Односвязный список на c++
Содержание:
Appending the Numpy Array

Here there are two function np.arange(24), for generating a range of the array from 0 to 24. The reshape(2,3,4) will create 3 -D array with 3 rows and 4 columns.
Lets we want to add the list to end of the above-defined array a. To append one array you use numpy append() method. The syntax is given below.
append(array1, array2, axis = None or )
Where type is
array1: Numpy Array, original array
array2: Numpy Array, To Append the original array.
axis: It is optional default is 0. Axis along which values are appended.

Here axis is not passed as an argument so, elements will append with the original array a, at the end.
Виды связных списков
Линейный связный список
Односвязный список (однонаправленный связный список)
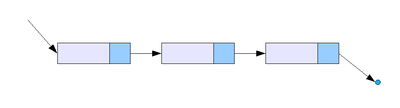
Разновидность связного списка — односвязный список, содержащий 3 элемента
Линейный однонаправленный список — это структура данных, состоящая из элементов одного типа, связанных между собой последовательно посредством указателей. Каждый элемент списка имеет указатель на следующий элемент. Последний элемент списка указывает на NULL. Элемент, на который нет указателя, является первым (головным) элементом списка. Здесь ссылка в каждом узле указывает на следующий узел в списке. В односвязном списке можно передвигаться только в сторону конца списка. Узнать адрес предыдущего элемента, опираясь на содержимое текущего узла, невозможно.
В информатике линейный список обычно определяется как абстрактный тип данных (АТД), формализующий понятие упорядоченной коллекции данных. На практике линейные списки обычно реализуются при помощи массивов и связных списков. Иногда термин «список» неформально используется также как синоним понятия «связный список». К примеру, АТД нетипизированного изменяемого списка может быть определён как набор из конструктора и основных операций:
- Операция, проверяющая список на пустоту.
- Три операции добавления объекта в список (в начало, конец или внутрь после любого (n-го) элемента списка);
- Операция, вычисляющая первый (головной) элемент списка;
- Операция доступа к списку, состоящему из всех элементов исходного списка, кроме первого.
Характеристики
- Длина списка. Количество элементов в списке.
- Списки могут быть типизированными или нетипизированными. Если список типизирован, то тип его элементов задан, и все его элементы должны иметь типы, совместимые с заданным типом элементов списка. Чаще списки типизированы.
- Список может быть сортированным или несортированным.
- В зависимости от реализации может быть возможен произвольный доступ к элементам списка.
Односвязный список в языках программирования
struct list
{
int field; // поле данных
struct list *next; // указатель на следующий элемент
};
применение односвязного списка:
1 struct list* l1 = (struct list*)malloc(sizeof(struct list)); 2 l1->field = 1; 3 l1->next = (struct list*)malloc(sizeof(struct list)); 4 l1->next->field = 2; 5 l1->next->next = (struct list*)malloc(sizeof(struct list)); 6 /* и т.д. */
Двусвязный список (двунаправленный связный список)
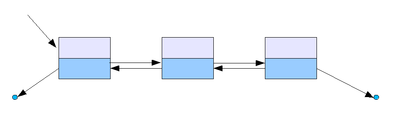
Здесь ссылки в каждом узле указывают на предыдущий и на последующий узел в списке. Как и односвязный список, двусвязный допускает только последовательный доступ к элементам, но при этом дает возможность перемещения в обе стороны. В этом списке проще производить удаление и перестановку элементов, так как легко доступны адреса тех элементов списка, указатели которых направлены на изменяемый элемент.
XOR-связный список
Основная статья: XOR-связный список
Используется редко.
Кольцевой связный список
Разновидностью связных списков является кольцевой (циклический, замкнутый) список. Он тоже может быть односвязным или двусвязным. Последний элемент кольцевого списка содержит указатель на первый, а первый (в случае двусвязного списка) — на последний.
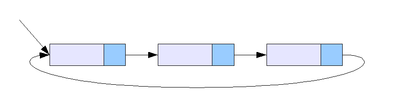
Как правило, такая структура реализуется на базе линейного списка. С каждым кольцевым списком дополнительно хранится указатель на первый элемент. В этом списке ссылки на NULL не встречается.
Также существуют циклические списки с выделенным головным элементом, облегчающие полный проход через список.
Основная статья: Развёрнутый связный список
Сортировка односвязного списка
Сортировать список будем слиянием. Этот метод очень похож на сортировку слиянием для массива. Для его реализации нам
понадобятся две функции: одна буде делить список пополам, а другая будет объединять два упорядоченных односвязных списка, не создавая при этом новых узлов.
Наша реализация не будет оптимальной, однако, некоторые решения, которые мы применим, могут быть использованы и в других алгоритмах.
Вспомогательная функция – слияние двух отсортированных списков. Функция не должна создавать новых узлов, так что будем использовать только имеющиеся. Для начала проверим, если хоть один из списков пуст, то вернём другой.
