Nginx
Содержание:
Настройка в zabbix мониторинга nginx
В прошлой редакции этой статьи дальше шло описание скрипта, который будет парсить вывод nginx-status и передавать данные в zabbix. Сейчас все можно сделать гораздо проще и удобнее. На агенте не надо ничего настраивать. Все выполняется исключительно в шаблоне. То есть вам достаточно загрузить готовый шаблон для мониторинга nginx на zabbix сервер, прикрепить его к хосту и все будет работать.
Это удобный подход, который избавляет от необходимости настраивать агентов. Теперь все выполняется с сервера. Минус этого подхода только в том, что возрастает нагрузка на сервер мониторинга. Это плата за удобство и централизацию. Имейте это ввиду. Если у вас большая инсталляция мониторинга и есть средства автоматизации типа ansible, возможно вам имеет смысл по старинке парсить данные скриптом. Но в общем случае я рекомендую делать так, как я расскажу далее.
Суть мониторинга Nginx будет сводиться к тому, что мы через агента станем забирать страницу http://localhost/nginx-status на сервер. Там с помощью регулярных выражений и зависимых элементов данных будем формировать нужные метрики.
Представляю вам готовый шаблон для мониторинга nginx. Скачиваем его zabbix-nginx-template.xml и открываем web интерфейс zabbix сервера. Идем в раздел Configuration -> Templates и жмем Import:

Выбираем файл и снова нажимаем Import:

Шаблон я подготовил сам на основе своих представлений о том, что нужно мониторить. Проверил и экспортировал его с версии 4.2 Регулярные выражения для парсинга html страницы статуса подсмотрел тут — https://github.com/AlexGluck/ZBX_NGINX. К представленному шаблону я добавил некоторые итемы и переделал все триггеры. Плюс убрал макросы. Не вижу в них в данном случае смысла.
В шаблоне 11 итемов, описание которых я привел ранее.

Подробнее остановимся на триггерах. Их 5 штук.

- Many active connections — срабатывает если среднее количество соединений за последние 10 минут больше в 3 раза, чем среднее количество за интервал на 10 минут ранее.
- many requests и too many requests — срабатывают, когда среднее количество запросов за последние 10 минут больше в 3 и 6 раз соответственно, чем на 10 минут ранее.
- nginx is not running — тут все просто. Если не запущен ни один процесс nginx, шлем уведомление.
- nginx is slow to respond — срабатывает если время выполнения запроса на получение страницы со статусом за последние 10 минут больше предыдущих 10 минут в 2 раза.
С триггерами больше всего вопросов. Предложенная мной схема может работать независимо от проекта, не требует начальной калибровки, но могут быть ложные срабатывания из-за разовых очень сильных всплесков, которые быстро проходят, но сильно меняют средние параметры на интервале.
Более надежно могут сработать триггеры, где явно указаны лимиты в конкретных значениях. Но такой подход требует ручной калибровки на каждом проекте в отдельности. Надо смотреть средние значения метрик и выставлять лимиты в зависимости от них. Если проект будет расти, то лимиты постоянно придется менять. Это тоже не очень удобно и не универсально.
Я в итоге остановился на анализе средних значений, не используя конкретных лимитов. Как поступать вам, решайте отдельно, в зависимости от ситуации. Если у вас один проект, которому вы уделяете много внимания, то ставьте лимиты руками на основе анализа средних параметров. Если работаете на потоке с множеством проектов, то можно использовать мой вариант, он более универсален и не требует ручной правки.
Единственное, коэффициенты можно поправить, если будут ложные срабатывания. Но я обычно этот момент решаю через отложенные уведомления. Если чувствительность триггера очень высокая и есть кратковременные ложные срабатывания, меня они не беспокоят из-за 5-ти минутной задержки уведомлений. Зато при разборе инцидентов, эти кратковременные срабатывания помогают оценить ситуацию в целом.
С мониторингом nginx почти все готово. Теперь нам нужно прицепить добавленный шаблон к web серверу, который мы мониторим и дождаться поступления данных. Проверить их можно в Monitoring -> Latest Data:

В шаблоне есть несколько графиков. Не буду о них рассказывать, так как последнее время практически не пользуюсь графиками. Вместо этого собираю дашборды. Это более удобно и информативно. Жаль, что дашборды нельзя к шаблонам прикреплять. Очень хлопотно каждый раз вручную их составлять и тратить время. В конце покажу пример дашборда, который я использую для мониторинга web сервера.
