Bootstrap — dropdown (выпадающий список)
Содержание:
Data-атрибуты HTML5
К счастью, в HTML5 была введена возможность использовать пользовательские атрибуты. Вы можете использовать любое имя в нижнем регистре с префиксом data-, например:
<div id="msglist" data-user="bob" data-list-size="5" data-maxage="180"></div>
Пользовательские data-атрибуты:
- это строки — в них вы можете хранить любую информацию, которая может быть представлена или закодирована в виде строки, например JSON. Приведение типов должно осуществляться с помощью JavaScript
- должны использоваться в тех случаях, когда нет подходящих элементов HTML5 или атрибутов
- относятся только к странице. В отличие от микроформатов они должны игнорироваться внешними системами, типа поисковых систем и поисковых роботов
Пример №1 обработки на JavaScript: getAttribute и setAttribute
Все браузеры позволяют вам получить и изменить data-атрибуты с использованием методов getAttribute и setAttribute:
var msglist = document.getElementById("msglist");
var show = msglist.getAttribute("data-list-size");
msglist.setAttribute("data-list-size", +show+3);
Это работает, но должно использоваться только для поддержания совместимости со старыми браузерами.
Пример №2 обработки на JavaScript: метод data() библиотеки jQuery
Начиная с версии jQuery 1.4.3 метод data() обрабатывает data-атрибуты HTML5. Вам нет необходимости явно указывать префикс data-, так что подобный код будет работать:
var msglist = $("#msglist");
var show = msglist.data("list-size");
msglist.data("list-size", show+3);
Но как бы то ни было, имейте в виду, что jQuery пытается конвертировать значения таких атрибутов в подхдящие типы (булевы значения, числа, объекты, массивы или null) и затронет DOM. В отличие от setAttribute, метод data() физически не заменит атрибут data-list-size — если вы проверите его значение вне jQuery — оно все еще останется равным 5.
Пример №3 обработки на JavaScript: API для работы с наборами данных
И, наконец, у нас есть API для работы с наборами данных HTML5, которое возвращает объект DOMStringMap. Необходимо помнить, что data-атрибуты отображаются в объект без префиксов data-, из названий убираются знаки дефиса, а сами названия конвертируются в camelCase, например:
| Имя атрибута | Имя в API набора данных |
| data-user | user |
| data-maxage | maxage |
| data-list-size | listSize |
Наш новый код:
var msglist = document.getElementById("msglist");
var show = msglist.dataset.listSize;
msglist.dataset.listSize = +show+3;
Данный API поддерживается всеми современными браузерами, но не IE10 и ниже. Для таких браузеров существует , но, наверное, куда практичнее использовать jQuery, если вы пишете для старых браузеров.
Sometimes
If you do not want to execute the same set of augmenters all the time, will pick some of the augmenters every time.
Recommendation
The above approach is designed to solve problems that authors are facing in their problems. If you understand your data, you should tailor made augmentation approach it. Remember that the golden rule in data science is garbage in garbage out.
In general, you can try the thesaurus approach without quite understanding your data. It may not boost up a lot due to the aforementioned thesaurus approach limitation.
About Me
I am Data Scientist in Bay Area. Focusing on state-of-the-art in Data Science, Artificial Intelligence , especially in NLP and platform related. Feel free to connect with me on LinkedIn or following me on Medium or Github.
Extension Reading
- Image augmentation library (imgaug)
- Text augmentation library (nlpaug)
- Data Augmentation in NLP
- Data Augmentation for Audio
- Data Augmentation for Spectrogram
- Does your NLP model able to prevent an adversarial attacks?
- Data Augmentation in NLP: Best Practices From a Kaggle Master
Reference
- X. Zhang, J. Zhao and Y. LeCun. Character-level Convolutional Networks for Text Classification. 2015
- W. Y. Wang and D. Yang. That’s So Annoying!!!: A Lexical and Frame-Semantic Embedding Based Data Augmentation Approach to Automatic Categorization of Annoying Behaviors using #petpeeve Tweets. 2015
- S. Kobayashi. Contextual Augmentation: Data Augmentation by Words with Paradigmatic Relation. 2018
- C. Coulombe. Text Data Augmentation Made Simple By Leveraging NLP Cloud APIs. 2018
Attributes¶
| Attribute | Value | Description |
|---|---|---|
| value | machine-readable format | Sets the machine-readable version of the contents of the <data> tag. |
The <data> tag also supports the Global Attributes and the Event Attributes.
