Тестирование микросервисов: разумный подход
Содержание:
Введение
Mod_rewrite – достаточно мощный инструмент для URL-преобразований «на лету». Этот замечательный модуль веб-сервера Apache предоставляет поистине безграничные возможности. На данный момент модуль чаще всего применяется для:
- поисковой оптимизации (SEO);
- защиты от прямых загрузок, так как скрывается реальное местоположение файла;
- сокрытия иерархии поступающих параметров, каталогов и сценариев веб-приложения путем их централизованного динамического преобразования;
- разграничения доступа: mod_rewrite может проверять значения HTTP-заголовков, в том числе значение COOKIE на соответствие правилам и по результатам проверок проводить (или не проводить) перенаправление.
Чаще всего корректно настроенный mod_rewrite затрудняет возможности поиска и эксплуатации уязвимостей веб-приложения. Это происходит по следующим причинам:
1. Трудно распознать реальное предназначение элемента URL. Например, если мы видим ссылку вида , невозможно понять, какой из элементов URL является относительным путем от корневого каталога веб-сервера; что является названием сценария, а что является параметром этого сценария. Это сильно затрудняет анализ структуры веб-приложения. Например, следующие правила позволят одной и той же ссылке соответствовать различным реальным представлениям структуры веб-приложения:
При таком правиле ссылка соответствует сценарию search.php, который располагается в папке /main/ относительно корневого каталога веб-сервера, вызванному с параметром search=stroka_poiska
По данному правилу та же самая ссылка соответствует сценарию script.php, который находится в папке main и вызван с параметрами
А по этому правилу такая же ссылка соответствует сценарию main.php, который находится в корневом каталоге веб-сервера и вызван с параметрами
Кроме того, благодаря гибкости используемых mod_rewrite регулярных выражений, даже схожие по виду URL-адреса могут обращаться к абсолютно разным сценариям.
Например, данные правила:
отправят 2 схожих запроса разным сценариям:
2. Трудно определить язык программирования, на котором написано приложение. За ссылкой может находиться как серверный сценарий на языке PHP, ASP или Perl, так и статическая страница на языке HTML;
3. Наличие регулярных выражений, которые можно использовать в правилах перезаписи mod_rewrite, позволяет фильтровать входные параметры (далее будет рассмотрен пример);
4. При автоматизации поиска уязвимостей необходимо заменять некоторые символы (например, слеш («/») на %2F (hexadecimal encoding) или %252F (double encoding)), так как они обрабатываются еще на стадии «разбора» URL-адреса в mod_rewrite.
В связи с этим многие разработчики и администраторы предпочитают «маскировать» наличие уязвимостей с помощью mod_rewrite, а не обнаруживать и исправлять проблемы. Но такой подход, как и любой метод, основанный на подходе Security Through Obscurity, работает весьма плохо.
Что такое фаззинг?
В зависимости от того, где осуществляется манипуляции с данными, фаззинг
разделяется на множество категорий. Один из самых простых видов — файловыйфаззинг, подразумевающий, что некой программе предлагается открыть некорректно
составленный файл. Возьмем, к примеру, прогу для просмотра картинок. Если взять
JPEG-файл и интересным образом поменять несколько байтов, то эта программа
вполне возможно выругается: «Что это ты мне подсунул?». А, возможно, вообще не
сможет его переварить и вылетит, к примеру, с проблемой переполнения
буфера. Значит, ее теоретически можно расковырять, доведя дело до рабочего
эксплойта.
Если говорить о способе манипуляции с данными, то фаззинг распределяется на
генерацию и мутацию. Генерация — это случайным образом придуманный набор байтов,
который подсовывается той же проге для просмотра картинок со словами: «Это на
самом деле JPEG-файл, читай его». Мутация — прием намного более изящный,
подразумевающий внесение изменений в «хороший», то есть вполне корректный файл.
Если в случае с файловым фаззингом еще можно использовать «генерацию», то в
таких вещах, как сетевые протоколы, имеет смысл применять исключительно подход
мутации. Более того, крайне желательно иметь представление, за что отвечает то
или иное поле пакета и намеренно манипулировать с теми данными, которые могут
быть некорректно обработаны. В зависимости от интеллекта, фаззеры бывают глупые
и умные:
-
Глупый (dump) фаззер ничего не знает о структуре файлов. Если говорить о
сетевых протоколах, то единственное, что он может сделать — это изменить
несколько байтов в исходном пакете и отправить его в надежде, что это может
вызвать сбой. -
Умный (smart) фаззер имеет некоторое представленные о структуре данных.
