Что значит «парсинг» в интернет-сленге и зачем он используется?
Содержание:
- Ошибка парсера xml: что это?
- Парсеры сайтов в зависимости от используемой технологии
- Что делает парсер?
- Парсинг html-сайтов с помощью PHP, Ruby, Python
- «Юриста вызывали? Цитировать нельзя парсить»
- Парсеры сайтов по способу доступа к интерфейсу
- Особенности парсинга веб-сайтов
- Что такое парсинг сайтов и зачем он нужен
- Зачем нужен парсинг и парсеры?
- Язык программирования для написания парсера
- Парсить – что это значит? Определение и цели
- Парсить — что это обозначает простыми словами?
- Что представляет собой парсер
- Технические и этические проблемы
- Виды парсинга
- Для чего используют
Ошибка парсера xml: что это?
Иногда пользователи данной программы встречают ошибку парсера xml. Что это означает, практически никто не знает. В основном проблема заключается в том, что используются разные версии синтаксического анализатора XML, когда одна строже другой.
Также вполне вероятно у Вас имеется не точная копия файла
Внимательно посмотрите, как копируются файлы и обратите внимание на то, как берется контрольная сумма MD5 двух файлов, одинакова ли она. Говорить о том, что такое простыми словами нейминг это все равно, что сказать об возможных проблемах данной программы.
В таких случаях единственное, что можно сделать, это проверить строку 1116371. Вышеуказанная программа на С # покажет данную строку, а Вы сможете изменить кодировку UTF-8.
Парсеры сайтов в зависимости от используемой технологии
Парсеры на основе Python и PHP
Такие парсеры создают программисты. Без специальных знаний сделать парсер самостоятельно не получится. На сегодня самый популярный язык для создания таких программ Python. Разработчикам, которые им владеют, могут быть полезны:
- библиотека Beautiful Soup;
- фреймворки с открытым исходным кодом Scrapy, Grab и другие.
Заказывать разработку парсера с нуля стоит только для нестандартных задач. Для большинства целей можно подобрать готовые решения.
Парсеры-расширения для браузеров
Парсить данные с сайтов могут бесплатные расширения для браузеров. Они извлекают данные из html-кода страниц при помощи языка запросов Xpath и выгружают их в удобные для дальнейшей работы форматы — XLSX, CSV, XML, JSON, Google Таблицы и другие. Так можно собрать цены, описания товаров, новости, отзывы и другие типы данных.
Примеры расширений для Chrome: Parsers, Scraper, Data Scraper, kimono.
Парсеры сайтов на основе Excel
В таких программах парсинг с последующей выгрузкой данных в форматы XLS* и CSV реализован при помощи макросов — специальных команд для автоматизации действий в MS Excel. Пример такой программы — ParserOK. Бесплатная пробная версия ограничена периодом в 10 дней.
Парсинг при помощи Google Таблиц
В Google Таблицах парсить данные можно при помощи двух функций — importxml и importhtml.
Функция IMPORTXML импортирует данные из источников формата XML, HTML, CSV, TSV, RSS, ATOM XML в ячейки таблицы при помощи запросов Xpath. Синтаксис функции:
IMPORTXML("https://site.com/catalog"; "//a/@href")
IMPORTXML(A2; B2)
Расшифруем: в первой строке содержится заключенный в кавычки url (обязательно с указанием протокола) и запрос Xpath.
Знание языка запросов Xpath для использования функции не обязательно, можно воспользоваться опцией браузера «копировать Xpath»:
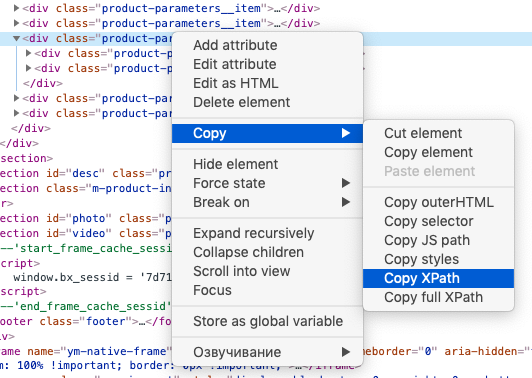
Вторая строка указывает ячейки, куда будут импортированы данные.
IMPORTXML можно использовать для сбора метатегов и заголовков, количества внешних ссылок со страницы, количества товаров на странице категории и других данных.