How to style <data> tag?
Common properties to alter the visual weight/emphasis/size of text in <data> tag:
- CSS font-style property sets the style of the font. normal | italic | oblique | initial | inherit.
- CSS font-family property specifies a prioritized list of one or more font family names and/or generic family names for the selected element.
- CSS font-size property sets the size of the font.
- CSS font-weight property defines whether the font should be bold or thick.
- CSS text-transform property controls text case and capitalization.
- CSS text-decoration property specifies the decoration added to text, and is a shorthand property for text-decoration-line, text-decoration-color, text-decoration-style.
Coloring text in <data> tag:
- CSS color property describes the color of the text content and text decorations.
- CSS background-color property sets the background color of an element.
Text layout styles for <data> tag:
- CSS text-indent property specifies the indentation of the first line in a text block.
- CSS text-overflow property specifies how overflowed content that is not displayed should be signalled to the user.
- CSS white-space property specifies how white-space inside an element is handled.
- CSS word-break property specifies where the lines should be broken.
Other properties worth looking at for <data> tag:
- CSS text-shadow property adds shadow to text.
- CSS text-align-last property sets the alignment of the last line of the text.
- CSS line-height property specifies the height of a line.
- CSS letter-spacing property defines the spaces between letters/characters in a text.
- CSS word-spacing property sets the spacing between words.
| 62+ | 22+ | 49+ |
Manipulating margins¶
TRDG allows you to control margins around the text using two parameters, , . The first one controls margins, in pretty much the same way the CSS property does.
This is the result with no fit and the default (5, 5, 5, 5) margins:

Now we can add to apply a tight crop around the rendered text. This changes the size by removing the added space for accents:
Margins are applied the generated text, so even with , if you don’t use you will get an apparence of margins:

Now if you add , you get an absolutely no margins:

Margin values are comma separated , so will return vertical margins with tight cropping vertically.
And finally, with all margins:
Разбираемся с CSS
Чтобы страницы выглядели красиво, программисты используют CSS — Cascading Style Sheets, они же — каскадные таблицы стилей. Мы про них уже писали в статье про список задач, а сейчас будем разбираться подробнее, как они работают и что можно с их помощью сделать.
Главное, что нужно помнить о CSS, — это правила, по которым браузер «красит» страницу: какого цвета у него фон, какого — текст, какие заголовки и так далее. Правила живут отдельно от контента: в одном месте документа мы говорим «заголовки надо красить вот так», а в другом — «вот тут стоит заголовок, в нем написано то-то».
В больших проектах правила CSS часто выносят в отдельный документ, чтобы не засорять основной код. У сайта может быть файл, в котором будут прописаны все правила оформления, и если что-то нужно перекрасить на всех страницах сайта, достаточно будет просто поменять правило в одном месте.
Так как у нас проект маленький, мы зададим все стили внутри страницы. Так будет проще для понимания и не нужно будет работать с двумя файлами.
Весь код стилей на странице располагается между тегами <style> и </style>. Они говорят браузеру: тут у нас правила оформления. Сначала пишут название элемента, а потом в фигурных скобках — правила. Например, вот этот код отвечает за настройки внешнего вида всей страницы, потому что начинается со слова body. Он как бы говорит: «Всё тело страницы выровняй по центру, используй отступы по 10, шрифт „Вердана“ или „Ариал“ размером 16 пикселей»:
body{ text-align: center; margin: 10; font-family: Verdana, Arial, sans-serif; font-size: 16px; }
А вот этот код определяет только абзацы текста, которые на странице размечены тегом <p>. Он говорит: «Всё, что на странице является абзацем, рисуй шрифтом 14-го размера».
p {
font-size: 14px; }
Часто в параметрах требуется указать размер чего-нибудь. В CSS много измерений размеров: в пикселях, процентах, относительно базового шрифта или относительно текущей ширины экрана. Вот примеры:
margin-top: 15px; /* — 15 пикселейmargin-top: 15em; /* — 15 размеров текущего шрифтаmargin-top: 15vw; /* — 15% от ширины страницы
Иногда стили вписывают не отдельно от основного кода страницы, а прямо внутри кода для конкретного элемента. Для этого используют команду style внутри тега. Например, так:
<div style=»height: 50%; width: 100%;”>
Это значит, что конкретно этот элемент <div> получит половинную высоту и полную ширину. Другие элементы на странице этот стиль не затронет.