Вместо того, чтобы полностью надеяться на удачу, он может играться только с
теми данными, которые отвечают, например, за размер буфера. Или подставлять
в поля такие значения, которые заведомо, с учетом известного формата, будут
некорректными.
Санитайзеры
Прежде чем мы перейдем к основной теме статьи, следует немного рассказать о санитайзерах. Это инструменты для динамического тестирования, помогающие в поиске самых разных ошибок в программах. Переполнение буферов (глобальных, на стеке или в куче), использование после освобождения, утечки памяти, обращение к неинициализированным переменным — все это повод для использования санитайзеров.
Однако работой с памятью их возможности не ограничиваются. Они также позволяют обнаруживать состояние гонки для потоков, ситуации взаимной блокировки, обращения по нулевому указателю, деление на ноль (куда же без него), переполнения для типов данных и некорректные битовые сдвиги — одним словом, солидную часть ошибок, которые вызывают неопределенное поведение в программах.
Санитайзеры очень помогают во время отладки. Для их использования достаточно скомпилировать исходники с включенной инструментацией, которая добавит специальные команды в исполняемый файл. По ним можно будет следить за ходом выполнения программы и состоянием памяти. При обнаружении ошибок будет сгенерирован отладочный вывод и программа завершит работу.
Сегодня работу с санитайзерами поддерживают компиляторы GCC и Clang
Настоятельно рекомендую обратить на них внимание. Мало просто сгенерировать фаззером некорректные входные данные, которые обрушат программу
Ошибку следует устранить, а для этого надо собрать максимум информации. Именно в этом и помогают санитайзеры. Их совместное использование повышает эффективность тестирования. Так что в некотором смысле фаззеры и санитайзеры созданы друг для друга.
Фаззер MiniFuzz
Начнем с фаззера под названием MiniFuzz. Он разработан в компании Microsoft и достаточно дружелюбен по отношению к пользователю (да, тут даже есть графический интерфейс!). Также доступна интеграция с Visual Studio.
Автоматизация поиска уязвимостей. Фаззер MiniFuzz
Разработчики рекомендуют делать не менее 100 000 файлов на каждый файловый формат. При этом каждый поданный на вход файл — это отдельная итерация фаззинга. Следовательно, требуется набор эталонных файлов. Например, если вы решили протестировать поведение приложения в ходе обработки архивов *.zip, в папку шаблонов вам необходимо будет сложить около ста таких файлов-образцов. Можно положить и больше, фаззер будет только рад! А вот если положить меньше, то эффективность процесса заметно упадет.
Далее фаззер случайным образом выбирает файл из эталонного набора и изменяет его, посылая в подопытное приложение. Если при этом возникает обрушение, файл записывается в папку crashes, где его потом можно будет подробно изучить и выяснить, что именно вызвало сбой.
Все настройки фаззера хранятся в файле minifuzz.cfg в формате XML. Немного пробежимся по самым интересным опциям (очевидные я опустил для краткости).
- Command line args — в этом поле можно добавить недостающие параметры командной строки, если эти данные нужны во время фаззинга.
- Allow process to run for — определяет время работы экземпляра тестируемого приложения. Не следует устанавливать маленькое значение, ведь тогда фаззер может не успеть отработать.
- Shutdown method — метод завершения запущенного экземпляра тестового приложения. Поддерживаются методы ExitProcess (завершает процесс корректно), WM_CLOSE (корректное завершение для оконных приложений) и TerminateProcess (завершает процесс аварийно).
- Aggressiveness — параметр определяет, насколько сильно будут искажаться образцы файлов перед тем, как попадут в приложение. Если вы безуспешно ждете результата уже долгое время, стоит подумать над увеличением этого значения.
А как же веб-фаззеры?
Я намеренно не стал упоминать в рамках этой статьи так
называемые web-based фаззеры, которые работают на уровне HTTP и заваливают
веб-сервер специально составленными запросами в поиске ошибок веб-приложения.
