7 способов перевода аудио и видео в текст
Содержание:
Ключевые понятия
Можно выделить ряд общих терминов, которые могут использоваться в процессе распознавания речи: 1) разборчивость речи — относительное количество правильно принятых элементов речи (звуков, слогов, слов, фраз), выраженное в процентах от общего числа переданных элементов; 2) нормальный темп речи — произнесение речи со скоростью, при которой средняя длительность контрольной фразы равна 2,4 с.; 3) ускоренный темп речи — произнесение речи со скоростью, при которой средняя длительность контрольной фразы равна 1,5-1,6 с.; 4) смысловая разборчивость — показатель степени правильного воспроизведения информационного содержания речи; узнаваемость голоса говорящего — возможность слушателей отождествлять звучание голоса, с конкретным лицом, известным слушателю ранее; 5) качество речи — параметр, характеризующий субъективную оценку звучания речи в испытуемой системе передачи речи; 6) интегральное качество — показатель, характеризующий общее впечатление слушателя от принимаемой речи.
Что можно сделать с продиктованным текстом
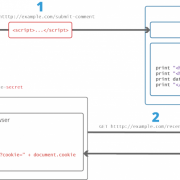
Рис. 4. Инструменты для работы с текстом, полученным с помощью произнесения речи.
На рис. 4 показаны с помощью цифр следующие инструменты для работы с продиктованным текстом:
1 – «Сорy» (Copy Text To Clipboard) Скопировать текст в буфер обмена для временного хранения;
2 – «Save» (Download File As Plain Text) Скачать файл в виде простого текста. Позволяет сохранить продиктованный текст в формате txt. В Windows для дальнейшей работы с этим форматом подойдет встроенный, бесплатный Блокнот;
3 – «Publish» (Publish Your Note Online) Опубликовать свою заметку в Интернете. Я проверила, к сожалению, у меня эта функция почему-то не работает;
4 на рис. 4 – «Tweet» (Share On Twitter) Поделиться заметкой в Twitter. Удобно произнести речь и полученный текст сразу поместить в Твиттер, если там есть аккаунт;
5 – «Play» (Text To Speech) Текст преобразовать в речь. Если нажать эту команду, появится меню. В нем можно кликнуть по синей кнопке «Speak» (Говорить). В итоге будет прочитан текст, который имеется в данный момент на экране. У меня был текст на русском языке, поэтому тетенька механическим голосом прочитала мой текст по-русски четко и внятно.
Данная функция работает с любым текстом, не обязательно с тем, что был перед этим проговорен. Можно вставить любой другой текст, чтобы услышать его «озвучку» роботом;
7 – «Print» (Save As PDF, or Print) Сохранить как PDF или Распечатать. Отличный вариант, чтобы получить сразу файл PDF, либо распечатать надиктованный текст на принтере.
8 на рис. 4 – «Clear» (Clear Dictation Notepad) Блокнот «Чистый диктант». Очистить все поле. После этого можно начать всё с чистого листа, либо закрыть сервис. Кроме того, достаточно закрыть вкладку в браузере с сервисом Dictation, и он будет закрыт.
Языки
Рис. 5. Примеры языков, для которых сервис Dictation переводит речь в текст.
В сервисе доступно большое количество языков, с которыми работает Dictation. Распознаётся речь на русском, на английском, на испанском, на французском, на немецком и так далее. Она превращается в текст на том же самом языке, на котором была произнесена. Автоматический перевод произнесенного текста на другой язык данный сервис не делает. Для перевода текстов нужно использовать, например, Гугл Переводчик или Яндекс.Перевочик.
Видео-формат статьи
В целом, очень удобный сервис. Рекомендую пользоваться, чтобы быстрее выполнять голосовой ввод текста.
Прошу проголосовать за один вариант из числа предложенных. Спасибо за участие!