Сразу скажем, что прописывать CSS внутри отдельных элементов считается дурным тоном, потому что потом такой код трудно поддерживать. Поэтому всеми силами старайтесь прописывать CSS либо в блоке <style>, либо в отдельном файле.
1) Normalization
One of the key steps in processing language data is to remove noise so that the machine can more easily detect the patterns in the data. Text data contains a lot of noise, this takes the form of special characters such as hashtags, punctuation and numbers. All of which are difficult for computers to understand if they are present in the data. We need to, therefore, process the data to remove these elements.
Additionally, it is also important to apply some attention to the casing of words. If we include both upper case and lower case versions of the same words then the computer will see these as different entities, even though they may be the same.
The code below performs these steps. To keep a track of the changes we are making to the text I have put the clean text into a new column. The output is shown below the code.
import redef clean_text(df, text_field, new_text_field_name): df = df.str.lower() df = df.apply(lambda elem: re.sub(r"(@+)|()|(\w+:\/\/\S+)|^rt|http.+?", "", elem)) # remove numbers df = df.apply(lambda elem: re.sub(r"\d+", "", elem)) return dfdata_clean = clean_text(train_data, 'text', 'text_clean')data_clean.head()

5 последних уроков рубрики «HTML5»
-
В этом уроке я покажу процесс создания собственных HTML тегов. Пользовательские теги решают множество задач: HTML документы становятся проще, а строк кода становится меньше.
-
Сегодня мы посмотрим, как можно организовать проверку доступности атрибута HTML5 с помощью JavaScript. Проверять будем работу элементов details и summary.
-
HTML5 — глоток свежего воздуха в современном вебе. Она повлиял не только на классический веб, каким мы знаем его сейчас. HTML5 предоставляет разработчикам ряд API для создания и улучшения сайтов с ориентацией на мобильные устройства. В этой статье мы рассмотрим API для работы с вибрацией.
-
Веб дизайнеры частенько сталкиваются с необходимостью создания форм. Данная задача не простая, и может вызвать головную боль (особенно если вы делаете что-то не стандартное, к примеру, много-страничную форму). Для упрощения жизни можно воспользоваться фрэймворком. В этой статье я покажу вам несколько практических приёмов для создания форм с помощью фрэймворка Webix.
-
Знакомство с фрэймворком Webix
В этой статье мы бы хотели познакомить вас с фрэймворком Webix. Для демонстрации возможностей данного инструмента мы создадим интерфейс online аудио плеера. Не обольщайтесь — это всего лишь модель интерфейса. Исходный код доступен в демо и на странице GitHub.
Question Answering¶
- class (path, text_field, only_supporting=False, **kwargs)
-
- (path, text_field, only_supporting=False, **kwargs)
-
Create a dataset from a list of Examples and Fields.
Parameters: - examples – List of Examples.
-
fields (List((, ))) – The Fields to use in this tuple. The
string is a field name, and the Field is the associated field. -
filter_pred (callable or ) – Use only examples for which
filter_pred(example) is True, or use all examples if None.
Default is None.
- classmethod (text_field, path=None, root=’.data’, task=1, joint=False, tenK=False, only_supporting=False, train=None, validation=None, test=None, **kwargs)
-
Create Dataset objects for multiple splits of a dataset.
Parameters: -
path () – Common prefix of the splits’ file paths, or None to use
the result of cls.download(root). - root () – Root dataset storage directory. Default is ‘.data’.
-
train () – Suffix to add to path for the train set, or None for no
train set. Default is None. -
validation () – Suffix to add to path for the validation set, or None
for no validation set. Default is None. -
test () – Suffix to add to path for the test set, or None for no test
set. Default is None. -
keyword arguments (Remaining) – Passed to the constructor of the
Dataset (sub)class being used.
Returns: Datasets for train, validation, and
test splits in that order, if provided.Return type: Tuple[]
-
path () – Common prefix of the splits’ file paths, or None to use
Language Modeling¶
Language modeling datasets are subclasses of class.
- class (path, text_field, newline_eos=True, encoding=’utf-8′, **kwargs)
-
Defines a dataset for language modeling.
- (path, text_field, newline_eos=True, encoding=’utf-8′, **kwargs)
-
Create a LanguageModelingDataset given a path and a field.
Parameters: - path – Path to the data file.
- text_field – The field that will be used for text data.