У IMPORTHTML более узкий функционал — она импортирует данные из таблиц и списков, размещенных на странице сайта. Синтаксис функции:
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)
IMPORTHTML(A2; B2; C2)
Расшифруем: в первой строке, как и в предыдущем случае, содержится заключенный в кавычки URL (обязательно с указанием протокола), затем параметр «table», если хотите получить данные из таблицы, или «list», если из списка. Числовое значение (индекс) означает порядковый номер таблицы или списка в html-коде страницы.
Что делает парсер?
Ответить на вопрос, что делает парсер довольно просто. Механизм в соответствии с программой сверяет конкретный набор слов с тем, что нашлось в интернете. Дальнейшее действие касательно полученной информации будет задано в командной строке.
Стоит отметить, что программное обеспечение может иметь разные форматы представления, стилистику оформления, варианты доступности, языки и многое другое. Здесь, как и в тарифах контекстной рекламы имеет место быть большое количество возможных вариаций.
Работа всегда происходит в несколько этапов. Сначала происходит поиск сведений, загрузка и скачивание. Далее значения извлекаются из кода вэб-страницы так, что материал отделяется от программного кода страницы. В итоге формируется отчет в соответствии с заданными требованиями напрямую в базу данных или сохраняется в текстовой файл.
Парсер сайта дает много преимуществ при работе с массивами данных. Например, высокую скорость обработки материалов и их анализ даже в огромном объеме. Также автоматизируется процесс отбора сведений. Однако отсутствие своего контента негативно сказывается на SEO.
Парсинг html-сайтов с помощью PHP, Ruby, Python
В общем смысле, парсинг – это линейное сопоставление последовательности слов с правилами языка. Понятие «язык» рассматривается в самом широком контексте. Это может быть человеческий язык (например, русский), используемый для коммуникации людей. А может и формализированный язык, в частности, любой язык программирования.
Парсинг сайтов – последовательный синтаксический анализ информации, размещённой на интернет-страницах.
Что представляет из себя текст интернет-страниц? Иерархичный набор данных, структурированный с помощью человеческих и компьютерных языков.
Макросы VBA. Пора использовать Excel правильно!
Зачем нужен парсинг?
Создавая веб-сайт, его владелец неизбежно сталкивается с проблемой – где брать контент? Оптимальный вариант: найти информацию там где её очень много – в Интернете. Но при этом приходится решать такие задачи:
- Большие объёмы. В эпоху бурного роста Сети и жесточайшей конкуренции уже всем ясно, что успешный веб-проект немыслим без размещения большого количества информации на сайте. Современные темпы жизни приводят к тому, что контента должно быть не просто много, а очень много, в количествах, намного превышающих пределы, возможные при ручном заполнении.
- Частое обновление. Обслуживание огромного потока динамично меняющейся информации не в силах обеспечить один человек или даже слаженная команда операторов. Порой информация изменяется ежеминутно и в ручном режиме обновлять её вряд ли целесообразно.
Конвертация CSV в YML. Прайс для Яндекса в нужном формате.
Парсинг сайтов является эффективным решением для автоматизации сбора и изменения информации.
По сравнению с человеком, компьютерная программа-парсер:
- быстро обойдёт тысячи веб-страниц;
- аккуратно отделит техническую информацию от «человеческой»;
- безошибочно отберёт нужное и отбросит лишнее;
- эффективно упакует конечные данные в необходимом виде.
Результат (будь то база данных или электронная таблица), конечно же, нуждается в дальнейшей обработке. Впрочем, последующие манипуляции с собранной информацией уже к теме парсинга не относятся.
Какие языки программирования используются для написания парсеров?
Любые, на которых создаются программы для работы со Всемирной Паутиной. Веб-приложения для парсинга обычно пишут на C++, Delphi, Perl, Ruby, Python, PHP.
Данный сайт создавался для того, чтобы продемонстрировать методы парсинга на самых популярных языках веб-программирования – PHP, Ruby и Python.