Node tmp;
*c = NULL;
if (a == NULL) {
*c = b;
return;
}
if (b == NULL) {
*c = a;
return;
}
После этого нужно, чтобы наша локальная переменная стала хранить адрес большего из узлов двух списков, от него и будем танцевать дальше
if (a->value < b->value) {
*c = a;
a = a->next;
} else {
*c = b;
b = b->next;
}
Теперь сохраним указатель c, так как в дальнейшем он будет использоваться для прохода по списку
tmp.next = *c;
После этого проходим по спискам, сравниваем значения и перекидываем их
while (a && b) {
if (a->value < b->value) {
(*c)->next = a;
a = a->next;
} else {
(*c)->next = b;
b = b->next;
}
(*c) = (*c)->next;
}
В конце, может остаться один список, который пройден не до конца. Добавим его узлы
if (a) {
while (a) {
(*c)->next = a;
(*c) = (*c)->next;
a = a->next;
}
}
if (b) {
while (b) {
(*c)->next = b;
(*c) = (*c)->next;
b = b->next;
}
}
Теперь указатель c хранит адрес последнего узла, а нам нужна ссылка на голову. Она как раз хранится во второй переменной tmp
*c = tmp.next;
Весь алгоритм
void merge(Node *a, Node *b, Node **c) {
Node tmp;
*c = NULL;
if (a == NULL) {
*c = b;
return;
}
if (b == NULL) {
*c = a;
return;
}
if (a->value < b->value) {
*c = a;
a = a->next;
} else {
*c = b;
b = b->next;
}
tmp.next = *c;
while (a && b) {
if (a->value < b->value) {
(*c)->next = a;
a = a->next;
} else {
(*c)->next = b;
b = b->next;
}
(*c) = (*c)->next;
}
if (a) {
while (a) {
(*c)->next = a;
(*c) = (*c)->next;
a = a->next;
}
}
if (b) {
while (b) {
(*c)->next = b;
(*c) = (*c)->next;
b = b->next;
}
}
*c = tmp.next;
}
Ещё одна важная функция – нахождение середины списка. Для этих целей будем использовать два указателя. Один из них — fast – за одну итерацию будет два раза изменять значение и продвигаться по списку вперёд. Второй – slow, всего один раз. Таким образом, если список чётный, то slow окажется ровно посредине списка, а если список нечётный, то второй подсписок будет на один элемент длиннее.
void split(Node *src, Node **low, Node **high) {
Node *fast = NULL;
Node *slow = NULL;
if (src == NULL || src->next == NULL) {
(*low) = src;
(*high) = NULL;
return;
}
slow = src;
fast = src->next;
while (fast != NULL) {
fast = fast->next;
if (fast != NULL) {
fast = fast->next;
slow = slow->next;
}
}
(*low) = src;
(*high) = slow->next;
slow->next = NULL;
}
Очевидно, что можно было один раз узнать длину списка, а потом передавать размер в каждую функцию. Это было бы проще и быстрее. Но мы не ищем лёгких путей)))
Теперь у нас есть функция, которая позволяет разделить список на две части и функция слияния отсортированных списков. С их помощью реализуем функцию сортировки слиянием.
Сортировка слиянием для односвязного списка
Функция рекурсивно вызывает сама себя, передавая части списка. Если в функцию пришёл список длинной менее двух элементов, то рекурсия прекращается. Идёт обратная сборка списка. Сначала из двух списков, каждый из которых хранит один элемент, создаётся отсортированный список, далее из таких списков собирается новый отсортированный список, пока все элементы не будут включены.
void mergeSort(Node **head) {
Node *low = NULL;
Node *high = NULL;
if ((*head == NULL) || ((*head)->next == NULL)) {
return;
}
split(*head, &low, &high);
mergeSort(&low);
mergeSort(&high);
merge(low, high, head);
}
Если Вы желаете изучать этот материал с преподавателем, советую обратиться к
репетитору по информатике
Q&A
Всё ещё не понятно? – пиши вопросы на ящик
The syntax of numpy append
Let’s take a look at the syntax of the np.append function.
Much like the other functions from NumPy, the syntax is fairly straightforward and easy to understand. Let’s break it down.

Typically, we call the function using the syntax . Keep in mind that this assumes that you’ve imported the NumPy module with the code .
Once you call the function itself – like all NumPy functions – there are a set of parameters that enable you to precisely control the behavior of the append function.
Let’s take a look at the parameters of NumPy append.
The parameter specifies the base array to which you will append the new values. Said differently, it’s the array that you’re going to modify by appending new values.
The parameter specifies the values that you want to append to the base array (i.e., the values you will append to the array specified in the parameter).
The values that you specify here can be presented as a list of literal values (i.e. ) or you can specify a object by providing the name of the NumPy array.
(optional)
The parameter specifies the axis upon which you will append the new values to the original array.
By default, . If you specify a value, you will specify axis equals or .
Now at this point, you might be asking … “what the hell is an axis?”
I’ll be honest. Axes in the NumPy system are one of the hardest things for most beginners to understand. It’s not that hard once they are explained, but array axes are not intuitive (at least, they aren’t intuitive the way they’ve been implemented in NumPy).
Axes are best explained with examples, so further down in this tutorial, I’ll show you exactly what the array axes are and how to think of them with respect to this syntax.
