Погружение в свёрточные нейронные сети. часть 5 / 10
Содержание:
- Подготовка функций и переменных
- Обратное распространение
- GNN строят представления графов
- Виды ИНС
- Обучение представлений для NLP
- Softmax (функция мягкого максимума)
- Создание нейрона с нуля в Python
- Предложения — полные графы, слова — вершины
- Что такое нейрон смещения и для чего он нужен?
- Представляем функцию стоимости с перекрёстной энтропией
Подготовка функций и переменных
Библиотека NumPy широко используется для расчетов в нейросети, а библиотека Pandas дает мне удобный способ импортировать данные обучения из файла Excel.
Как вы уже знаете, для активации мы используем функцию логистической сигмоиды. Для расчета значений постактивации нам нужна сама логистическая функция, а для обратного распространения необходима производная логистической функции.
Затем мы выбираем скорость обучения, размерность входного слоя, размерность скрытого слоя и количество эпох
Для реальных нейронных сетей важно обучение в течение нескольких эпох, потому что это позволяет вам извлечь больше информации из ваших обучающих данных. Когда вы генерируете обучающие данные в Excel, вам не нужно запускать несколько эпох, потому что вы можете легко создать больше обучающих выборок
Функция заполняет наши две матрицы весов случайными значениями от –1 до +1 (обратите внимание, что матрица весов между скрытым и выходным слоями на самом деле представляет собой просто массив, поскольку у нас только один выходной узел). Оператор приводит к тому, что случайные значения становятся одинаковыми при каждом запуске программы
Начальные значения весов могут оказать существенное влияние на конечную производительность обученной сети, поэтому, если вы пытаетесь оценить, как другие переменные улучшают или ухудшают производительность, вы можете раскомментировать эту инструкцию и тем самым устранить влияние случайной инициализации весовых коэффициентов.
И в конце я создаю пустые массивы для значений преактивации и постактивации в скрытом слое.
Обратное распространение
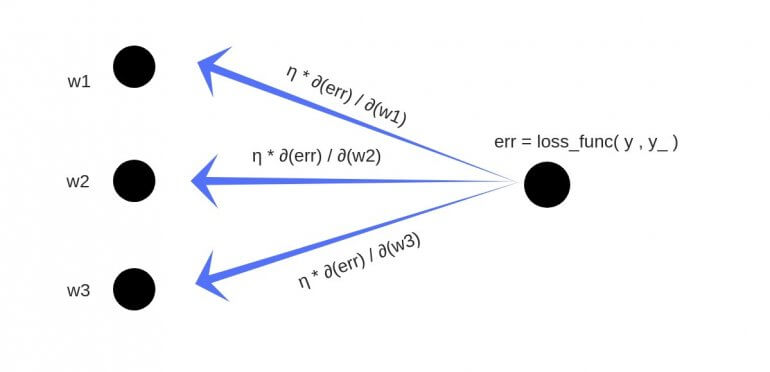
- Суммарная ошибка (total_error) вычисляется как разность между ожидаемым значением «y» (из обучающего набора) и полученным значением «y_» (посчитанное на этапе прямого распространения ошибки), проходящих через функцию потерь (cost function).
- Частная производная ошибки вычисляется по каждому весу (эти частные дифференциалы отражают вклад каждого веса в общую ошибку (total_loss)).
- Затем эти дифференциалы умножаются на число, называемое скорость обучения или learning rate (η).
Полученный результат затем вычитается из соответствующих весов.
В результате получатся следующие обновленные веса:
- w1 = w1 — (η * ∂(err) / ∂(w1))
- w2 = w2 — (η * ∂(err) / ∂(w2))
- w3 = w3 — (η * ∂(err) / ∂(w3))
То, что мы предполагаем и инициализируем веса случайным образом, и они будут давать точные ответы, звучит не вполне обоснованно, тем не менее, работает хорошо.