Загрузка …
Также рекомендую другие онлайн-сервисы:
1. Squoosh: уменьшить размер фото без потери качества онлайн
2. Ventusky: интерактивный сервис погоды вашего региона и всего мира
3. Яндекс. ЕГЭ онлайн в помощь школьникам для подготовки к экзаменам
4. Пять сайтов для прохождения онлайн-курсов
5. Интернет как огромная библиотека онлайн
Применение
Основным преимуществом голосовых систем объявлялась дружественность к пользователю. Речевые команды должны были избавить конечного пользователя от необходимости использования сенсорных и иных методов ввода данных и команд.
- Голосовое управление
- Голосовые команды
- Голосовой ввод текста
- Голосовой поиск
Успешными примерами использования технологии распознавания речи в мобильных приложениях являются: ввод адреса голосом в Яндекс.Навигаторе, голосовой поиск Google Now.
Помимо мобильных устройств, технология распознавания речи находит широкое распространение в различных сферах бизнеса:
- Телефония: автоматизация обработки входящих и исходящих звонков путём создания голосовых систем самообслуживания в частности для: получения справочной информации и консультирования, заказа услуг/товаров, изменения параметров действующих услуг, проведения опросов, анкетирования, сбора информации, информирования и любые другие сценарии;
- Решения «Умный дом»: голосовой интерфейс управления системами «Умный дом»;
- Бытовая техника и роботы: голосовой интерфейс электронных роботов; голосовое управление бытовой техникой и т.д;
- Десктопы и ноутбуки: голосовой ввод в компьютерных играх и приложениях;
- Автомобили: голосовое управление в салоне автомобиля — например, навигационной системой;
- Социальные сервисы для людей с ограниченными возможностями.
Яндекс Переводчик
Сервис Яндекс Переводчик для перевода речи в текст работает в любых браузерах, в отличие от переводчика Гугла.
Выполните следующие шаги:
- Откройте страницу Яндекс Переводчик в браузере.
- Нажмите на значок микрофона (Голосовой ввод), расположенный в поле ввода исходного текста.
- Разрешите Яндекс Переводчику использовать микрофон на вашем компьютере.
- Говорите в микрофон, текст будет отображаться в окне переводчика. Одновременно текст будет синхронно переведен на другой язык, если вам необходима такая возможность.
В Яндекс Переводчик имеется возможность для перевода видео или аудио файлов из интернета:
- Включите микрофон на панели для ввода исходного текста.
- Откройте другую вкладку в браузере, запустите воспроизведение аудио или видео из интернета.
- В окне Яндекс Переводчика начнет отображаться текст. Параллельно будет вводится перевод на другой язык (если это вам нужно).
На Сервисе Яндекс Переводчик имеется ограничение в 10 000 знаков для одного перевода. Обход ограничения количества переведенных знаков:
- При подходе к лимиту, поставьте плеер на паузу, или прекратите диктовать в микрофон.
- Скопируйте в любой текстовый редактор переведенный текст.
- Включите голосовой ввод, а затем снова запустите воспроизведение исходного видео или аудио файла, чтобы продолжить перевод аудио в текст онлайн.
Преобразование речи в текст из видео или аудио файла, хранящегося на ПК, при помощи Яндекс Переводчика:
- Откройте окно Яндекс Переводчик, нажмите на кнопку «Голосовой ввод» (микрофон).
- При помощи мультимедиа плеера запустите видео или аудио файл на компьютере.
- В окне переводчика для ввода исходного текста появится перевод голоса в текст.
5 Dragon Dictation
Это приложение, которое распространяется бесплатно для мобильных устройств от компании Apple.
Программа может работать с 15 языками. Она позволяет редактировать результат, выбирать из списка нужные слова. Нужно четко проговаривать все звуки, не делать лишних пауз и избегать интонации. Иногда возникают ошибки в окончаниях слов.
Приложение Dragon Dictation используют обладатели яблочных гаджетов, например, чтобы, перемещаясь по квартире, надиктовать список покупок в магазине. Придя туда, они могут посмотреть на текст в заметке, и не надо слушать.
Только так можно будет получить безукоризненный текст без ошибок.
