noatime 0 0
И не забудьте в конце сделать переход на новую строку. После этого перезагрузите сервер и проверьте, что rbd диск кластера ceph нормально подключается.
Добавление OSD
В данный момент мы имеем работающий кластер, но в нем еще нет дисков (osd в терминологии ceph) для хранения информации.
OSD можно добавить следующей командой (общий вид)
В моем тестовом стенду под osd выделен disk /dev/sdb, по этому в моем случае команды будут следующие
Проверим что все OSD работают
Вывод
Так же можете попробовать полезные команды для OSD
и
Если все ОК, то мы имеем работоспособный кластер ceph. В следующей части я расскажу как использовать ceph с kubernetes
Подключение ceph к kubernetes
К сожалению, я не смогу в рамках данной статьи подробно рассказать про работу томов Kubernetes, поэтому попробую уложиться в один абзац.
Для работы с томами данных данных Kubernetes использует storage classes, для каждого storage class есть свой provisioner, можно рассматривать его как некий «драйвер» для работы с различными томами хранения данных. Полный список который поддерживает kubernetes можно посмотреть в официальной документации.
В самом Kubernetes так же есть поддержка работы с rbd, но в официальном образе kube-controller-manager нет установленного клиента rbd, поэтому нужно использовать другой образ.
Также следует учесть, что тома (pvc) созданные как rbd могут быть только ReadWriteOnce (RWO) и, а это значит что созданный том Вы сможете примонтировать ТОЛЬКО к одному поду.
Для того что бы наш кластер смог работать с томами на ceph, нам нужно:
в кластере Сeph:
- создать pool данных в кластере ceph
- создать клиента и ключ доступа до пула данных
- получить сeph admin secret
Для того что бы наш кластер смог работать с томами на ceph, нам нужно:
в кластере Сeph:
- создать pool данных в кластере ceph
- создать клиента и ключ доступа до пула данных
- получить сeph admin secret
в кластере Kubernetes:
- создать сeph admin secret и ключ клиента ceph
- установить ceph rbd provisioner или изменить образ kube-controller-manager на образ который поддерживает rbd
- создать secret c ключом клиента ceph
- создать storage class
- установить ceph-common на воркер нодах kubernetes
Troubleshooting
Although the installation process of RADOSGW is very straight forward, issues can occur due to a few common mistake and misconfiguration.
DNS Name
Misconfigured DNS name in the configuration file. The rgw_dns_name in the Ceph configuration file is how RADOSGW will respond any request to. So if the value entered as FQDN but you are trying to access it with IP address, the S3 interface will be inaccessible.
Wildcard Subdomain With Cloudflare
It is a common practice to allow users to connect over the Internet to S3 object storage using FQDN. Usually, the format is bucketname.s3.domain.com or something similar. If the configured RADOSGW is placed in a multi-tenant environment where different users all from different entities need to access their own S3 buckets, then using bucketname.s3.domain.com is a better way to go.
In such a scenario, each bucket name would require an A record in the nameserver associated with the domain name. Depending on the number of users, manual creation of these DNS records can become a tedious task. So a DNS record such as *.s3.domain.com will work best for all bucket users. The free plan of Cloudflare does not offer the creation of wildcard record for a subdomain. Create the records manually or use Cloudflare Enterprise Plan.
SSL Certificate File
SInce RADOSGW require a single certificate file, an error can occur when combining all the certificate files into one. Ensure to have the certificate content as following order:
- Main certificate file = domain_com.crt
- CA Bundle file = ca_bundle.crt
- Private Key = domain_com.key
Refer to section Configuring SSL for a full command to combine certificate files.
Prerequisite
It is important to ensure the Ceph cluster is healthy and no data rebalancing is in progress. A healthy Ceph cluster should appear as following after typing # ceph -s command:
cluster:
id: 3921019cb-adfs3-4347-owier90-sl23498fjds health: HEALTH_OK
services:
mon: 3 daemons, quorum cph-01,cph-02,cph-03,cph-042 mgr: cph-01(active), standbys: cph-02,cph-03,cph-04 mds: cephfs-01-1/1/1 up {0=cph-01=up:active}, 2 up:standby osd: 40 osds: 40 up, 40 in rgw: 1 daemon active
data:
pools: 10 pools, 2384 pgs objects: 1.63M objects, 6.17TiB usage: 18.5TiB used, 54.3TiB / 72.8TiB avail pgs: 2383 active+clean
io: client: 24.6MiB/s rd, 2.23MiB/s wr, 271op/s rd, 126op/s wr
Also, ensure that all member nodes in the Ceph cluster are fully updated.