Такая опция есть в каждом втором сканере веб-безопасности, которые мы не так
давно рассматривали в рамках цикла «Инструменты
пентестера». Если говорить об универсальных платформах для создания фаззеров,
то грех не вспомнить о фреймворкеSulley,
представленном на Blackhat’е в 2007 году. К сожалению, с тех самых пор он и не
развивается, но несмотря на это остается эффективным решением.
Каждый отдельный фаззер с его помощью конструируется отдельно,
но в отличие от Peach, где все описывается декларативно в XML-файле, здесь тебе
придется написать немного кода на Python. Есть еще один популярный конструктор
фаззеров — проект
SPIKE, но подружиться с ним смогут только те, кто хорошо знает язык C.
Помимо этого можно было долго говорить о фаззерах для поиска уязвимостей в
ActiveX, COM-объектах и где угодно еще. Но это не главное
Важно понять, что во
многих местах поиск уязвимостей можно автоматизировать: именно с помощью
фаззинга находится большое количество багов в современных браузерах и смежных с
ними продуктов. А если есть понимание того, где может быть выявлена ошибка и как
ее искать, то фаззер уже несложно написать самому или подобрать готовое решение
Attack types
A fuzzer would try combinations of attacks on:
numbers (signed/unsigned integers/float…)
chars (urls, command-line inputs)
metadata : user-input text (id3 tag)
pure binary sequences
A common approach to fuzzing is to define lists of
“known-to-be-dangerous values” (fuzz vectors) for each type, and to
inject them or recombinations.
for integers: zero, possibly negative or very big numbers
for chars: escaped, interpretable characters / instructions (ex: For
SQL Requests, quotes / commands…)
for binary: random ones
Please refer to OWASP’s Fuzz Vector’s
resource for
real-life fuzzing vectors examples and methodology.
Protocols and file formats imply norms, which are sometimes blurry, very
complicated or badly implemented : that’s why developers sometimes mess
up in the implementation process (because of time/cost constraints).
That’s why it can be interesting to take the opposite approach: take a
norm, look at all mandatory features and constraints, and try all of
them; forbidden/reserved values, linked parameters, field sizes. That
would be conformance testing oriented fuzzing.
Фаззим файлы
Одна из простейших утилит для реализации глупого фаззинга —
MiniFuzz. Проект разработан внутри Microsoft для тестирования своих
собственных проектов. Дело в том, что использование фаззеров является
обязательным этапом методологии SDL (Security
Development Lifecycle), принятой в Microsoft для разработчиков безопасного
кода, включающей помимо прочего обильное fuzz-тестирование. Minifuzz можно
натравить на любое приложение; главное, чтобы в качестве параметра для запуска
оно воспринимало указание на файл, который ему необходимо открыть (скажем,
winword.exe test_sample.doc). Для начала работы необходимо набрать несколько
образцов «правильных» файлов и положить их каталог, обозначенный как Template
files, а также выбрать приложение для проверки, указав формат параметров для его
запуска. Когда ты нажмешь на кнопку Start Fuzzing, программа возьмет один из
образцов, изменит некоторые байты внутри него (количество изменяемых данных
зависит от параметра Aggressiveness) и скормит его исследуемому приложению. Если
тестируемая программа не вылетит через некоторый таймаут (по умолчанию 2
секунды), значит, тест пройден успешно.
Приложение будет закрыто, и начнется следующая итерация
проверки. Если же во время тестирования программа вылетит (бинго!), то для
анализа у тебя будет, во-первых, файл-образец, который вызвал сбой при открытии,
а, во-вторых, crash-файл с дампом программы. Для большего удобства Minifuzz
легко прикручивается в Visual Studio, позволяя запускать fuzz-тестирование прямо
из среды разработки через меню «Tools -> MiniFuzz». Впрочем, если по каким-то
причинам MiniFuzz тебе не подойдет, то можно попробовать другой инструмент для
dumb-фаззинга —FileFuzz,
который разработан не Microsoft, а известной security-командой iDefense Labs.
Типы фаззеров
С техниками фаззинга более-менее разобрались, теперь перейдем к типам фаззеров.
Форматы файлов
Будем считать входными данными пользователя любой файл любого формата, который наше тестируемое приложение возьмется обработать. Это значит, что мы можем подсунуть файл «неправильного» формата и посмотреть, как справится с ним подопытная программа. Первое, что приходит в голову, — антивирус. Антивирусный сканер должен определять формат файла, как-то с ним взаимодействовать: пытаться распаковать, включить эвристический анализ и так далее.