CMU Sphinx
Большая часть разработки CMU Sphinx ведется в университете Карнеги — Меллона. В разное время над проектом работали и Массачусетский технологический институт, и покойная ныне корпорация Sun Microsystems. Исходники движка распространяются под лицензией BSD и доступны как для коммерческого, так и для некоммерческого использования. Sphinx — это не пользовательское приложение, а, скорее, набор инструментов, который можно применить в разработке приложений для конечных пользователей. Sphinx сейчас — это крупнейший проект по распознаванию речи. Он состоит из нескольких частей:
- Pocketsphinx — небольшая быстрая программа, обрабатывающая звук, акустические модели, грамматики и словари;
- библиотека Sphinxbase, необходимая для работы Pocketsphinx;
- Sphinx4 — собственно библиотека распознавания;
- Sphinxtrain — программа для обучения акустическим моделям (записям человеческого голоса).
Проект развивается медленно, но верно. И главное — его можно использовать на практике. Причем не только на ПК, но и на мобильных устройствах. К тому же движок очень хорошо работает с русской речью. При наличии прямых рук и ясной головы можно настроить распознавание русской речи с помощью Sphinx для управления домашней техникой или умным домом. По сути, можно обычную квартиру превратить в умный дом, чем мы и займемся во второй части этого обзора. Реализации Sphinx имеются для Android, iOS и даже Windows Phone. В отличие от облачного способа, когда работа по распознаванию речи ложится на плечи серверов Google ASR или Яндекс SpeechKit, Sphinx работает точнее, быстрее и дешевле. И полностью локально. При желании можно научить Sphinx русской языковой модели и грамматике пользовательских запросов. Да, придется немного потрудиться при установке. Равно как и настройка голосовых моделей и библиотек Sphinx — занятие не для новичков. Так как основа CMU Sphinx — библиотека Sphinx4 — написана на Java, можно включать ее код в свои приложения для распознавания речи. Конкретные примеры использования будут описаны во второй части нашего обзора.
VoxForge
Особо выделим понятие речевого корпуса. Речевой корпус — это структурированное множество речевых фрагментов, которое обеспечено программными средствами доступа к отдельным элементам корпуса. Иными словами — это набор человеческих голосов на разных языках. Без речевого корпуса невозможна работа ни одной системы распознавания речи. В одиночку или даже небольшим коллективом создать качественный открытый речевой корпус сложно, поэтому сбором записей человеческих голосов занимается специальный проект — VoxForge.
Любой, у кого есть доступ к интернету, может поучаствовать в создании речевого корпуса, просто записав и отправив фрагмент речи. Это можно сделать даже по телефону, но удобней воспользоваться сайтом. Конечно, кроме собственно аудиозаписи, речевой корпус должен включать в себя дополнительную информацию, такую как фонетическая транскрипция. Без этого запись речи бессмысленна для системы распознавания.
VoxForge — стартовый портал для тех, кто хочет внести свой вклад в разработку открытых систем распознавания речи
Идентификация с использованием MFCC
Мы можем взять длительную запись голоса человека, посчитать кепстр для каждого маленького участка и получить уникальный отпечаток голоса в каждый момент времени. Но этот отпечаток слишком большой для хранения и анализа — он зависит от выбранной длины блока и может доходить до двух тысяч чисел на каждые 100 мс. Поэтому из такого многообразия необходимо извлечь определенное количество признаков. С этим нам поможет мел-шкала.
Мы можем выбрать определенные «участки слышимости», на которых просуммируем все сигналы, причем количество этих участков равно количеству необходимых признаков, а длины и границы участков зависят от мел-шкалы.
Вычисление мел-частотных кепстральных коэффициентов
Вот мы и познакомились с мел-частотными кепстральными коэффициентами (MFCC). Количество признаков может быть произвольным, но чаще всего варьируется от 20 до 40.
Эти коэффициенты отлично отражают каждый «частотный блок» голоса в каждый момент времени, а значит, если обобщить время, просуммировав коэффициенты всех блоков, мы сможем получить голосовой отпечаток человека.
Тестирование метода
Давай скачаем несколько записей видео с YouTube, из которых извлечем голос для наших экспериментов. Нам нужен чистый звук без шумов. Я выбрал канал TED Talks.