«Юриста вызывали? Цитировать нельзя парсить»
- «От подглядывания до воровства — один шаг». Даже если разрешено всё, что не запрещено, то, считают наши читатели, «подглядывать в замочную скважину как минимум некрасиво, а если клиент потом ещё и выдаёт спарсенное за свое — то это уже прямое воровство. Конечно, понятно, что в бизнесе все так делают. Но в приличном обществе всё же принято об этом молчать.» Однако, парсить для кого-то и выдавать спарсенное за своё, как говорится, две большие разницы: «Вы путаете мягкое и холодное. Мы действительно оказываем услугу по парсингу. Но ровно так же можно обвинять производителей, например, оружия в том, что с его помощью убивают. Мы делаем бизнес, а в бизнесе есть одно правило — законно это или нет. Моя точка зрения… Если к нам приходят клиенты и готовы платить много, чтобы получить данные — это разве плохо…»
- «Сделал приложение для сайта СМИ — прибили за жалобу». Сайт Forbes, парсинг, приложение на Google Play — что могло пойти не так? «В свое время решил сделать приложение для сайта Forbes. Чтобы получать статьи с сайта — сделал парсинг страниц. Настроил всё в автоматическом режиме и сделал приложение для Андроид. Выложил приложение в маркет. Через год со мной связался юрист и потребовал удалить приложение, потому что я нарушаю авторские права. Спорить не стал. Обидно, что у самого Forbes нет приложения по их же статьям с сайта. Есть только сайт. А сайт у них тормозной, долго грузится и увешан рекламой…»
- «Моя база данных — мое произведение под защитой!». Авторское право — ещё одно понятие, которому можно посвятить с десяток страниц обсуждений (помимо сотен тысяч уже существующих), однако не упомянуть его никак тоже неправильно. Наш читатель выдал концепцию: «Некто создал базу товаров. Потратил кучу ресурсов на поиск информации, систематизацию этой информации, вынесение данных в базу. Вы по просьбе конкурента эту базу спарсиваете и за деньги отдаете тому самому конкуренту. Вы считаете, что здесь нет этических проблем? Касательно законности — не знаю, как в РФ, но в Украине БД может быть объектом авторского права.»
Однако, ответственность за пользование услугой или товаром всё ещё лежит на том, кто её/его приобретает и с какой целью использует: «… и в России тоже. Мы оказываем услугу по сбору данных. И за эту услугу просим деньги. Мы не продаем сами данные. Я, к слову, всех клиентов предупреждаю, что они могут нарушить закон если будут использовать, например, описания.» - «Формально вы правы, но статью на вас нашел!» В УК РФ (статья 146) описываются только масштабы нарушений, которые позволяют классифицировать нарушение авторских прав как «уголовку». Сами по себе права описаны в ГК — а на масштабы, позволяющие классифицировать деяние как «уголовку», регулярный парсинг, такой, что возникает вопрос «а не ляжет ли сайт», без проблем вытягиваются. Но важны аспекты:
- Там «крупный размер» — это не в количестве спарсенных страниц, а в деньгах. Как вы вообще оцените парсинг (и его регулярность), как нарушение авторских прав (!), в деньгах? А как обычно в таких случаях делают и откуда может штраф в сотни тысяч долларов за одну копию фильма взяться? Высчитывается «упущенная прибыль» с соответствующим коэффициентом. Можно с каких-нибудь договоров просчитать — сколько будет стоит купить у вас ту же информацию легально и отсюда «плясать». Но, для начала, вы должны её изначально продавать (а не выкладывать в публичный доступ), выдумывать цифру задним числом не «прокатит». Хотя и тут риски есть: знаете, сколько стоит коммерческая лицензия на условный Консультант-Плюс? Как только Вы полезете дальше десятка основных законов, вы быстро наткнетесь на предложение купить ту самую коммерческую версию.
- Наша история точно не из уголовного дела (и Вы не путайте штраф и ущерб. Вот вы по хулиганке разбили бутылку пива: ущерб — 30 рублей, штраф — до 1000р, а по гражданскому иску потом хоть триллион отсуживайте за «упущенную выгоду», но это уже не штраф). Вы же прайс не продаете вообще, что эксперт то сочинять будет? Конкретно, а не «хороший юрист натянет без проблем».
Резюмируя:«— Каким образом парсинг стал равен нарушению авторских прав? — Никоим. Нарушение — это заказать у нас парсинг, а потом вывалить контент на свой сайт. «Положить» сайт — это другая статья.» xmldatafeed.com
Парсеры сайтов по способу доступа к интерфейсу
Облачные парсеры
Облачные сервисы не требуют установки на ПК. Все данные хранятся на серверах разработчиков, вы скачиваете только результат парсинга. Доступ к программному обеспечению осуществляется через веб-интерфейс или по API.