Чем обернется простая проверка, если антивирусный сканер решит, что перед ним файл PE, упакованный UPX, а при распаковке выяснится, что это вовсе не UPX, а что-то, что лишь притворяется им? Естественно, алгоритм распаковки будет другой, но поведение сканера при этом предугадать сложно. Может быть, он обрушится. Может быть, просто повесит на файл флаг «поврежден» и пропустит. И это далеко не полный перечень возможных исходов. Фаззеры форматов файлов помогут протестировать подобные вещи.
Аргументы командной строки и переменные окружения
Зачастую утилитам требуются параметры командной строки: это может быть путь файла, аргумент выполнения, да много чего еще. Но что, если передать на вход нечто, чего программа совсем не ждет? Как самое простое, если программа просит указать какой-то путь, то вряд ли она всерьез рассчитывает, что путь будет состоять из тысячи символов. Вполне возможно, что передача такого аргумента «неподготовленному» приложению переполнит стек и вызовет обрушение.
Сказанное выше в равной степени относится и к переменным окружения. По сути, это почти то же самое, что и фаззеры командной строки, только на вход берутся параметры не из аргументов, а из одной или нескольких переменных среды окружения. А дальше сценарий приблизительно такой же, как и в случае переполнения большим аргументом командной строки.
Запросы IOCTL
Достаточно полезная штука, когда нужно посмотреть, как реагируют на запросы IOCTL различные драйверы режима ядра. Помимо устройств и периферии, драйверами зачастую пользуются некоторые программы для взаимодействия с системой. Конечно, структура IRP-запроса почти всегда неизвестна, но перехваченные пакеты можно использовать в качестве основы для корпуса.
Сетевые протоколы
Такие фаззеры бывают заточены под известные протоколы, но есть и всеядные экземпляры. Например, фаззер OWASP JBroFuzz тестирует реализации известных протоколов на предмет наличия таких уязвимостей, как межсайтовый скриптинг, переполнение буферов, SQL-инъекции и многое другое. С другой стороны, есть утилита SPIKE, которая может протестировать незнакомые протоколы на многие уязвимости.
Браузерные движки
Да, даже для поиска дыр в браузерах есть специальные фаззеры. На сегодняшний день современные браузеры очень сложны и содержат множество движков: они обрабатывают различные версии документов, протоколов, CSS, COM, DOM и многое другое. Так что участники различных bug bounty ищут дыры не только голыми руками.
Оперативная память
В эту категорию входят достаточно узкоспециализированные фаззеры, используемые для модификации данных программ в оперативной памяти. Бывают полезными при тестировании каких-либо динамических антидампов и утилит со встроенной защитой.
Продолжение доступно только участникам
Вариант 1. Присоединись к сообществу «Xakep.ru», чтобы читать все материалы на сайте
Членство в сообществе в течение указанного срока откроет тебе доступ ко ВСЕМ материалам «Хакера», увеличит личную накопительную скидку и позволит накапливать профессиональный рейтинг Xakep Score!
Подробнее
Вариант 2. Открой один материал
Заинтересовала статья, но нет возможности стать членом клуба «Xakep.ru»? Тогда этот вариант для тебя!
Обрати внимание: этот способ подходит только для статей, опубликованных более двух месяцев назад.
Я уже участник «Xakep.ru»
Fuzz me baby one more time!
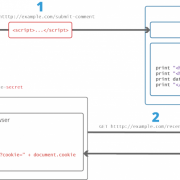
В 138 выпуске нашего любимого журнала (август 2010 года) Step написал статью про фаззинг и ПО, с помощью которого можно этот самый фаззинг осуществлять. Напомню, что этим модным термином принято называть метод тестирования ПО, при котором входные данные (данные могут быть в файле, в сетевом пакете) формируются специально-случайным образом, то есть, фактически, стресс-тест. Если в результате обработки таких данных произошла ошибка, и процесс аварийно завершил свою работу, то можно говорить о том, что процесс фаззинга нашел «что-то».