Скачаем несколько видеозаписей любым удобным способом, например с помощью утилиты youtube-dl. Она доступна через или через официальный репозиторий Ubuntu или Debian. Я скачал три видеозаписи выступлений: двух женщин и одного мужчины.
Затем преобразуем видео в аудио, создаем несколько кусков разной длины без музыки или аплодисментов.
Теперь разберемся с программой на Python 3. Нам понадобятся библиотеки для вычислений и для обработки звука, которые можно установить с помощью . Для твоего удобства все сложные вычисления коэффициентов упаковали в одну функцию . Загрузим звуковую дорожку и извлечем характеристики голоса.
Вариант 1. Присоединись к сообществу «Xakep.ru», чтобы читать все материалы на сайте
Членство в сообществе в течение указанного срока откроет тебе доступ ко ВСЕМ материалам «Хакера», увеличит личную накопительную скидку и позволит накапливать профессиональный рейтинг Xakep Score!
Подробнее
Вариант 2. Открой один материал
Заинтересовала статья, но нет возможности стать членом клуба «Xakep.ru»? Тогда этот вариант для тебя!
Обрати внимание: этот способ подходит только для статей, опубликованных более двух месяцев назад.
Я уже участник «Xakep.ru»
Характеристики голоса
В первую очередь голос определяется его высотой. Высота — это основная частота звука, вокруг которой строятся все движения голосовых связок. Эту частоту легко почувствовать на слух: у кого-то голос выше, звонче, а у кого-то ниже, басовитее.
Другой важный параметр голоса — это его сила, количество энергии, которую человек вкладывает в произношение. От силы голоса зависит его громкость, насыщенность.
Еще одна характеристика — то, как голос переходит от одного звука к другому. Этот параметр наиболее сложный для понимания и для восприятия на слух, хотя и самый точный — как и отпечаток пальца.
История
Первое устройство для распознавания речи появилось в 1952 году, оно могло распознавать произнесённые человеком цифры. В 1962 году на ярмарке компьютерных технологий в Нью-Йорке было представлено устройство IBM Shoebox.
В 1963 году в США были презентованы разработанные инженерами корпорации «Сперри» миниатюрные распознающие устройства с волоконно-оптическим запоминающим устройством под названием «Септрон» (Sceptron, но произносится без «к»), выполняющие ту или иную последовательность действий на произнесённые человеком-оператором определённые фразы. «Септроны» годились для применения в сфере фиксированной (проводной) связи для автоматизации набора номеров голосом и автоматической записи надиктовываемого текста телетайпом, могли применяться в военной сфере (для голосового управления сложными образцами военной техники), авиации (для создания «умной авионики», реагирующей на команды пилота и членов экипажа), автоматизированных системах управления и др. В 1983 году был презентован интерактивный комплекс «умной авионики» для ударных вертолётов «Апач», распознающий команды и запросы пилота, преобразующий их в сигналы управления на бортовое оборудование и односложно отвечающий ему голосом относительно возможности реализации поставленной им задачи.
Коммерческие программы по распознаванию речи появились в начале девяностых годов. Обычно их используют люди, которые из-за травмы руки не в состоянии набирать большое количество текста. Эти программы (например, Dragon NaturallySpeaking (англ.)русск., VoiceNavigator (англ.)русск.) переводят голос пользователя в текст, таким образом, разгружая его руки. Надёжность перевода у таких программ не очень высока, но с годами она постепенно улучшается.
Увеличение вычислительных мощностей мобильных устройств позволило и для них создать программы с функцией распознавания речи. Среди таких программ стоит отметить приложение Microsoft Voice Command, которое позволяет работать со многими приложениями при помощи голоса. Например, можно включить воспроизведение музыки в плеере или создать новый документ.
Все большую популярность применение распознавания речи находит в различных сферах бизнеса, например, врач в поликлинике может проговаривать диагнозы, которые тут же будут внесены в электронную карточку. Или другой пример. Наверняка каждый хоть раз в жизни мечтал с помощью голоса выключить свет или открыть окно. В последнее время в телефонных интерактивных приложениях все чаще стали использоваться системы автоматического распознавания и синтеза речи. В этом случае общение с голосовым порталом становится более естественным, так как выбор в нём может быть осуществлен не только с помощью тонового набора, но и с помощью голосовых команд. При этом системы распознавания являются независимыми от дикторов, то есть распознают голос любого человека.