На этом настройка мониторинга nginx закончена, можно пользоваться.
Дополнительная настройка
Лимит на объем отправляемого сообщения
Задается командой:
postconf -e «message_size_limit = 31457280»
* в данном примере выставлен лимит в 30 мб.
После перезапускаем сервис Postfix:
systemctl restart postfix
Настройка администратора для домена
В бесплатной версии программы из веб-панели можно назначить только глобального администратора. Но если нам нужно задать привилегированного пользователя только для одного домена, необходимо вносить настройки напрямую в базу данных.
Создаем пользователя в iredadmin и подключаемся к SQL-оболочке, в зависимости от того, какая СУБД была установлена. В нашем примере, это mariadb:
mysql -uroot -p
Используем базу vmail:
> use vmail
Изменим настройки для созданного пользователя:
* в данном примере мы указываем, что пользователь postmaster@test.local должен быть админом (isadmin=1), но не глобальным админом (isglobaladmin=0).
Теперь укажем, для какого домена пользователь должен быть администратором:
> INSERT INTO domain_admins (username, domain) VALUES (‘postmaster@test.local’, ‘test.local’);
* в данном примере мы добавили запись, в которой указали, что пользователь postmaster@test.local является администратором для домена test.local. При необходимости разрешить одному пользователю управлять несколькими доменами, мы должны выполнить несколько аналогичных запросов.
Перенаправление СПАМа на специальный ящик
По умолчанию, письма с отметкой в теме письма приходят на ящики пользователей. Если мы хотим, чтобы наш сервер пересылал все сообщения с подозрением на СПАМ в специальный ящик, выполняем следующее.
Открываем на редактирование файл:
vi /etc/postfix/header_checks
… и добавляем строку:
/^SUBJECT:\s+\/ REDIRECT spam@dmosk.ru
* в даной инструкции мы говорим проверять заголовок, и если находим в теме , перенаправляем письмо на ящик spam@dmosk.ru.
Проверяем настройку командой:
postmap -q «Subject: test» pcre:/etc/postfix/header_checks
Мы должны увидеть что-то на подобие:
REDIRECT spam@dmosk.ru
Теперь открываем файл:
vi /etc/postfix/master.cf
Находим в нем все опции no_header_body_checks и удаляем их. Данные опции запрещают проверку заголовков, что помешает нам использовать опцию header_checks в Postfix.
Перезапускаем службу mta:
systemctl restart postfix
Шаг 4. Настройка NGINX
Открываем/создаем файл конфигурации для виртуального домена:
vi /etc/nginx/conf.d/test.dmosk.local.conf
* где test.dmosk.local.conf может называться как угодно, главное — чтобы на конце было .conf.
Приводим его к следующему виду:
server {
listen 80;
server_name test-http2.dmosk.local;
return 301 https://$host$request_uri;
}
server {
listen 443 ssl http2;
ssl on;
ssl_certificate /etc/nginx/ssl/cert.pem;
ssl_certificate_key /etc/nginx/ssl/cert.key;
location / {
root /usr/share/nginx/html;
}
}
* в первых 4 строкам мы указываем перенаправлять все http-запросы на https; /etc/nginx/ssl/ — путь, где лежат наши файлы сертификатов; /usr/share/nginx/html — корневая директория, где лежат файлы сайта.
Проверяем корректность настройки nginx:
nginx -t
И перезапускаем его:
systemctl restart nginx
* на более ранних системах service nginx restart.
Шаг 9 — Настройка сайтов HTTPS с Let’s Encrypt (опционально)
На этом шаге мы настроим сертификаты TLS/SSL для обоих доменов, размещенных в Apache. Мы получим сертификаты посредством Let’s Encrypt. Nginx поддерживает конечные узлы SSL, и поэтому мы можем настроить SSL без изменения файлов конфигурации Apache. Модуль обеспечивает установку в Apache переменных среды, необходимых для бесшовной работы приложений за обратным прокси-сервером SSL.
Вначале мы разделим блоки обоих доменов так, что у каждого из них будет собственный сертификат SSL. Откройте в своем редакторе файл :
Измените файл, чтобы он выглядел следующим образом, сайты и должны находиться в собственных блоках:
/etc/nginx/sites-available/apache
Мы используем Certbot для генерирования сертификатов TLS/SSL. Плагин Nginx изменит конфигурацию Nginx и перезагрузит ее, когда это потребуется.