Примеры облачных парсеров с англоязычным интерфейсом:
- http://import.io/,
- Mozenda (есть также ПО для установки на компьютер),
- Octoparce,
- ParseHub.
Примеры облачных парсеров с русскоязычным интерфейсом:
- Xmldatafeed,
- Диггернаут,
- Catalogloader.
У всех сервисов есть бесплатная версия, которая ограничена или периодом использования, или количеством страниц для сканирования.
Программы-парсеры
ПO для парсинга устанавливается на компьютер. В подавляющем большинстве случаев такие парсеры совместимы с ОС Windows. Обладателям mac OS можно запускать их с виртуальных машин. Некоторые программы могут работать со съемных носителей.
Примеры парсеров-программ:
- ParserOK,
- Datacol,
- SEO-парсеры — Screaming Frog, ComparseR, Netpeak Spider и другие.
Особенности парсинга веб-сайтов
Одной из особенностей парсинга веб-сайтов является то, что как правило мы работаем с исходным кодом страницы, т.е. HTML кодом, а не тем текстом, который показывается пользователю. Т.е. при создании регулярного выражения grep нужно основываться на исходном коде, а не на результатах рендеринга. Хотя имеются инструменты и для работы с текстом, получающимся в результате рендеринга веб-страницы – об этом также будет рассказано ниже.
В этом разделе основной упор сделан на парсинг из командной строки Linux, поскольку это самая обычная (и привычная) среда работы для тестера на проникновение веб-приложений. Будут показаны примеры использования разных инструментов, доступных из консоли Linux. Тем не менее, описанные здесь приёмы можно использовать в других операционных системах (например, cURL доступна и в Windows), а также в качестве библиотеки для использования в разных языках программирования.
Подразумевается, что вы понимаете принципы работы командной строки Linux. Если это не так, то рекомендуется ознакомиться с циклом:
- Азы работы в командной строке Linux (часть 1)
- Азы работы в командной строке Linux (часть 2)
- Азы работы в командной строке Linux (часть 3)
Что такое парсинг сайтов и зачем он нужен
Познакомиться поближе и получить краткий мануал об использовании можно (на русском) или на moz.com (на английском). Давайте попробуем спарсить что-нибудь хорошее с помощью Kimono. Например, дополним созданную нами таблицу с городами списком курортов в стране Города 2. Как это можно реализовать при помощи Kimono Labs. Нам понадобятся:
- приложение для Google Chrome — Kimono;
- таблица Google Docs.
1. Находим сайт с необходимой нам информацией — то есть перечнем стран и их курортов. Открываем страницу, откуда необходимо получить данные.
2. Кликаем на иконку Kimono в правом верхнем углу Chrome.
3. Выделяем те части страницы, данные из которых нам необходимо спарсить. Если нужно выделить новый тип данных на той же странице, кликаем на «+» справа от «property 1
» — так указываем Kimono, что эти данные нужно разместить в новом столбце.
4. Кликнув на фигурные скобки и выбрав «CSV
», можно увидеть, как выбранные данные будут располагаться в таблице.
5. Когда все данные отмечены:
- кликаем «Done
» (в правом верхнем углу); - логинимся в Kimono, чтобы привязать API к своему аккаунту;
- вводим название будущего АРI;
- кликаем «Create API
».
6. Когда API создано, переходим в таблицу Google, куда хотим загрузить выбранные данные. Выбираем «Connect to Kimono
» и кликаем на название нашего API — «Resorts
». Список стран и ссылок на страницы с курортными городами выгружается на отдельный лист.
7. Переходим снова на сайт, берем для примера Ирландию, и снова выбираем через Kimono города, которые необходимо спарсить. Создаем API, называем его «Resorts in countries
».
9. В «Crawl Strategy
» выбираем «URLs from source API
». Появляется поле с выпадающим списком всех API. Выбираем созданное нами ранее API «Resorts
» и из него автоматически загружается список URL для парсинга. Кликаем синюю кнопку «Start Crawl
» (начать обход) и следим за статусом парсинга. Kimono обходит страницы, парсит данные по заданному ранее шаблону и добавляет их в таблицу — то есть делает все то же самое, что и для Ирландии, но уже для всех других стран, что ввели автоматически и без нашего участия.