Следующим шагом технологий распознавания речи можно считать развитие так называемых интерфейсов безмолвного доступа (silent speech interfaces, SSI). Эти системы обработки речи базируются на получении и обработке речевых сигналов на ранней стадии артикулирования. Данный этап развития распознавания речи вызван двумя существенными недостатками современных систем распознавания: чрезмерная чувствительность к шумам, а также необходимость четкой и ясной речи при обращении к системе распознавания. Подход, основанный на SSI, заключается в том, чтобы использовать новые сенсоры, не подверженные влиянию шумов в качестве дополнения к обработанным акустическим сигналам.
Приложение для перевода аудио голоса в текст – требования к системе
Большинство ныне существующих программ для перевода голоса в текст имеют платный характер, предъявляя ряд требований к микрофону (в случае, когда программа предназначена для компьютера). Крайне не рекомендуется работать с микрофоном, встроенным в веб-камеру, а также размещённым в корпусе стандартного ноутбука (качество распознавания речи с таких устройств находится на довольно низком уровне)
Кроме того, довольно важно иметь тихую окружающую обстановку, без лишних шумов, способных напрямую повлиять на уровень распознавания вашей речи
При этом большинство таких программ способны не только трансформировать речь в текст на экране компьютера, но и использовать голосовые команды для управления вашим компьютером (запуск программ и их закрытие, приём и отправление электронной почты, открытие и закрытие сайтов и так далее).

Пишите голосом комфортно
Как преобразовать аудио в текст
Способ №1
Данный способ, не требует ни каких настроек. Принцип заключается в следующем. Вы воспроизводите звуковой файл или видео, звук идёт через колонки, а микрофон захватывает звук из колонок. Вы также можете включить запись на диктофоне или смартфоне, и микрофон будет захватывать звук с этих устройств.

Схема №1
Открыв голосовой блокнот, переходим в раздел «Транскрибация».

Транскрибация
Сервис предоставляет возможность захвата аудио из видео YouTube, видео файлов и аудио файлов. Видео и аудио файлы при этом могут быть расположены как в интернете, так и на Вашем компьютере.
Для начала, рассмотрим пример открытия видео с YouTube. Для этого потребуется ID данного видео. Этот ID нужно вставить в поле «URL медиа файла для проигрывания» и нажать кнопку «Обновить».

Подключение видео с YouTube
Такой уникальный ID есть у каждого видео на YouTube. Увидеть его можно в адресной строке браузера.
Теперь рассмотрим пример с открытием файла на вашем компьютере.
Сначала указываете тип файла, аудио или видео. Затем нажимаете на кнопку «Выберите файл» и выберите файл на компьютере. Выбрав файл, нажимаете кнопку «Открыть».

Открыть файл с компьютера
Следующим этапом располагаете, микрофон рядом с колонками вашего компьютера или скажем диктофоном или смартфоном, и включаете запись.

Включаем запись
Далее полученный результат (готовый текст), копируете в текстовый редактор и редактируете как вам надо.
Способ №2
Данный способ позволяет исключить микрофон из цепочки преобразования аудио в текст. Звук будет напрямую передаваться из проигрывателя в голосовой блокнот
И уже не важно, какой у вас микрофон

Схема №2
Но для этого потребуется отдельная программа — Virtual Audio Cable. Данная программа создаёт виртуальный аудио кабель и передаёт аудиопоток между приложениями. Программа эта платная, стоит от 25$ до 50$. Но можно воспользоваться бесплатной версией. В бесплатной версии есть ограничение на количество виртуальных кабелей. Можно создать только 3 кабеля. А ещё женский голос постоянно напоминает, что это бесплатная версия если использовать аудиорепитер. Но скажу вам честно, можно обойтись и без него. Зато пробная версия не ограничена по времени. В видеоуроке я покажу, в чем хитрость.