Прежде всего, добавьте официальное хранилище Certbot:
Нажмите в диалоге, чтобы подтвердить добавление нового хранилища. Обновите список пакетов, чтобы получить данные пакета нового хранилища:
Установите пакет Certbot’s Nginx с :
После установки используйте команду для генерирования сертификатов для и :
Эта команда указывает Certbot, что нужно использовать плагин , а параметр задает имена, для которых должен действовать сертификат.
Если это первый запуск , вам будет предложено указать адрес эл. почты и принять условия обслуживания. После этого свяжется с сервером Let’s Encrypt и отправит запрос с целью подтвердить, что вы контролируете домен, для которого запрашиваете сертификат.
Далее Certbot запросит желаемый вариант настройки HTTPS:
Выберите желаемый вариант и нажмите . Конфигурация будет обновлена, а затем будет выполнена перезагрузка Nginx для активации новых настроек.
Теперь выполните команду для второго домена:
Откройте один из доменов Apache в браузере с помощью префикса ; откройте , и вы увидите следующее:

Посмотрите раздел PHP Variables. Для переменной SERVER_PORT задано значение 443 и протокол HTTPS включен, как если бы осуществлялся прямой доступ к Apache через HTTPS. При такой настройке переменных не нужно специально настраивать приложения PHP для работы за обратным прокси-сервером.
Теперь отключим прямой доступ к Apache.
Nginx fastcgi_cache # Nginx fastcgi_cache
Nginx can perform caching on its own end to reduce load on your server. When you want to use Nginx’s built-in fastcgi_cache, you better compile nginx with fastcgi_cache_purge module. It will help nginx purge cache for a page when it gets edited. On the WordPress side, you need to install a plugin like Nginx Helper to utilize fastcgi_cache_purge feature.
Config will look like below:
Define a Nginx cache zone in http{…} block, outside server{…} block
#move next 3 lines to /etc/nginx/nginx.conf if you want to use fastcgi_cache across many sites fastcgi_cache_path /var/run/nginx-cache levels=1:2 keys_zone=WORDPRESS:500m inactive=60m; fastcgi_cache_key "$scheme$request_method$host$request_uri"; fastcgi_cache_use_stale error timeout invalid_header http_500;
For WordPress site config, in server{..} block add a cache check block as follow
#fastcgi_cache start
set $no_cache 0;
# POST requests and urls with a query string should always go to PHP
if ($request_method = POST) {
set $no_cache 1;
}
if ($query_string != "") {
set $no_cache 1;
}
# Don't cache uris containing the following segments
if ($request_uri ~* "(/wp-admin/|/xmlrpc.php|/wp-(app|cron|login|register|mail).php|wp-.*.php|/feed/|index.php|wp-comments-popup.php|wp-links-opml.php|wp-locations.php|sitemap(_index)?.xml|+-sitemap(+)?.xml)") {
set $no_cache 1;
}
# Don't use the cache for logged in users or recent commenters
if ($http_cookie ~* "comment_author|wordpress_+|wp-postpass|wordpress_no_cache|wordpress_logged_in") {
set $no_cache 1;
}
Then make changes to PHP handling block
Just add this to the following php block. Note the line which tells nginx only to cache 200 responses(normal pages), which means that redirects are not cached. This is important for multilanguage sites where, if not implemented, nginx would cache the main url in one language instead of redirecting users to their respective content according to their language.
fastcgi_cache_bypass $no_cache;
fastcgi_no_cache $no_cache;
fastcgi_cache WORDPRESS;
fastcgi_cache_valid 200 60m;
Such that it becomes something like this
location ~ \.php(/|$) {
fastcgi_split_path_info ^(.+?\.php)(/.*)$;
if (!-f $document_root$fastcgi_script_name) {
return 404;
}
# This is a robust solution for path info security issue and works with "cgi.fix_pathinfo = 1" in /etc/php.ini (default)
include fastcgi.conf;
fastcgi_index index.php;
# fastcgi_intercept_errors on;
fastcgi_pass php;
fastcgi_cache_bypass $no_cache;
fastcgi_no_cache $no_cache;
fastcgi_cache WORDPRESS;
fastcgi_cache_valid 200 60m;
}
Finally add a location for conditional purge
location ~ /purge(/.*) {
# Uncomment the following two lines to allow purge only from the webserver
#allow 127.0.0.1;
#deny all;
fastcgi_cache_purge WORDPRESS "$scheme$request_method$host$1";
}
If you get an ‘unknown directive “fastcgi_cache_purge”‘ error check that your Nginx installation has fastcgi_cache_purge module.