10. Когда таблица сформирована, синхронизируем Kimono Labs с таблицей Google — точно так же, как делали это в шестом пункте. В результате, в таблице появляется второй лист с данными.
Предположим, хотим, чтобы в таблице отображались все курортные города в стране города прибытия. Данные на листах Kimono обрабатываем с помощью формул для таблиц Google, и выводим в строку список городов, где еще можно отдохнуть в Австралии, кроме Сиднея.
Например, это можно сделать так
. Разметить массив данных (список городов), используя логические функции и возвращая значение ячейке, равное TRUE или FALSE. На примере ниже выделили для себя города, которые находятся именно в Австралии:
- TRUE = город находится в Австралии;
- FALSE = город находится в другой стране.
По меткам TRUE определяем начало и конец обрабатываемого диапазона, и выводим в строку соответствующие этому диапазону города.
По аналогии можем вывести курортные города и для других стран.
Мы специально привели здесь достаточно простой и пошаговый пример — формулу можно усложнить, например, сделать так, чтобы достаточно было ввести страну в колонку С, а все остальные вычисления и вывод городов в строку происходили автоматически.
Зачем нужен парсинг и парсеры?
Для создания сайта и его требуется большое количество контента, который необходимо долго создавать в ручном режиме.
Парсеры обладают следующими возможностями:
- Обновление информации для поддержки актуальности. Отслеживать изменения курса валют или прогноза погоды в ручном режиме нереально, поэтому прибегают к парсингу.
- Сбор и быстрое копирование информации с других сайтов для размещения на собственном ресурсе. Данные, полученные с помощью парсинга, подвергают . Такое решение используется для заполнения киносайтов, новостных проектов, ресурсов с кулинарными рецептами и прочих площадок.
- Соединение потоков данных. Проводится сбор большого количества данных с нескольких источников, обработка и размещение. Это удобно для заполнения новостных площадок.
Парсинг существенно ускоряет процесс работы с ключевыми словами. Настроив работу, возможно оперативно подобрать необходимые для продвижения запросы. После кластеризации по страницам подготавливается SEO-контент, в котором будет учтено максимум ключей.
Особенности работы парсера
Парсеры пишутся на любом языке программирования (PHP, C++, Delphi и других), где присутствует поддержка регулярных выражений. Это набор метасимволов, используемых для поиска необходимых данных.
Парсер за короткий срок обходит тысячи страниц, фильтрует представленные данные, отбирая среди них нужные, после чего пакует полученный результат для последующей обработки.
Язык программирования для написания парсера
Для написания парсера подойдет любой язык, используемый в работе с Интернетом. Зачастую программы-парсеры пишутся на Ruby, PHP, Python, Perl и C++. Язык написания выбирается вэб-мастером в зависимости от цели использования и его собственных возможностей.
Привет, ребят. Опережая события, хочу предупредить, что для того, чтобы парсить сайты необходимо владеть хотя бы php. У меня есть интересная статья о том, . И все же, что такое парсинг?
Начнем с определения. В этой статье речь пойдет о парсинге сайтов. Попробую объяснить как можно проще и доходчивее.
Парсинг, что это значит: слово понятное дело пришло от английского parse -по факту это означает разбор содержимого страницы на отдельные составляющие. Этот процесс происходит автоматически благодаря специальным программам (парсеров).
В пример парсера можно привести поисковые системы. Их роботы буквально считывают информацию с сайтов, хранят данные об их содержимом в своих базах и когда вы вбиваете поисковой запрос они выдают самые подходящие и актуальные сайты.
Кстати говоря, если вы планируете сделать мощное приложение, которое могло бы работать удаленно, то вам может понадобиться аренда dedicated сервера . Это отличный способ получить достаточно мощные ресурсы и нужное количество памяти.
Парсинг? Зачем он нужен?
Представьте себе, что вы , не , а крупный портал с множеством страниц. У Вас есть красивый дизайн, панель управления и возможно даже разделы, которые вы хотите видеть, но где взять информацию для наполнения сайта?
В интернете – где ж еще. Однако не все так просто.
Приведу в пример лишь 2 проблемы при наполнении сайта контентом:
-
Серьезный объём информации.