-
newline_eos – Whether to add an <eos> token for every newline in the
data file. Default: True. -
keyword arguments (Remaining) – Passed to the constructor of
data.Dataset.
- class (path, text_field, newline_eos=True, encoding=’utf-8′, **kwargs)
-
- classmethod (batch_size=32, bptt_len=35, device=0, root=’.data’, vectors=None, **kwargs)
-
Create iterator objects for splits of the WikiText-2 dataset.
This is the simplest way to use the dataset, and assumes common
defaults for field, vocabulary, and iterator parameters.Parameters: - batch_size – Batch size.
- bptt_len – Length of sequences for backpropagation through time.
-
device – Device to create batches on. Use -1 for CPU and None for
the currently active GPU device. -
root – The root directory that the dataset’s zip archive will be
expanded into; therefore the directory in whose wikitext-2
subdirectory the data files will be stored. -
wv_type, wv_dim (wv_dir,) – Passed to the Vocab constructor for the
text field. The word vectors are accessible as
train.dataset.fields.vocab.vectors. - keyword arguments (Remaining) – Passed to the splits method.
- classmethod (text_field, root=’.data’, train=’wiki.train.tokens’, validation=’wiki.valid.tokens’, test=’wiki.test.tokens’, **kwargs)
-
Create dataset objects for splits of the WikiText-2 dataset.
This is the most flexible way to use the dataset.
Parameters: - text_field – The field that will be used for text data.
-
root – The root directory that the dataset’s zip archive will be
expanded into; therefore the directory in whose wikitext-2
subdirectory the data files will be stored. - train – The filename of the train data. Default: ‘wiki.train.tokens’.
-
validation – The filename of the validation data, or None to not
load the validation set. Default: ‘wiki.valid.tokens’. -
test – The filename of the test data, or None to not load the test
set. Default: ‘wiki.test.tokens’.
- class (path, text_field, newline_eos=True, encoding=’utf-8′, **kwargs)
-
- classmethod (batch_size=32, bptt_len=35, device=0, root=’.data’, vectors=None, **kwargs)
-
Create iterator objects for splits of the WikiText-103 dataset.
This is the simplest way to use the dataset, and assumes common
defaults for field, vocabulary, and iterator parameters.Parameters: - batch_size – Batch size.
- bptt_len – Length of sequences for backpropagation through time.
-
device – Device to create batches on. Use -1 for CPU and None for
the currently active GPU device. -
root – The root directory that the dataset’s zip archive will be
expanded into; therefore the directory in whose wikitext-2
subdirectory the data files will be stored. -
wv_type, wv_dim (wv_dir,) – Passed to the Vocab constructor for the
text field. The word vectors are accessible as
train.dataset.fields.vocab.vectors. - keyword arguments (Remaining) – Passed to the splits method.
- classmethod (text_field, root=’.data’, train=’wiki.train.tokens’, validation=’wiki.valid.tokens’, test=’wiki.test.tokens’, **kwargs)
-
Create dataset objects for splits of the WikiText-103 dataset.
This is the most flexible way to use the dataset.
Parameters: - text_field – The field that will be used for text data.
-
root – The root directory that the dataset’s zip archive will be
expanded into; therefore the directory in whose wikitext-103
subdirectory the data files will be stored. - train – The filename of the train data. Default: ‘wiki.train.tokens’.
-
validation – The filename of the validation data, or None to not
load the validation set. Default: ‘wiki.valid.tokens’. -
test – The filename of the test data, or None to not load the test
set. Default: ‘wiki.test.tokens’.
Contextualized Word Embeddings
Since classic word embeddings use a static vector to represent the same word. It may not fit some scenarios. For “Fox” can represent as animal and broadcasting company. To overcome this problem, contextualized word embeddings is introduced to consider surrounding words to generate a vector under a different context.
is designed to provide this feature to perform insertion and substitution. Different from previous word embeddings, insertion is predicted by BERT language model rather than pick one word randomly. Substitution use surrounding words as a feature to predict the target word.
Example of insert augmentation
Original:The quick brown fox jumps over the lazy dogAugmented Text:the lazy quick brown fox always jumps over the lazy dog
Example of substitute augmentation
Original:The quick brown fox jumps over the lazy dogAugmented Text:the quick thinking fox jumps over the lazy dog
Synonym
Besides the neural network approach, a thesaurus can achieve similar objectives. The limitation of synonym is that some words may not have similar words. WordNet from an awesome NLTK library helps to find the synonym words.
provides a substitution feature to replace the target word. Instead of finding synonyms purely, some preliminary checking makes sure that the target word can be replaced. Those rules are:
- Do not pick determiner (e.g. a, an, the)
- Do not pick a word that does not has a synonym.