Дальше это «что-то» анализирует человек и делает вывод о том, что найденное состояние процесса при данном наборе входных данных можно использовать со злым умыслом, то есть исполнить произвольный код. Сами данные могут генерироваться по известному формату, то есть если нам известна спецификация формата, мы можем заранее подготовить кучу входных данных, которые соответствуют формату (структура файла, сетевой протокол на транспортном уровне), но содержат «случайные значения». Например, нам известно, что в какой-то части формата данных идет длина, под которую выделено два байта, а затем содержимое указанной длины:
Зная этот формат, можно сгенерировать множество вариантов:
И, возможно, программа, обрабатывающая эти данные, упадет при обработке первого набора… Дальнейший анализ покажет, что причина падения кроется из-за целочисленного переполнения (0xFFFF это у нас «-1») с последующим переполнением буфера в стеке с помощью функции memcpy, что является настоящей уязвимостью, а не просто досадной ошибкой.
Если формат неизвестен или слишком сложен (или просто лень), то можно использовать мутационные алгоритмы для изменения существующих правильных наборов данных. На том же примере:
Мутирует в:
Последняя мутация по тем же причинам вызовет переполнение буфера в стеке (0xFF00 — «-256» или «65280» без знака), если после этого будут еще какие либо данные достаточной длины.
Examples of Fuzzers
-
Mutation-Based Fuzzers alter existing data samples to create new test data. This is the very simple and straightforward approach, this starts with valid samples of protocol and keeps mangling every byte or file.
-
Generation-Based Fuzzers define new data based on the input of the model. It starts generating input from the scratch based on the specification.
-
PROTOCOL-BASED-fuzzer, the most successful fuzzer is to have detailed knowledge of protocol format being tested. The understanding depends on the specification. It involves writing an array of the specification into the tool then by using model-based test generation technique go through the specification and add irregularity in the data contents, sequence, etc. This is also known as syntax testing, grammar testing, robustness testing, etc. Fuzzer can generate test cases from an existing one, or they can use valid or invalid inputs.
There are two limitations of protocol-based fuzzing:
- Testing cannot proceed until the specification is mature.
- Many useful protocols are an extension of published protocols. If fuzz testing is based on published specifications, Test coverage for new protocols will be limited.
The simplest form of fuzzing technique is sending random input to the software either as protocol packets or as an event. This technique of passing random input is very powerful to find bugs in many applications and services. Other techniques are also available, and it is very easy to implement. To implement these techniques we just need to change the existing inputs. We can change input just by interchanging the bits of input.
Техники фаззинга
Существуют две основные техники фаззинга — это мутационное и порождающее тестирования. При мутационном тестировании генерация последовательностей происходит на основе заранее определенных данных и шаблонов. Именно они составляют стартовый корпус фаззера. Изменяя байт за байтом значения на входе и проверяя работу программы, фаззер может делать выводы об успешности тех или иных «мутаций», чтобы в следующем раунде сгенерировать более эффективные последовательности.
Как видите, сама концепция достаточно простая. Но за счет того, что количество итераций достигает сотен и тысяч миллионов (время тестирования при этом составляет несколько суток даже на мощных машинах), фаззеры находят в программах самые нетривиальные ошибки.
В свою очередь, порождающее тестирование — это более продвинутая техника фаззинга, которая предполагает построение грамматик входных данных, основанное на спецификациях. Это могут быть как файлы различных форматов, так и сетевые пакеты в протоколах обмена. В данном случае наши результаты должны соответствовать заранее определенным правилам. Порождающее тестирование сложнее мутационного в реализации, но и вероятность успеха здесь гораздо выше.
Разумеется, существуют и более продвинутые техники. Например, фаззинг с использованием трассировки и построением уравнений для SMT-решателей. В теории это помогает покрывать даже труднодоступные ветки кода. При этом включается трасса внутри ядра ОС, с одновременным исключением известных участков (нет никакого смысла фаззить внутренности функций WinAPI и прочего). Однако заставить все правильно работать непросто, и сегодня это скорее «черная магия», чем распространенная практика.
Вместе с тем есть и совсем простое тестирование с отправкой на вход абсолютно случайных значений, но я не рассматриваю его из-за очень низкой эффективности. По своему подходу оно больше похоже на перебор «грубой силой», так как история и успешность предыдущих попыток здесь никак не учитываются.
Одним из первых прототипов фаззеров считается программа The Monkey, созданная в далеком 1983 году. В названии очевидна отсылка к теореме о бесконечных обезьянах, которые пытаются напечатать «Войну и мир». Несмотря на свою практическую бесполезность, теорема популярна в массовой культуре (например, упоминается в романе «Автостопом по галактике» и сериале «Симпсоны») и даже получила собственный RFC 2795.