Дашборд Zabbix для Web сервера
Как и обещал, в завершении статьи по настройке мониторинга web сервера, показываю пример своего дашборда в zabbix для мониторинга bitrix сайта. Картинка очень большая, по клику открывается полная версия, если открыть в новой вкладке.
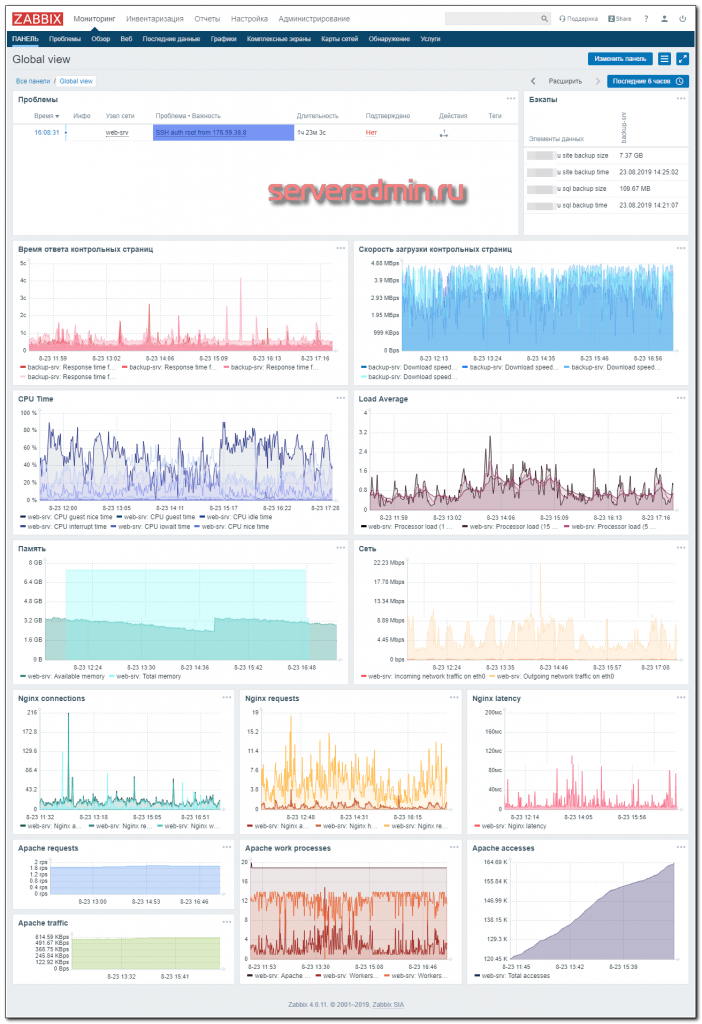
В самом верху список текущих проблем. В настоящий момент висит активный триггер о ssh подключению к серверу. Описание его настройки — мониторинг ssh подключений. Справа от списка проблем — мониторинг бэкапов в zabbix.
Ниже идут метрики с мониторинга web сайта. Выбирается контрольный набор из нескольких страниц (обычно 3-5) и настраивается мониторинг времени ответа и скорости загрузки этих страниц. Для этих параметров настроены триггеры, так как они очень важны. По сути, это ключевые метрики. Если с ними проблемы, надо внимательно смотреть web сервер и разбираться, в чем проблема. Мониторинг web сайта нужно настраивать минимум с двух независимых серверов zabbix, иначе вы не сможете отличить проблемы доступа с сервера мониторинга к сайту от реальных проблем сайта. Только если оба сервера мониторинга сигнализируют о проблемах, можно сделать однозначный вывод о том, что с сайтом и web сервером что-то не так.
Дальше идут метрики из шаблонов, которые я рассмотрел в этой статье. Если у вас вместо apache используется php-fpm, то все примерно то же самое, только в самом низу метрики от php-fpm. Не буду приводить пример с ним, чтобы не загромождать статью. Думаю, приведенного дашборда и так достаточно.
В принципе, сюда можно было бы добавить информацию по I/O дисков, инфу с сетевого стека, данные Mysql. Не стал этого делать, так как это обзорный dashboard, который беглым просмотром позволяет оценить состояние сервера. Так же этот дашборд можно показать заказчику. Для более глубокого анализа проблем, нужно собирать отдельную панель.