 Популярный мем о том, как Карлсон стал Data Science разработчиком
Популярный мем о том, как Карлсон стал Data Science разработчиком
 Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
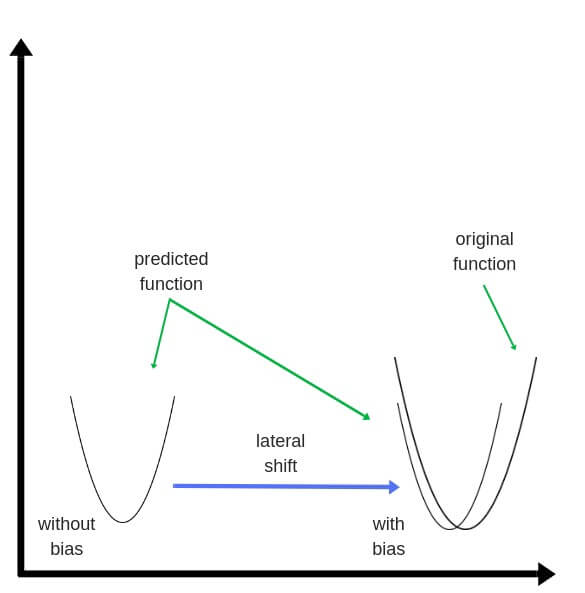
Смещения – это веса, добавленные к скрытым слоям. Они тоже случайным образом инициализируются и обновляются так же, как скрытый слой. Роль скрытого слоя заключается в том, чтобы определить форму базовой функции в данных, в то время как роль смещения – сдвинуть найденную функцию в сторону так, чтобы она частично совпала с исходной функцией.
GNN строят представления графов
Давайте на минуту отвлечёмся от NLP.
Графовые нейронные сети (GNN) или графовые свёрточные сети (GCN) строят представления вершин и рёбер на графовых данных. Делают это они с помощью агрегации значений соседей (или, иначе говоря, передачи сообщений). Каждая вершина собирает признаки соседних вершин, чтобы обновить собственное представление локальной структуры графа в её окрестности. Стекинг нескольких слоёв GNN позволяет модели распространять (propagate) признаки каждой вершины по всему графу — от соседей к соседям соседей — и так далее.
В самом простом виде GNN обновляют скрытые признаки вершин в слое путём нелинейного преобразования признаков самой вершины, добавленных к агрегации признаков с каждой из соседних вершин :
где — обучаемые матрицы весов слоя GNN, а — функция активации (как, например, ReLU). В примере —
Звучит знакомо, не так ли?
Если нет, пайплайн поможет установить связь:
Виды ИНС
Мы разобрались со структурой искусственного нейрона. Искусственные нейронные сети состоят из совокупности искусственных нейронов. Возникает логичный вопрос – а как располагать/соединять друг с другом эти самые искусственные нейроны?
Как правило, в большинстве нейронных сетей есть так называемый входной слой, который выполняет только одну задачу – распределение входных сигналов остальным нейронам. Нейроны этого слоя не производят никаких вычислений.
А дальше начинаются различия…
Однослойные нейронные сети
В однослойных нейронных сетях сигналы с входного слоя сразу подаются на выходной слой. Он производит необходимые вычисления, результаты которых сразу подаются на выходы.
Выглядит однослойная нейронная сеть следующим образом:
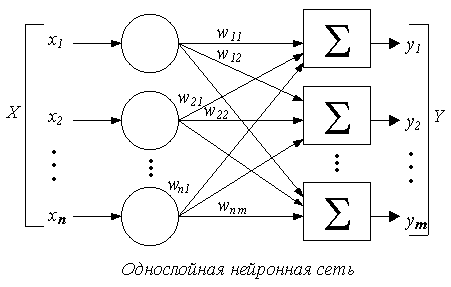
На этой картинке входной слой обозначен кружками (он не считается за слой нейронной сети), а справа расположен слой обычных нейронов.
Нейроны соединены друг с другом стрелками. Над стрелками расположены веса соответствующих связей (весовые коэффициенты).
Однослойная нейронная сеть (Single-layer neural network) — сеть, в которой сигналы от входного слоя сразу подаются на выходной слой, который и преобразует сигнал и сразу же выдает ответ.
Многослойные нейронные сети
Такие сети, помимо входного и выходного слоев нейронов, характеризуются еще и скрытым слоем (слоями). Понять их расположение просто – эти слои находятся между входным и выходным слоями.

Такая структура нейронных сетей копирует многослойную структуру определенных отделов мозга.
Название скрытый слой получил неслучайно. Дело в том, что только относительно недавно были разработаны методы обучения нейронов скрытого слоя. До этого обходились только однослойными нейросетями.
Многослойные нейронные сети обладают гораздо большими возможностями, чем однослойные.