История
Случайные данные применялись при тестировании приложений и раньше. К примеру, приложение «Обезьяна» (англ. The Monkey) под Mac OS, созданное Стивом Капсом ещё в 1983 году, генерировала случайные события, которые направлялись на вход тестируемым программам для поиска багов. Оно использовалось, в частности, при тестировании .
Термин «fuzz» появился в 1988 году на семинаре Бартона Миллера в Университете Висконсина, во время которого была создана простая программа fuzzer, предназначенная для командной строки, с целью тестирования надежности приложений под Unix. Оно генерировало случайные данные, которые передавались как параметры для других программ до тех пор, пока они не останавливались с ошибкой. Это стало не только первым в истории тестированием с использованием случайных неструктурированных данных, но и первым специализированным приложением для тестирования широкого круга программ под разнообразные операционные системы, и с систематическим анализом типов ошибок, возникающих при таком тестировании. Создатели проекта открыли исходные коды своего приложения, а также публичный доступ к процедурам тестирования и сырым результатам. Тест был повторен в 1995 году — приложение доработали для тестирования приложений с GUI, сетевых протоколов и системных библиотек под Mac OS и Windows.
Стоит отметить, что схожие техники тестирования существовали задолго до появления термина и формализации процедуры. Так, известно, что Джерри Вейнберг использовал набор карт со случайными числами, чтобы передавать их на вход программ ещё в 1950-х годах.
В 1991 году было выпущено приложение crashme, созданное для тестирования надежности программ под Unix и Unix-подобные операционные системы путем исполнения случайного набора процессорных инструкций.
В настоящее время фаззинг-тестирование является составной частью большинства проверок безопасности и надёжности программного обеспечения и компьютерных систем.
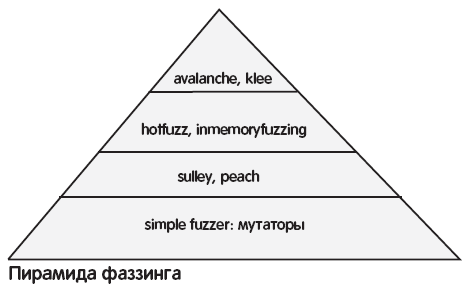
Sulley и peach
Это очень мощные фаззеры с возможностью описывать протокол для фаззинга. Например, для фаззинга FTP нужен конфиг в 329 строчек, из которых большая часть – описание самого протокола. Для более сложных протоколов конфиг будет огромным, и его составление будет очень трудоемким. Очень актуальное решение предлагает проект hotfuzz (hotfuzz.atteq.com).
Схема его работы на первый взгляд громоздкая, но на самом деле очень простая.
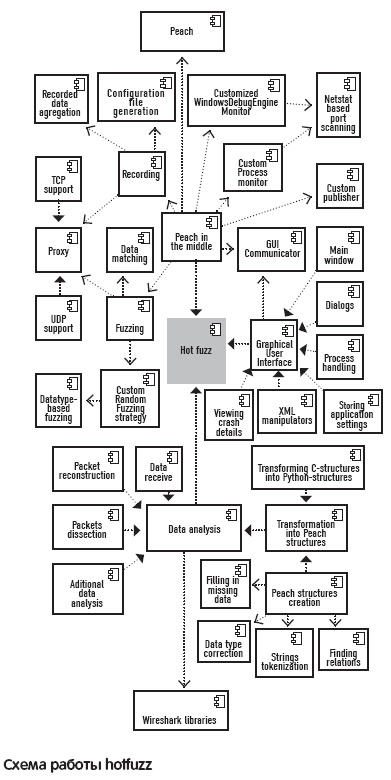
Hotfuzz основан на peach и является его оберткой. Устанавливается без проблем – все модули идут в одном пакете. Его главная особенность состоит в том, что описание протокола, который нужно фаззить, делается не вручную, составляя конфигурационный файл, а с использованием специальной библиотеки tm_export, основанной на tshark (одной из составляющих частей сниффера wireshark). Эта библиотека, используя дамп трафика, формирует дерево – структуру, описывающую протокол. И нам необходимо лишь выбрать поля, которые мы хотим фаззить, и… все! Это существенно упрощает работу – не нужно тратить много времени на составление конфигурационного файла, как это делалось при эксплуатации peach (демонстрационное видео смотри на DVD).