Итак, для начала скачиваем программу «Виртуальный аудио кабель», ссылка выше.

Виртуальный аудио кабель
После того, как вы скачаете архивный файл на компьютер, его нужно распаковаться. Для этого можно воспользоваться архиватором или простым копирование файлов из архива в новую папку.

Распаковка архива
Когда архив будет распакован, запускайте файл установки, соответствующий разрядности вашей операционной системы. В смысле, 32 или 64 разрядная.
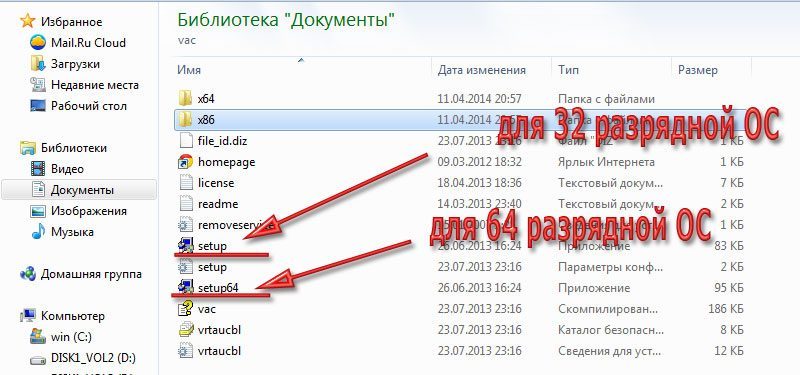
Установка программы VAC
Установка стандартная и не потребует от вас дополнительных знаний и умений. Просто следуйте указаниям мастера установки.
Далее, важный технический момент, нужно настроить в качестве устройства воспроизведения виртуальный аудио кабель.

Настройка аудиоустройства
Теперь Вы ни звука не услышите из ваших колонок, зато весь звук через виртуальный аудио кабель будет передаваться в голосовой блокнот. То, что нам и нужно.
Вот теперь можно открыть голосовой блокнот, перейти в раздел «Транскрибация» и выполнить перевод аудио в текст, как это было описано в первом способе. Только сейчас на надо подносить микрофон к колонкам.

Настройка аудиорепитера
Теперь вы будете слышать звук и женский голос, напоминающий о бесплатной версии программы, который после третьего повторения уже сводит с ума. Но, этим можно и не пользоваться, тем более, если вы знаете, о чём речь в вашем видео или аудио.
Всем желаю удачи.
Признаки эмоционально окрашенной речи в системах распознавания
Основные понятия, которые характеризуют параметры речи человека, связанные с формой, размерами, динамикой изменения речеобразующего тракта и описывающие эмоциональное состояния человека, можно разделить на четыре группы объективных признаков, позволяющих различать речевые образцы: спектрально-временные, кепстральные, амплитудно-частотные и признаки нелинейной динамики. Рассмотрим подробнее каждую группу признаков:
Спектрально-временные признаки
Спектральные признаки:
- Среднее значение спектра анализируемого речевого сигнала;
- Нормализованные средние значения спектра;
- Относительное время пребывания сигнала в полосах спектра;
- Нормализованное время пребывания сигнала в полосах спектра;
- Медианное значение спектра речи в полосах;
- Относительная мощность спектра речи в полосах;
- Вариация огибающих спектра речи;
- Нормализованные величины вариации огибающих спектра речи;
- Коэффициенты кросскорреляции спектральных огибающих между полосами спектра.
Временные признаки:
- Длительность сегмента, фонемы;
- Высота сегмента;
- Коэффициент формы сегмента.
Спектрально-временные признаки характеризуют речевой сигнал в его физико-математической сущности исходя из наличия компонентов трех видов:
- периодических (тональных) участков звуковой волны;
- непериодических участков звуковой волны (шумовых, взрывных);
- участков, не содержащих речевых пауз.
Кепстральные признаки
- Мел-частотные кепстральные коэффициенты;
- Коэффициенты линейного предсказания с коррекцией на неравномерность чувствительности человеческого уха;
- Коэффициенты мощности частоты регистрации;
- Коэффициенты спектра линейного предсказания;
- Коэффициенты кепстра линейного предсказания.