Работу скрытых слоев нейронов можно сравнить с работой большого завода. Продукт (выходной сигнал) на заводе собирается по стадиям. После каждого станка получается какой-то промежуточный результат. Скрытые слои тоже преобразуют входные сигналы в некоторые промежуточные результаты.
Многослойная нейронная сеть (Multilayer neural network) — нейронная сеть, состоящая из входного, выходного и расположенного(ых) между ними одного (нескольких) скрытых слоев нейронов.
Сети прямого распространения
Можно заметить одну очень интересную деталь на картинках нейросетей в примерах выше.
Во всех примерах стрелки строго идут слева направо, то есть сигнал в таких сетях идет строго от входного слоя к выходному.
Сети прямого распространения (Feedforward neural network) (feedforward сети) — искусственные нейронные сети, в которых сигнал распространяется строго от входного слоя к выходному. В обратном направлении сигнал не распространяется.
Такие сети широко используются и вполне успешно решают определенный класс задач: прогнозирование, кластеризация и распознавание.
Однако никто не запрещает сигналу идти и в обратную сторону.
Сети с обратными связями
В сетях такого типа сигнал может идти и в обратную сторону. В чем преимущество?
Дело в том, что в сетях прямого распространения выход сети определяется входным сигналом и весовыми коэффициентами при искусственных нейронах.
А в сетях с обратными связями выходы нейронов могут возвращаться на входы. Это означает, что выход какого-нибудь нейрона определяется не только его весами и входным сигналом, но еще и предыдущими выходами (так как они снова вернулись на входы).
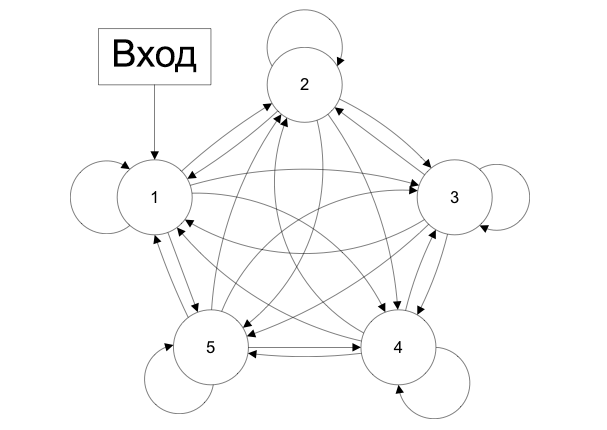
Возможность сигналов циркулировать в сети открывает новые, удивительные возможности нейронных сетей. С помощью таких сетей можно создавать нейросети, восстанавливающие или дополняющие сигналы. Другими словами такие нейросети имеют свойства кратковременной памяти (как у человека).
Сети с обратными связями (Recurrent neural network) — искусственные нейронные сети, в которых выход нейрона может вновь подаваться на его вход. В более общем случае это означает возможность распространения сигнала от выходов к входам.
Обучение представлений для NLP
Так или иначе все нейросетевые архитектуры строят представления входных данных в виде векторов, которые «кодируют» полезные статистические и семантические свойства этих данных. Эти латентные (скрытые) (latent/hidden) представления можно затем переиспользовать для какой-нибудь полезной задачи. Например, для классификации изображений или перевода предложений. Нейронные сети обучают представления всё лучше и лучше благодаря обратной связи, которую они обычно получают в виде значений функций потерь (error/loss functions).
Принято, что в обработке естественного языка (natural language processing; NLP), рекуррентные нейронные сети (recurrent neural networks; RNN) для каждого слова в предложении строят отдельное представление — шаг за шагом, по одному слову. Можно представить себе RNN как ленту конвейера, на которой слова обрабатываются авторегрессивно слева направо. В итоге на каждое слово в предложении получаем вектор скрытых представлений, которые мы либо передаём на следующий слой RNN, либо используем для нашей целевой задачи.
Softmax (функция мягкого максимума)
LjLj
L1L2L3L4оригинале статьиL4L4L4L4L4L4
L4LjLj
Упражнения
- Монотонность Softmax. Покажите, что ∂aLj / ∂zLk положительна, если j=k, и отрицательна, если j≠k. Как следствие, увеличение zLj гарантированно увеличивает соответствующую выходную активацию aLj, и уменьшает все остальные выходные активации. Мы уже видели это эмпирически на примере ползунков, однако данное доказательство будет строгим.