Если Вы хотите обойти конкурентов, хотите чтобы Ваш ресурс был популярен и успешен, Вам просто необходимо публиковать огромное количество информации на своем ресурсе. Сегодняшняя тенденция показывает, что контента нужно больше чем возможно заполнить вручную
.
-
Постоянные обновления.
Информацию которая все время меняется и которой как мы уже сказали большие объемы, невозможно обновлять вовремя и обслуживать. Некоторые типы информации меняются ежеминутно и обновлять её руками невозможно
и не имеет смысла.
И тут нам приходит на помощь старый добрый парсинг! Та-дааааам!
Это самое оптимальное решение, чтобы автоматизировать процесс изменения и сбора контента.
Чем парсинг круче работы человека:
-
быстро
изучит тысячи сайтов;
-
аккуратно
отделит нужную информацию от программного кода; -
безошибочно
выберет самые сливки и выкинет ненужное;
-
эффективно
сохранит конечный результат в нужном виде.
Как парсить сайты?
Тут я буду краток, скажу лишь, что для этого можно использовать практически любой язык программированию, который мы используем при разработке сайтов. Это и php, и C++, и python и т.д.
Поскольку наиболее распространенным среди веб-разработчиков является php, я собираюсь написать подробную инструкцию, как можно можно парсить сайты при помощи php или специальных сервисов.
Парсить – что это значит? Определение и цели
Гуглить давно уже стало привычкой
Причем совершенно неважно, какой поисковый механизм для этого использовать. Google – это идея, а как ее реализовать, вопрос второй
Какую бы поисковую машину ни использовал человек, в результате он стремится получить нужное решение быстро и правильно. В большинстве случаев достаточно полистать нужные книжки и найти информацию. Но всегда все хочется сделать быстрее и качественнее.
Классический парсинг информации
Читать книжки – парсить. Что это значит? Это когда человек просто понимает прочитанное и оценивает его относительно автора и издательства. Но это очень эффективный процесс, хотя длительный и трудоемкий.
Гораздо эффективнее использовать поисковые машины интернета: быстро и много информации. Есть выбор.
Однако поиск в интернете:
- не дает гарантии свежести результата;
- не дает гарантированного авторитета автора;
- без издательства, редактора или хотя бы одного цензора написанному.
Но поиск в интернете быстр и объемен – есть выбор. А если выборка велика, то обобщение результата дает необходимые гарантии.
Можно парсить на PHP и тогда автоматом можно оценить свежесть каждого элемента выборки, но редкая поисковая машина не проверяет посетителя на робота и в обязательном порядке потребует капчу или иным образом постарается подтвердить посещение человеком, а не роботом или пауком.
Интернет-парсинг
В интернете есть сайты и поисковые машины. Первые предоставляют информацию, вторые предлагают информацию, которую собрали сами, анализируя многочисленные сайты длительное время.
Найти нужные сайты не так легко для конкретной цели. Воспользоваться поисковыми машинами просто для человека, но не для задачи парсить PHP-скриптом, “интеллектуальным” AJAX-запросом или иным оригинальным образом.
Ответить на капчу не каждому PHP-скрипту возможно, потому вопрос о том, как парсить сайты, фактически означает: как создать собственную поисковую машину. Многие авторитетные поисковики не ограничиваются капчей для проверки того, кто обратился с запросом. Есть множество более простых способов обнаружить робота или паука. Результат выборки будет нежелательным для “искателя” информации.
Определение цели
Поиск информации – поиск сайтов или источников информации. Книжные издания и иные классические формы выражения знаний и опыта, подтвержденные авторитетными авторами, редакторами, издательствами, – это не парсинг, это длительный, убедительно верный процесс поиска нужной информации.
А в современном информационном мире парсить – что это значит? Эту задачу решает конкретный скрипт, написанный конкретным программистом для решения конкретной задачи. Постановщик задачи может и не предполагать, что и как делает этот скрипт. Но он всегда знает, что и как он хочет найти.
При любом положении вещей определение цели заказчика – задача исполнителя. Но вопрос даже не в том, насколько полно они поймут друг друга, вопрос в том, как сделать качественный парсинг.