Example of augmentation
Original:The quick brown fox jumps over the lazy dogAugmented Text:The quick brown fox parachute over the lazy blackguard
Sequence Tagging¶
Sequence tagging datasets are subclasses of class.
- class (path, fields, separator=’t’, **kwargs)
-
Defines a dataset for sequence tagging. Examples in this dataset
contain paired lists – paired list of words and tags.For example, in the case of part-of-speech tagging, an example is of the
form
paired withSee torchtext/test/sequence_tagging.py on how to use this class.
- (path, fields, separator=’\t’, **kwargs)
-
Create a dataset from a list of Examples and Fields.
Parameters: - examples – List of Examples.
-
fields (List((, ))) – The Fields to use in this tuple. The
string is a field name, and the Field is the associated field. -
filter_pred (callable or ) – Use only examples for which
filter_pred(example) is True, or use all examples if None.
Default is None.
- class (path, fields, separator=’t’, **kwargs)
-
- classmethod (fields, root=’.data’, train=’en-ud-tag.v2.train.txt’, validation=’en-ud-tag.v2.dev.txt’, test=’en-ud-tag.v2.test.txt’, **kwargs)
-
Downloads and loads the Universal Dependencies Version 2 POS Tagged
data.
How to style tag?
Common properties to alter the visual weight/emphasis/size of text in <data> tag:
- CSS font-style property sets the style of the font. normal | italic | oblique | initial | inherit.
- CSS font-family property specifies a prioritized list of one or more font family names and/or generic family names for the selected element.
- CSS font-size property sets the size of the font.
- CSS font-weight property defines whether the font should be bold or thick.
- CSS text-transform property controls text case and capitalization.
- CSS text-decoration property specifies the decoration added to text, and is a shorthand property for text-decoration-line, text-decoration-color, text-decoration-style.
Coloring text in <data> tag:
- CSS color property describes the color of the text content and text decorations.
- CSS background-color property sets the background color of an element.
Text layout styles for <data> tag:
- CSS text-indent property specifies the indentation of the first line in a text block.
- CSS text-overflow property specifies how overflowed content that is not displayed should be signalled to the user.
- CSS white-space property specifies how white-space inside an element is handled.
- CSS word-break property specifies where the lines should be broken.
Other properties worth looking at for <data> tag:
5) Part of Speech (POS) tagging and chunking
Part of speech (POS) tagging is a method to categorise words which gives some information relating to the way in which that word is used in speech.
There are eight primary parts of speech and they each have a corresponding tag. These are shown in the table below.

The NLTK libary has a method to perform POS tagging. The below code performs POS tagging on the tweets in our data set and returns a new column.
def word_pos_tagger(text): pos_tagged_text = nltk.pos_tag(text) return pos_tagged_textnltk.download('averaged_perceptron_tagger')data_clean = data_clean.apply(lambda x: word_pos_tagger(x))data_clean.head()

Chunking builds on POS tagging in that it uses the information from the POS tags to extract meaningful phrases from text. In many types of texts, if we reduce everything down to individual words we may lose a lot of meaning. In our tweets, for example, we have a lot of location names and other phrases which are important to keep together.
If we take this sentence “forest fire near la ronge sask canada” the location name “la ronge” and the words “forest fire” will convey an important meaning that we might not want to lose.
The spaCy python library has a method for this. If we apply this method to the above sentence we can see that it separates out the appropriate phrases.
import spacynlp = spacy.load('en')text = nlp("forest fire near la ronge sask canada")for chunk in text.noun_chunks: print(chunk.text, chunk.label_, chunk.root.text)
3) Stemming
Stemming is the process of reducing words to their root form. For example, the words “rain”, “raining” and “rained” have very similar, and in many cases, the same meaning. The process of stemming will reduce these to the root form of “rain”. This is again a way to reduce noise and the dimensionality of the data.