- Нелокальность Softmax. Приятной особенностью сигмоидных слоёв является то, что выход aLj — функция соответствующего взвешенного входа, aLj = σ(zLj). Поясните, почему с Softmax-слоем это не так: любая выходная активация aLj зависит от всех взвешенных входов.
Создание нейрона с нуля в Python
Приступим к имплементации нейрона. Для этого потребуется использовать NumPy. Это мощная вычислительная библиотека Python, которая задействует математические операции:
Python
import numpy as np
def sigmoid(x):
# Наша функция активации: f(x) = 1 / (1 + e^(-x))
return 1 / (1 + np.exp(-x))
class Neuron:
def __init__(self, weights, bias):
self.weights = weights
self.bias = bias
def feedforward(self, inputs):
# Вводные данные о весе, добавление смещения
# и последующее использование функции активации
total = np.dot(self.weights, inputs) + self.bias
return sigmoid(total)
weights = np.array() # w1 = 0, w2 = 1
bias = 4 # b = 4
n = Neuron(weights, bias)
x = np.array() # x1 = 2, x2 = 3
print(n.feedforward(x)) # 0.9990889488055994
|
1 |
importnumpy asnp defsigmoid(x) # Наша функция активации: f(x) = 1 / (1 + e^(-x)) return1(1+np.exp(-x)) classNeuron def__init__(self,weights,bias) self.weights=weights self.bias=bias deffeedforward(self,inputs) # Вводные данные о весе, добавление смещения # и последующее использование функции активации total=np.dot(self.weights,inputs)+self.bias returnsigmoid(total) weights=np.array(,1)# w1 = 0, w2 = 1 bias=4# b = 4 n=Neuron(weights,bias) x=np.array(2,3)# x1 = 2, x2 = 3 print(n.feedforward(x))# 0.9990889488055994 |
Узнаете числа? Это тот же пример, который рассматривался ранее. Ответ полученный на этот раз также равен .
Предложения — полные графы, слова — вершины
Чтобы аналогия была более явной, представьте, что предложение — это полный граф, где каждое слово связано с каждым. Теперь можем использовать GNN, чтобы для каждой вершины (т.е. слова) графа (т.е. предложения) построить признаки, с помощью которых далее будем решать задачи обработки языка.
В целом, Трансформеры и представляют собой GNN с многоголовым вниманием в качестве функции агрегации соседей. Стандартные графовые сети агрегируют признаки вершин — непосредственных соседей , а трансформеры для NLP работают со всем предложением как с соседями, агрегируя признаки каждого слова на каждом слое
Важно, что каждая из всевозможных хитростей, специально придуманных под задачу, вроде позиционного кодирования, агрегации с масками, расписания скорости обучения и массированного предобучения, — необходимая составляющая успеха трансформеров. При этом эти трюки редко встречаются в работах GNN-сообщества
В то же время, если посмотреть на трансформеры глазами специалиста по GNN, мы сможем избавиться от разных свистелок и излишеств в архитектуре.
Что такое нейрон смещения и для чего он нужен?
В нейронных сетях есть ещё один вид нейронов — нейрон смещения. Он отличается от основного вида нейронов тем, что его вход и выход в любом случае равняется единице. При этом входных синапсов такие нейроны не имеют.
Расположение таких нейронов происходит по одному на слой и не более, также они не могут соединяться синапсами друг с другом. Размещать такие нейроны на выходном слое не целесообразно.
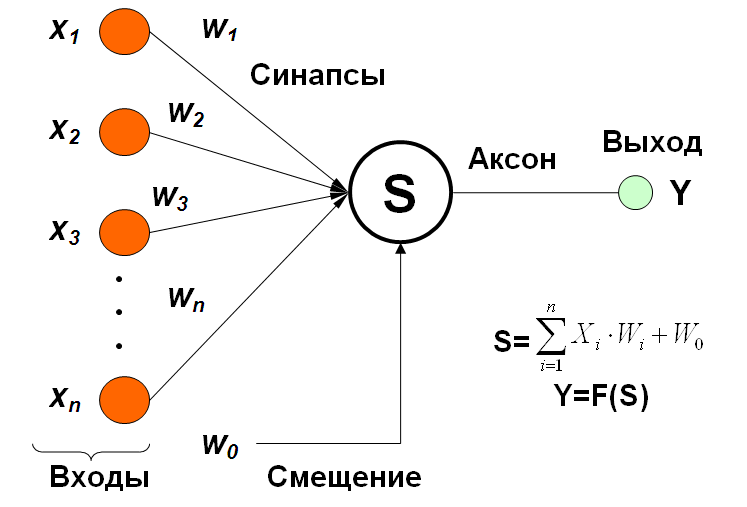 Для чего они нужны? Бывают ситуации, в которых нейросеть просто не сможет найти верное решение из-за того, что нужная точка будет находиться вне пределов досягаемости. Именно для этого и нужны такие нейроны, чтобы иметь возможность сместить область определения.