Comparison with cryptanalysis
The number of possible tryable solutions is the explorable solutions
space. The aim of cryptanalysis is to reduce this space, which means
finding a way of having less keys to try than pure bruteforce to decrypt
something.
Most of the fuzzers are:
protocol/file-format dependant
data-type dependant
Why?
First, because the fuzzer has to connect to the input channel, which
is bound to the target.
Second, because a program only understands structured-enough data.
If you connect to a web server in a raw way, it will only respond to
listed commands such as GET (or eventually crash). It will take less
time to start the string with “GET “, and fuzz the rest, but the
drawback is that you’ll skip all the tests on the first verb.
In this regard, Fuzzers try to reduce the number of unuseful tests, i.e.
the values we already know that there’s little chance they’ll work: you
reduce unpredictability, in favor of speed.
Part 1: fuzz discover
On the discovery side, your fuzzer will need to discover as many potential inputs to the system as possible. It will need to do the following:
-
Page discovery. The fuzzer must crawl and guess pages.
-
Page Guessing.
The fuzzer should use the common word list to discover potentially unlinked pages. Attempt every combination of word and
extension, (e.g. admin.php, admin.jsp). The list of words and extensions are in text files referred to in your command
line arguments. Your guessing may limit itself to the root of the given URL, you do NOT need to guess on every existing
page (although a real fuzzer should!). For example, if the given url was , and your
word list has and then your fuzzer should guess
and (and you do NOT need to construct other permutations like
or ). -
Page discovery.
Starting from the initial URL given, and from any page guessed, the fuzzer should discover pages on the site by finding
links and visiting them (i.e. «crawling»). Keep a list of URLs that your fuzzer confirms exist. Do not follow any links off-site
in your crawl. Do not go into an infinite loop. Beware of logout links: you may amend your custom auth feature to be aware of what DVWA’s logout page is and skip crawling it.
-
Page Guessing.
-
Input discovery. Given a page, the fuzzer should attempt to discover every possible input into the system.
-
Parse URLs. The fuzzer should be able to take a URL
and parse it down to manipulate its input and recognize which page
a URL goes to. For example,
is the same page as ,
and there are two input that can be fuzzed (
and ). -
Form parameters. All input fields to forms should be
considered inputs. -
Cookies.
Cookies are values that the application write to the browser cache,
then reads from later. Since the application reads this data from the
browser, cookies are also considered inputs. (e.g. DVWA uses a cookie
to set High/Medium/Low security)
-
Parse URLs. The fuzzer should be able to take a URL
Фаззим драйвера
Итак, мы уже разобрались с фаззингом файлов, протоколов — теперь
попробуем использовать фаззинг для поиска ошибок в драйверах. Тут надо понимать,
что драйверы используются не только для управления устройствами, вовсе нет.
Многие программы устанавливают в систему драйвер в качестве посредника для
доступа в более привилегированный режим — Ring0. Прежде всего, это антивирусы и
утилиты, обеспечивающие (по крайней мере, обещающие обеспечить) безопасность
системы. Драйверы, в общем, ничем не отличаются от программы в плане
безопасности: как и везде, большое количество уязвимостей связано с неправильной
обработкой данных, в особенности тех, что поступают в IRP-запросах. I/O request
packets (IRP) — это специальные структуры, использующиеся моделью драйверов
Windows для взаимодействия и обмена данными драйверов друг с другом и самой
системой. Получается, и здесь есть все условия для того, чтобы автоматизировать
поиск уязвимостей. Конечно, инструмент тут нужен совершенно особенный, потому
как обычным фаззерам доступ в недра системы закрыт.
Одна из немногих разработок в этой области —IOCTL Fuzzer,
которая изначально нацелена на проведение fuzzing-тестов, манипулируя с данными
в IRP-запросах. Программа устанавливает в систему вспомогательный драйвер (не
удивляйся, что подобную активность антивирус посчитает подозрительной), который
перехватывает вызовы NtDeviceIoControlFile, тем самым получая возможность
контролировать все IRP-запросы от любого приложения к драйверам режима ядра. Это
нужно потому, что изначально формат IRP-запроса для конкретного драйвера или
программы неизвестен. А имея на руках перехваченный IRP-запрос, его можно легко
изменить — получается классический фаззинг с помощью мутации. Проспуфенный
IRP-запрос ничем не отличается от оригинального за исключением поля с данными,
которые заполняется фаззером псевдослучайным образом. Поведение фаззера,
лог-файл, названия драйверов для спуфинга и другие параметры задаются с помощью
простейшего XML-конфига, который находится в корне программы. Но прежде чем
рваться в бой, необходима некоторая подготовка.