Амплитудно-частотные признаки
- Интенсивность, амплитуда
- Энергия
- Частота основного тона (ЧОТ)
- Формантные частоты
- Джиттер (jitter) — дрожание частотная модуляция основного тона (шумовой параметр);
- Шиммер (shimmer) — амплитудная модуляция на основном тоне (шумовой параметр);
- Радиальная базисная ядерная функция
- Нелинейный оператор Тигер
Признаки нелинейной динамики
- Отображение Пуанкаре;
- Рекуррентный график;
- Максимальный характеристический показатель Ляпунова — Эмоциональное состояние человека, которому соответствует определенная геометрия аттрактора (фазовый портрет);
- Фазовый портрет (аттрактор);
- Размерность Каплана-Йорка — количественная мера эмоционального состояния человека, от «спокойствия» до «гнева» (деформация и последующее смещение спектра речевого сигнала).
Параметры качества речи
Параметры качества речи по цифровым каналам можно определить по таким параметрам, как: слоговая разборчивость речи, фразовая разборчивость речи, качество речи по сравнению с качеством речи эталонного тракта и качеству речи в реальных условиях работы.
Классификация систем распознавания речи[править]
Системы распознавания речи классифицируются:
- по размеру словаря (ограниченный набор слов, словарь большого размера);
- по зависимости от диктора (дикторозависимые и дикторонезависимые системы);
- по типу речи (слитная или раздельная речь);
- по назначению (системы диктовки, командные системы);
- по используемому алгоритму (нейронные сети, скрытые Марковские модели, динамическое программирование);
- по типу структурной единицы (фразы, слова, фонемы, дифоны, аллофоны);
- по принципу выделения структурных единиц (распознавание по шаблону, выделение лексических элементов).
Голосовой набор текста в Word онлайн через Google Диск
Теперь давайте перейдем к вопросу, как технически осуществить голосовой набор текста в Word онлайн с помощью Гугл Диска. Дело в том, что существуют и другие возможности, но вариант с Google самый простой. Итак, процесс набора текста голосом онлайн в google показан в представленном ниже видео, но в статье будет описательная часть.
Для начала Вам нужно иметь почту в Google — почта gmail. Если она у Вас есть, отлично. Если ее пока нет ничего страшного, ее нужно завести. Делается это достаточно просто и быстро. Как завести почту gmail показано в моей статье Как создать канал на YouTube. Дело в том, что канал на YouTube нельзя завести без почты от Гугла.
Итак, если у нас есть почта от Гугла, то мы получаем доступ к огромному функционалу всего Google. Чтобы использовать функцию голосового набора текста на компьютере, нам нужно перейди на Google Диск (смотрите скрин).
Для этого нажимаем 9 небольших квадратиков, у нас появляются инструменты Гугла, нам нужно выбрать «Диск».
Далее, в новом окне, нужно выбрать слева «Создать» и выбрать Google Документы. После чего откроется окно похожее на Word. О том, как работать с Google Документами и таблицами онлайн (аналог Excel). Можете прочитать статьях на блоге.
После открытия Google Документов, нажимаем в верхней панели управления «Инструменты» и выбираем «Голосовой ввод». Слева у нас появляется микрофон, на который нужно только нажать, он активируется и становится красным. С этого момента пошла запись, и мы пишем текст голосом. Ура, голосовой набор текста в Word онлайн заработал.
Отдельно стоит сказать о настройках микрофона. Если у Вас установлена на компьютере вебкамера, то она, скорее всего, уже у Вас подключена и настроена. Если камеры нет, то следует подключить отдельно микрофон и настроить его работу. Это отдельная работа, описывать ее не буду, в Интернете полно информации, как настроить микрофон. Если микрофон рабочий, то Вы можете осуществлять набор текста голосом в Word.
Все, что Вы будете говорить записываться в виде текста. Попробуйте интересно! Знаки препинания нужно объявлять отдельно, например, говорить «Точка», «Запятая», «Вопросительный или восклицательный знак». Если хотим написать предложение с новой строки, нужно сказать «Абзац».