Хорошая идея – поставить цель найти информацию свежую, точную и объективно достоверную. Отличная идея – определить достижение цели как правильное движение по тегам страниц. HTML – это реальная среда для представления информации, и она идеально точно позволяет различить нужную информацию от рекламного спама.
Парсить — что это обозначает простыми словами?
С появлением новых технологий в нашем обиходе появляются новые слова, значения которых многие не знают и не могут понять, что они означают. Много терминов приходит с других языков. В основном в последние десятилетия они приходят в русский язык из англоязычных стран. Одним из таких является слово «парсить«. Так что же это такое?
Определение
Термин «парсить» пришло в русский из английского языка и означает – разбирать, проводить анализ. Это слово употребляют в своей терминологии разработчики Интернет ресурсов, программисты и т. д. В их среде в большинстве случаев означает поиск и копирование чужого контента на свой сайт, а также процедура разбора, проведения анализа статьи. Ещё в информатике это означает – проведение анализа, при котором разрабатываются математические модели сравнения.
Также означает сбор информации в Интернете, используя для этого специально разработанные программы – «парсеры«, которые позволяют сравнивать предложенные сегменты в разработанной базе с теми, что есть в Интернете. Они часто используются аналитиками, экономистами и бизнесменами в разных сегментах экономики.
Для чего применяются
Сбор сведений для исследования рынка
Такая программный продукт может отследить необходимую информацию, что даст специалисту определить, в каком направлении будет развиваться та или иная компания или отрасль в целом, например, в ближайшие полгода. Таким образом, утилита даёт фундамент, базу специалисту для проведения глубокого анализа, что даст компании поднять свой уровень продаж в своём рыночном секторе услуг или производства.
Подобная утилита способна получать информацию от многих источников, которые специализируются на проведении аналитики и компаний по исследованию рынка. И только потом можно будет объединять все полученные сведения для сравнения и проведения глубокого анализа.
Отбор сотрудников или поиск работы
Для работодателя, который динамично разыскивает претендентов в интересах принятия на работу в свою фирму, либо для соискателя, который подыскивает себе работу с определённой должностью, подобная разработка также будет востребована. С её помощью проводится настройка и подборка исходных данных в базе разных применяемых фильтров и результативно извлекать нужное, без обыденного поиска вручную.
Получение сведений
- Так же их применяют, для того чтобы составлять и классифицировать информацию:
- почтовые или электронные адреса,
- контакты с разных веб-сайтов и соцсетей.
Это даёт возможность создавать простые списки контактов и целой сопутствующих данных в интересах бизнеса – о покупателях, посредниках либо изготовителях.
- Изучение стоимости товара в различных онлайн магазинах
- Такие ресурсы могут быть полезны и тем, кто оживлённо пользуется предложениями онлайн магазинов, следит за ценами на продукты питания, разыскивает товары на многих сайтах одновременно.
Самые известные парсеры
Самые крупные и известные системы, которые занимаются парсером – это, конечно же, Яндекс и Google. Их программы, когда юзер хочет что-то найти во Всемирной паутине и вводит в поисковик, что именно необходимо ему найти, начинают искать из десятков миллионов веб-ресурсов именно то, что нужно юзеру. Выдают ему несколько сотен сайтов на выбранную тему, из которых он ищет необходимую ему информацию.
А перечисленные выше возможности программ для того чтобы «парсить» являются более узкоспециализированными, и их программисты разрабатывают для различных крупных фирм, которые с их помощью определяют свои возможности и конкурентов. Всё это облегчает проведение необходимых мероприятий, так как происходит всё в автоматическом режиме, и специалист может получить всё нужное в виде таблиц или графиков, что упрощает его дальнейшую работу. Ему не нужно тратит драгоценное время на поиск.
Что представляет собой парсер
Если попытаться объяснить, что такое парсер, простыми словами, определение будет примерно таким – это ПО, выделяющее определенные части информации из массива данных. Алгоритм работы парсера может различаться в разных реализациях, но основной принцип остается неизменным.
- Программа сканирует данные, поступающие на вход, будь то текст, веб-страница или другой набор информации, и вычленяет из них некоторые элементы.
- Что именно будет выделять парсер из массива данных – зависит от конкретной задачи. Обычно программы можно настраивать таким образом, чтобы получать нужные результаты.
- Правила поиска чаще всего задаются регулярными выражениями – строками, составленными по определенным правилам и дающими программе пояснение, что и как искать.