Реализация List
Будучи подтипом Collection, все методы в интерфейсе Collection также доступны в Listinterface.
Поскольку List — это интерфейс, вам необходимо создать конкретную реализацию интерфейса, чтобы использовать его. Вы можете выбирать между следующими реализациями List в API коллекций Java:
- java.util.ArrayList
- java.util.LinkedList
- java.util.Vector
- java.util.Stack
Также есть параллельные реализации List в пакете java.util.concurrent.
Вот несколько примеров того, как создать экземпляр List:
List listA = new ArrayList(); List listB = new LinkedList(); List listC = new Vector(); List listD = new Stack();
More Examples
Example
Move a list item from one list to another:
var node = document.getElementById(«myList2»).lastChild;
document.getElementById(«myList1»).appendChild(node);
Before appending:
- Coffee
- Tea
- Water
- Milk
After appending:
- Coffee
- Tea
- Milk
Water
Example
Create a <p> element and append it to a <div> element:
var para = document.createElement(«P»); // Create a <p> nodevar t = document.createTextNode(«This is a paragraph.»); // Create a text nodepara.appendChild(t); // Append the text to <p>
document.getElementById(«myDIV»).appendChild(para); // Append <p> to <div> with id=»myDIV»
Example
Create a <p> element with some text and append it to the end of the document
body:
var x = document.createElement(«P»); // Create a <p> nodevar t = document.createTextNode(«This is a paragraph.»); // Create a text nodex.appendChild(t); // Append the text to <p>document.body.appendChild(x); // Append <p> to <body>
Подсписок списка
Метод subList () может создавать новый List с подмножеством элементов из исходного List.
Метод subList () принимает 2 параметра: начальный индекс и конечный индекс. Начальный индекс — это индекс первого элемента из исходного списка для включения в подсписок.
Конечный индекс является последним индексом подсписка, но элемент в последнем индексе не включается в подсписок. Это похоже на то, как работает метод подстроки Java String.
List list = new ArrayList();
list.add("element 1");
list.add("element 2");
list.add("element 3");
list.add("element 4");
List sublist = list.subList(1, 3);
После выполнения list.subList (1,3) подсписок будет содержать элементы с индексами 1 и 2.
Преобразовать list в set
Вы можете преобразовать список Java в набор(set), создав новый набор и добавив в него все элементы из списка. Набор удалит все дубликаты.
Таким образом, результирующий набор будет содержать все элементы списка, но только один раз.
List list = new ArrayList();
list.add("element 1");
list.add("element 2");
list.add("element 3");
list.add("element 3");
Set set = new HashSet();
set.addAll(list);
Обратите внимание, что список содержит элемент String 3 два раза. Набор будет содержать эту строку только один раз
Таким образом, результирующий набор будет содержать строки: , and .
Общие списки
По умолчанию вы можете поместить любой объект в список, но Java позволяет ограничить типы объектов, которые вы можете вставить в список.
List<MyObject> list = new ArrayList<MyObject>();
Этот список теперь может содержать только экземпляры MyObject. Затем вы можете получить доступ к итерации его элементов без их приведения.
MyObject myObject = list.get(0);
for(MyObject anObject : list){
//do someting to anObject...
}
copy
Вообще он имеет несколько видов применения:
- Вывод элементов.
- Запись элементов.
- А также копирования какого-то количества ячеек и вставка их в позицию Y.
Чтобы его использовать дополнительно нужно подключить библиотеку — .
Но сейчас мы поговорим только о выводе элементов, если хотите узнать и о других функциях переходите вот сюда.
copy(myspisok.begin(), myspisok.end(), ostream_iterator<int>(cout,» «));
| 1 | copy(myspisok.begin(),myspisok.end(),ostream_iterator<int>(cout,» «)); |
Первые два значения (,) которые должны передать, — это итераторы начала и конца контейнера.
Дальше используем итератор вывода — . В кавычках указывается значение между элементами (в нашем случае это пробел).
Как удалить элементы из списка
Мы можем удалить один или несколько элементов из списка, используя ключевое слово del. При помощи этой команды вы так же можете удалить список полностью.
my_list = # Удалить один элемент del my_list # Результат: print(my_list) # Удалить несколько элементов del my_list # Результат: print(my_list) # Удалить весь список del my_list # Результат: Error: List not defined print(my_list)
Мы можем использовать метод remove() для удаления элемента или метод pop() для удаления элемента по указанному индексу.
Метод pop() удаляет последний элемент, если индекс не указан. Это помогает нам реализовывать списки в виде стеков «first come, last go» («первый вошел, последний вышел»).
Мы также можем использовать метод clear() для очистки списка от содержимого, без удаления самого списка.
my_list =
my_list.remove('p')
# Результат:
print(my_list)
# Результат: 'o'
print(my_list.pop(1))
# Результат:
print(my_list)
# Результат: 'm'
print(my_list.pop())
# Результат:
print(my_list)
my_list.clear()
# Результат: []
print(my_list)
Наконец, мы также можем удалить элементы в списке, назначив пустой список фрагменту элементов.
>>> my_list = >>> my_list = [] >>> my_list >>> my_list = [] >>> my_list