Из эксперимента с драйверами на рабочей машине ничего хорошего
не выйдет. Если IOCTL Fuzzer удастся нащупать слабое место в каком-нибудь из
драйверов, то система легко улетит в BSOD, а это едва ли прибавит удобства для
идентификации уязвимости :). По этой причине для использования фаззера нам
понадобится отдельная виртуальная машина, к которой мы подключим удаленный
дебаггер ядра. Тут честь и хвала Microsoft, которые не только смогли сделать
толковый отладчик WinDbg, поддерживающий удаленный дебаггинг, но и
распространяют его бесплатно. Взаимодействие между гостевой системой в VMware и
удаленным отладчиком WinDbg осуществляется с помощью именованного канала (named
pipe), который мы сейчас и создадим.
1. Сначала создаем именованный канал в VMware. Для этого
переходим в меню «Settings „p Configuration Editor», нажимаем на кнопку добавить
оборудование («Add»), выбираем «Serial Port», жмем «Next», далее из списка
выбираем тип порта — «Use named pipe» и оставляем дефолтное название для
именованного канала (\\.\pipe\com_1). После этого задаем режим работы «This end
is server. The other end is application» в двух выпадающих полях и напоследок
нажимаем кнопку «Advanced», где активируем опцию «Yiled CPU on poll» (иначе
ничего не заработает).
Осталось реализовать возможность загрузки гостевой системы с
включенным режимом удаленной отладки. Для этого в boot.ini (будем считать, что в
качестве гостевой системы используется Windows XP) необходимо вставить новую
строку для запуска системы, добавив два важных ключа /debugport и /baudrate:
Во время следующей перезагрузки необходимо в загрузчике выбрать
ту версию системы, для которой мы включили режим отладки. Остается настроить сам
отладчик, но для этого нужно лишь во время запуска передать ему параметры
именованного канала:
Вот теперь можно запускать IOCTL Fuzzer в режиме фаззинга, не
опасаясь BSOD’а на основной системе. Выполняем произвольные манипуляции с
тестируемым ПО до тех пор, пока отладчик не сообщит нам о возникновении
необрабатываемого исключения (это значит, что в обычных условиях, скорее всего,
это закончилось бы аварийным завершением работы системы).
Далее необходимо возобновить выполнение кода на виртуальной
машине (в случае с WinDbg надо просто нажать F5), после чего ОС, работающая на
виртуальной машине, запишет аварийный дамп (crash dump) на диск. Готово: теперь
у нас есть подробные логи, дамп и сам запрос, который привел к падению. Дело за
малым — понять, как это можно эксплуатировать :).
Где можно применять фаззинг
Фаззинг можно успешно использовать везде, где на входе требуются сложные данные. Тривиальные случаи решаются простым перебором, но если у тебя есть хотя бы десять байт входных данных, то 280 уже создают проблему при тестировании, и обычные тесты тут вряд ли справятся.
Именно поэтому самые распространенные случаи применения фаззинга приходятся на различные парсеры (XML, JSON), мультимедиакодеки (аудио, видео, графика), сетевые протоколы (HTTP, SMTP), криптографию (SSL/TLS), браузеры (Firefox, Chrome) и компрессию файлов (ZIP, TAR). Также целями фаззинга могут быть компиляторы (C/C++, Go), интерпретаторы (Python, JS), библиотеки для обработки регулярных выражений (regexp), базы данных (SQL) и комплекты офисных приложений (LibreOffice).
Чрезвычайно важен сегодня и фаззинг операционных систем, различных гипервизоров и виртуальных машин. Так что мы в Google даже запустили специальный фаззер syzkaller, который непрерывно тестирует несколько сборок ядра Linux, FreeBSD, NetBSD, а также Android и ChromeOS.
Резюмируем: фаззинг абсолютно необходим для тех программ, которые работают на границе доверия и используют входные данные из ненадежных источников.