Для чего они нужны? Бывают ситуации, в которых нейросеть просто не сможет найти верное решение из-за того, что нужная точка будет находиться вне пределов досягаемости. Именно для этого и нужны такие нейроны, чтобы иметь возможность сместить область определения.
То есть вес синапса меняет изгиб графика функции, тогда как нейрон смещения позволяет осуществить сдвиг по оси координат Х, таким образом, чтобы нейросеть смогла захватить область недоступную ей без сдвига. При этом сдвиг может быть осуществлён как вправо, так и влево. Схематически нейроны сдвига обычно не обозначаются, их вес учитывается по умолчанию при расчёте входного значения.
Также нейроны смещения позволят получить результат в том случае, когда все остальные нейроны выдают 0 в качестве выходного параметра. В этом случае независимо от веса синапса на каждый следующий слой будет передаваться именно это значение.
Наличие нейрона смещения позволит исправить ситуацию и получить иной результат. Целесообразность использования нейронов смещения определяется путём тестирования сети с ними и без них и сравнения результатов.
Но важно помнить, что для достижения результатов мало создать нейронную сеть. Её нужно ещё и обучить, что тоже требует особых подходов и имеет свои алгоритмы
Этот процесс сложно назвать простым, так как его реализация требует определённых знаний и усилий.
Представляем функцию стоимости с перекрёстной энтропией
1212jjj
−z
интерактивная формапосмотримраньше нейрон застревал12L1L2
jjjjLjjjj
Упражнения
- Один подвох перекрёстной энтропии состоит в том, что сначала может быть трудно запомнить соответствующие роли y и a. Легко запутаться, как будет правильно, − или −. Что будет со вторым выражением, когда y=0 или 1? Влияет ли эта проблема на первое выражение? Почему?
- В обсуждении единственного нейрона в начале раздела, я говорил, что перекрёстная энтропия мала, если σ(z)≈y для всех обучающих входящих данных. Аргумент основывался на том, что y равен 0 или 1. Обычно в задачах классификации так и есть, но в других задачах (например, регрессии) y иногда может принмать значения между 0 и 1. Покажите, что перекрёстная энтропия всё равно минимизируется, когда σ(z)=y для всех обучающих входов. Когда так происходит, значение перекрёстной энтропии равно
. Величину − иногда называют бинарной энтропией.
Задачи
- Многослойные сети с многими нейронами. В записи из последнего раздела покажите, что для квадратичной стоимости частная производная по весам в выходном слое равна
Член σ'(zLj) заставляет обучение замедляться, когда нейрон склоняется к неверному значению. Покажите, что для функции стоимости с перекрёстной энтропией выходная ошибка δL для одного обучающего примера x задаётся уравнением
Используйте это выражение, чтобы показать, что частная производная по весам в выходном слое задаётся уравнением
Член σ'(zLj) исчез, поэтому перекрёстная энтропия избегает проблемы замедления обучения, не только при использовании с одним нейроном, но и в сетях с многими слоями и многими нейронами. С небольшим изменением этот анализ подходит и для смещений. Если это неочевидно для вас, вам лучше проделать и этот анализ также. - Использование квадратичной стоимости с линейными нейронами во внешнем слое. Допустим, у нас многослойная сеть с многими нейронами. Допустим, в финальном слое все нейроны линейные, то есть сигмоидная функция активации не применяется, а их выход просто определяется, как aLj = zLj. Покажите, что при использовании квадратичной функции стоимости выходная ошибка δL для одного обучающего примера x задаётся
Как и в прошлой задаче, используйте это выражение, чтобы показать, что частные производные по весам и смещениям во внешнем слое определяются, какЭто показывает, что если выходные нейроны линейные, тогда квадратичная стоимость не вызовет никаких проблем с замедлением обучения. В этом случае квадратичная стоимость вполне подходит для использования.