- На основе собранной информации формируется отчет или таблица, в которой отражены все полученные результаты.
Этапы работы парсера условно можно разделить на три процесса: сканирование массива информации, выделение из него нужных данных в зависимости от заданного правила, составление отчета о найденных элементах.
Технические и этические проблемы
Парсеры могут создавать определенные технические сложности. В первую очередь, это связано с трафиком. Хотя парсер – это программа, каждое его подключение фиксируется и представляет некоторую нагрузку на сервер. При слишком частых подключениях эта нагрузка может оказаться чрезмерной, и сайт будет заблокирован.
Другая проблема парсинга носит этический характер. Это связано с тем, что данный процесс во многих случаях можно считать воровством контента. Границы между допустимым и недопустимым довольно расплывчаты.
Я не раз встречал в Интернете сайты, на которых опубликованы статьи, полностью скопированные с моих веб-ресурсов. И хотя там присутствует ссылка на первоисточник, это не очень приятно.
Итак, парсинг – это важный и необходимый процесс, применяющийся для разных целей, который облегчает жизнь многим пользователям Интернета по поиску и обработке огромных массивов информации.
Надеюсь, теперь вам понятны термины «парсинг», «парсить», что это значит, и для чего делается.

Виды парсинга
Парсить можно самые разные данные, и поэтому этот процесс можно разделить на несколько видов.
Анализ аудитории
Собираются при этом самые разнообразные данные, начиная с простых, как ФИО, пол, возраст, образование, местоположение, и заканчивая такими, кажется, неочевидными, как интересы, наклонности в какой-то области и многое другое.
Это необходимо для формирования модели потенциального клиента и разработки более точной и целенаправленной рекламы, что экономит бюджет рекламной кампании.
Парсинг сайтов
Парсить сайты можно для разных целей.
Чуть подробнее о сборе ключевых запросов для создания семантического ядра. Количество таких запросов исчисляется миллиардами и, конечно, без программной обработки здесь не обойтись. Для этих целей созданы как специальные программы, так и онлайн-сервисы.
К первым относится самая популярная среди сеошников программа Key Collector, с помощью которой можно парсить ключевые запросы, определять частотность, конкурентность, проводить кластеризацию запросов и т. д.
Среди онлайн-сервисов, которые используются для работы с ключевыми словами, я бы выделил Букварикс, о котором у меня уже есть статья, и сервис Мутаген, считающийся лучшим для определения конкурентности поисковых запросов.
Другое направление, где необходим парсинг сайтов – это их аудит. Например, я также писал о программе Smart Seo Auditor, с помощью которой можно выполнить SEO-аудит как своего, так и чужого сайта.
Утилита парсит сайт, находит заголовки страниц (title, h1-h6), описания (description), изображения с их характеристиками и многое другое, и результаты выдает в виде удобной таблицы.
С помощью парсинга наполняют контентом так называемые, автонаполняемые сайты. Например, для сайтов на WordPress разработаны специальные плагины-парсеры, которые регулярно обходят ресурсы из заданного списка и, в случае появления на них новых статей, сразу же копируют их к себе.
Для чего используют
Для чего копировать чужую информацию, если можно написать свою? Чтобы заработать много денег, следует создавать как можно больше вариантов контента Ваших рекламных объявлений с потенциально заинтересованными лицами. Если Вы сами будете кропотливо наполнять сайт уникальными статьями, то потеряете много времени и шанс заработать больше. Зачем придумывать велосипед, если можно спарсить уже готовый контент?
Что будет, если все начнут «слизывать» друг у друга контент? За безразборное копирование программы Яндекс может наказать Вас и Ваш сайт негативной позицией сайта при выдаче запросов. Также грозит черный список.

Поисковик
Прекрасно парсинг зарекомендовал себя среди таргетологов, которые занимаются сбором целевых аудиторий для настройки таргетированной рекламы на нее. Здесь можно реализовать творческие идеи – начиная о поиске горячей аудитории с сиюминутным желанием приобрести товар до людей, которые однажды интересовались или заходили на сайты, чтобы посмотреть цену. Вопрос настройки параметров для выявления целевой аудитории заключается лишь в том, насколько креативно специалист подходит к пониманию портрета своего потенциального клиента.

Парсинг для аудитории