The NLTK library also has methods to perform the task of stemming. The code below uses the PorterStemmer to stem the words in my example above. As you can see from the output all the words now become “rain”.
from nltk.stem import PorterStemmer from nltk.tokenize import word_tokenizeword_list = ps = PorterStemmer()for w in word_list: print(ps.stem(w))
Before we can perform stemming on our data we need to tokenise the tweets. This is a method used to split the text into its constituent parts usually words. The code below uses NLTK to do this. I have put the output into a new column called “text_tokens”.
import nltk nltk.download('punkt')from nltk.tokenize import sent_tokenize, word_tokenizedata_clean = data_clean.apply(lambda x: word_tokenize(x))data_clean.head()

The code below uses the PorterStemmer method from NLTK to apply stemming to the text_tokens and outputs the processed text to a new column.
def word_stemmer(text): stem_text = return stem_textdata_clean = data_clean.apply(lambda x: word_stemmer(x))data_clean.head()

Sentiment Analysis¶
- class (path, text_field, label_field, subtrees=False, fine_grained=False, **kwargs)
-
- classmethod (batch_size=32, device=0, root=’.data’, vectors=None, **kwargs)
-
Create iterator objects for splits of the SST dataset.
Parameters: - batch_size – Batch_size
-
device – Device to create batches on. Use — 1 for CPU and None for
the currently active GPU device. -
root – The root directory that the dataset’s zip archive will be
expanded into; therefore the directory in whose trees
subdirectory the data files will be stored. -
vectors – one of the available pretrained vectors or a list with each
element one of the available pretrained vectors (see Vocab.load_vectors) - keyword arguments (Remaining) – Passed to the splits method.
- classmethod (text_field, label_field, root=’.data’, train=’train.txt’, validation=’dev.txt’, test=’test.txt’, train_subtrees=False, **kwargs)
-
Create dataset objects for splits of the SST dataset.
Parameters: - text_field – The field that will be used for the sentence.
- label_field – The field that will be used for label data.
-
root – The root directory that the dataset’s zip archive will be
expanded into; therefore the directory in whose trees
subdirectory the data files will be stored. - train – The filename of the train data. Default: ‘train.txt’.
-
validation – The filename of the validation data, or None to not
load the validation set. Default: ‘dev.txt’. -
test – The filename of the test data, or None to not load the test
set. Default: ‘test.txt’. -
train_subtrees – Whether to use all subtrees in the training set.
Default: False. -
keyword arguments (Remaining) – Passed to the splits method of
Dataset.
Word Embeddings (word2vec, GloVe, fasttext)
Classic embeddings use a static vector to present a word. Ideally, the meaning of the word is similar if vectors are near each other. Actually, it depends on the training data. For example, “rabbit” is similar to “fox” in word2vec while “nbc” is similar to “fox” in GloVe.
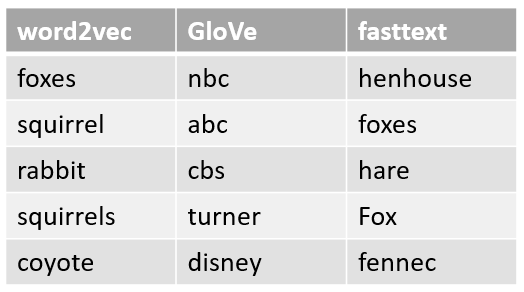
Most similar words of “fox” among classical word embeddings models
Sometimes, you want to replace words by similar words such that NLP model does not rely on a single word., and are designed to provide a “similar” word based on pre-trained vectors.
Besides substitution, insertion helps to inject noise into your data. It picks words from vocabulary randomly.
Example of insert augmentation
Original:The quick brown fox jumps over the lazy dogAugmented Text:The quick Bergen-Belsen brown fox jumps over Tiko the lazy dog
Example of substitute augmentation
Original:The quick brown fox jumps over the lazy dogAugmented Text:The quick gray fox jumps over to lazy dog
OCR
When working on NLP problem, OCR results may be one of the inputs of your NLP problem. For example, “0” may be recognized as “o” or “O”. If you are using bag-of-words or classic word embeddings as a feature, you will get trouble as out-of-vocabulary (OOV) around you today and always. If you use state-of-the-art models such as BERT and GPT, the OOV issue seems resolved as word will be split to subword. However, some information is lost.
is designed to simulate OCR error. It will replace the target character by pre-defined mapping table.

Example of augmentation
Original:The quick brown fox jumps over the lazy dogAugmented Text:The quick brown fox jumps over the lazy d0g
Iterators¶
Iterator
- class (dataset, batch_size, sort_key=None, device=None, batch_size_fn=None, train=True, repeat=False, shuffle=None, sort=None, sort_within_batch=None)
-
Defines an iterator that loads batches of data from a Dataset.
Variables: - dataset – The Dataset object to load Examples from.
- batch_size – Batch size.
-
batch_size_fn – Function of three arguments (new example to add, current
count of examples in the batch, and current effective batch size)
that returns the new effective batch size resulting from adding
that example to a batch. This is useful for dynamic batching, where
this function would add to the current effective batch size the
number of tokens in the new example. -
sort_key – A key to use for sorting examples in order to batch together
examples with similar lengths and minimize padding. The sort_key
provided to the Iterator constructor overrides the sort_key
attribute of the Dataset, or defers to it if None. - train – Whether the iterator represents a train set.
- repeat – Whether to repeat the iterator for multiple epochs. Default: False.
- shuffle – Whether to shuffle examples between epochs.
-
sort – Whether to sort examples according to self.sort_key.
Note that shuffle and sort default to train and (not train). -
sort_within_batch – Whether to sort (in descending order according to
self.sort_key) within each batch. If None, defaults to self.sort.
If self.sort is True and this is False, the batch is left in the
original (ascending) sorted order. -
device (str or torch.device) – A string or instance of torch.device
specifying which device the Variables are going to be created on.
If left as default, the tensors will be created on cpu. Default: None.
- (dataset, batch_size, sort_key=None, device=None, batch_size_fn=None, train=True, repeat=False, shuffle=None, sort=None, sort_within_batch=None)
-
Initialize self. See help(type(self)) for accurate signature.
- ()
-
Return the examples in the dataset in order, sorted, or shuffled.
- ()
-
Set up the batch generator for a new epoch.
- classmethod (datasets, batch_sizes=None, **kwargs)
-
Create Iterator objects for multiple splits of a dataset.
Parameters: -
datasets – Tuple of Dataset objects corresponding to the splits. The
first such object should be the train set. -
batch_sizes – Tuple of batch sizes to use for the different splits,
or None to use the same batch_size for all splits. -
keyword arguments (Remaining) – Passed to the constructor of the
iterator class being used.
-
datasets – Tuple of Dataset objects corresponding to the splits. The
BucketIterator
- class (dataset, batch_size, sort_key=None, device=None, batch_size_fn=None, train=True, repeat=False, shuffle=None, sort=None, sort_within_batch=None)
-
Defines an iterator that batches examples of similar lengths together.
Minimizes amount of padding needed while producing freshly shuffled
batches for each new epoch. See pool for the bucketing procedure used.
Functions¶
pool
- (data, batch_size, key, batch_size_fn=<function <lambda>>, random_shuffler=None, shuffle=False, sort_within_batch=False)
-
Sort within buckets, then batch, then shuffle batches.
Partitions data into chunks of size 100*batch_size, sorts examples within
each chunk using sort_key, then batch these examples and shuffle the
batches.
interleave_keys
- (a, b)
-
Interleave bits from two sort keys to form a joint sort key.
Examples that are similar in both of the provided keys will have similar
values for the key defined by this function. Useful for tasks with two
text fields like machine translation or natural language inference.
Random Character
From different research, noise injection may help to generalized your NLP model sometimes. We may add some noise to your word such as adding or deleting one character from your word.
is designed to inject noise into your data. Unlike and , it supports insertion, substitution, and insertion.
Example of insert augmentation
Original:The quick brown fox jumps over the lazy dogAugmented Text:T(he quicdk browTn Ffox jumpvs 7over kthe clazy 9dog
Word
Besides character augmentation, word level is important as well. We make use of word2vec (Mikolov et al., 2013), GloVe (Pennington et al., 2014), fasttext (Joulin et al., 2016), BERT(Devlin et al., 2018) and wordnet to insert and substitute similar word. , and use word embeddings to find the most similar group of words to replace the original word. On the other hand, use language models to predict possible target words. use statistics way to find a similar group of words.
A more advanced use case¶
Text in the real world is not always black, and most importantly, text in the real
world is almost never straight. What if we want to emulate that?
Which can be translated to: generate 10 examples with a skewing angle between -15 and
15 with an added gaussian blur between 0 and 0.1. Finally, the text color should be picked randomly
between black and gray (including all the colors inbetween).
Sure enough, the output is much more colourful!
The default resolution might be too small to your taste (and I agree). By default the output is 32 pixels high
because it’s the height used by most text recognition papers. Now you can change that with .






