Ваша первая нейронная сеть на графическом процессоре (gpu). руководство для начинающих
Содержание:
- Многоядерность процессора
- Что такое технология CUDA?
- Miscellaneous
- Влияет ли на хешрейт версия CUDA, установленная на компьютере?
- White Papers
- Tools
- Пример [ править | править код ]
- Аппаратные компоненты бортовой МПС унифицированного ударного истребителя F-35
- Оборудование [ править | править код ]
- Windows
- Сколько ядер CUDA вам нужно?
- Посторонись, CUDA — Intel анонсировала 7-нанометровый GPU для дата-центров
- Notices
- Что делают ядра CUDA в играх?
- Программная архитектура [ править | править код ]
- CUDA API References
- GPU Bound. Как перенести на видеокарту все и немножко больше. Анимации
- Видеокарта и типы памяти
- Преимущества [ править | править код ]
- Mac OSX
- Вывод
Многоядерность процессора
Рассмотрим сначала ЦП с одним ядром.
Как вы уже знаете, процесс разбивается на несколько потоков. Но что происходит, когда вы хотите одновременно выполнять несколько процессов, например, печатать в Microsoft Word и слушать музыку?
Компьютер умный и делает вид, что выполняет действия одновременно. На самом деле происходят быстрые переключения между одним и другим процессом. Они мгновенны, поэтому вы не сможете их заметить. Тем не менее, на это тратится время, что снижает скорость выполнения задач. Если вы захотите выполнять не 2, а 4 действия сразу? Компьютер выполнит все, что вы требуете, но медленно.
Решение
В виду того, что многие игры и программы предъявляют все более высокие требования к процессорам, их производители добавляют ядра. Таким образом, за один поток команд отвечает первое ядро, за другой — второе и т. д.; если одно выполнило свою задачу, может помочь другому. Прирост в производительности очевиден.
Первый ЦП с двумя ядрами для настольных компов выпущен в 2005 году. Это Pentium D компании Intel. В том же году ее догнал конкурент — AMD — произведя на свет двухъядерник Opteron. На данный момент существуют процы и с 4, и с 8 ядрами.
Технология
К слову, еще на производительность многоядерных процессоров влияет наличие технологии Hyper-Treading. Ее суть заключается в том, что одно физическое ядро определяется системой как два логических. Это значит, что одно ядро может обрабатывать 2 потока одновременно.
Графическое ядро
В некоторые процессоры встраивается графическое ядро, которое не следует путать с вышеописанными. Как понятно из названия, данное ядро отвечает за обработку графики. Оно выступает альтернативой дискретной видеокарте. Такое решение позволяет экономить пространство в корпусе компьютера.
Что такое технология CUDA?
CUDA (Compute Unified Device Architecture) — это технология многопотоковых компьютерных вычислений, созданная компанией NVIDIA. Она позволяет значительно увеличить производительность при проведении сложных расчетов за счет распараллеливания на множестве вычислительных ядер.
Приложения CUDA используются для обработки видео и аудио, моделирования физических эффектов, в процессе разведки месторождений нефти и газа, проектировании различных изделий, медицинской визуализации и научных исследованиях, в разработке вакцин от болезней, в том числе COVID-19, физическом моделировании и других областях.
CUDA — это архитектура параллельных вычислений общего назначения, которая позволяет решать сложные вычислительные задачи с помощью GPU. CUDA поддерживает операционные системы Linux и Windows. Чем больше ядер CUDA имеет видеокарта и чем больше частота их работы, тем большую производительность она может обеспечить.
Каждая дополнительна единица вычислительной мощности требует соответствующего количества потребленной электроэнергии. Чем меньший технологический процесс используется при производстве вычислительных ядер, тем меньшие напряжения используются для их питания и, соответственно снижается потребление. Поэтому, даже если видеокарты разных поколений имеют одинаковую теоретическую вычислительную мощность в TFlops, их эффективность кардинально отличается по КПД, в значительной мере зависящему от потребления полупроводниковых элементов, из которых состоят ядра видеопроцессоров.
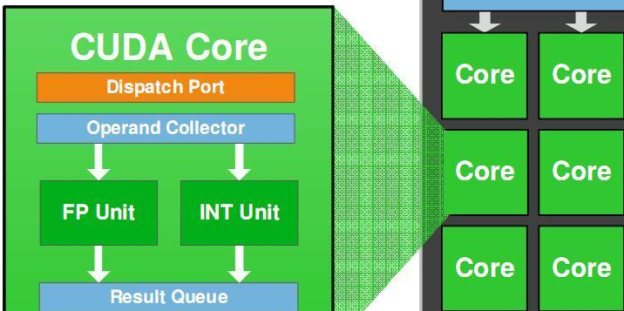
Архитектура CUDA упрощенно включает набор исполняемых команд и аппаратный механизм проведения параллельных вычислений внутри графического процессора. Разработчики программного обеспечения, в том числе майнеров, для работы с CUDA обычно используют языки программирования высокого уровня (C, Фортран). В будущем в CUDA планируется добавление полноценной поддержки C ++, Java и Python. Продвинутые программисты дополнительно улучшают эффективность майнеров с помощью оптимизации кода майнеров на языке более низкого (машинного) уровня – Ассемблере. В качестве примера в этом контексте можно привести Клеймор дуал майнер, который показывает высочайшую эффективность на зеленых видеокартах.
В технологии CUDA есть три важных элемента: библиотеки разработчика, среда выполнения и драйвера. Все они прямо влияют на производительность и надежность работы приложений.
Драйвер — это уровень абстракции устройств с поддержкой CUDA, который обеспечивает интерфейс доступа для аппаратных устройств. С помощью среды выполнения через этот уровень реализуется выполнение различных функций по проведению сложных вычислений.
Таблица версий CUDA, поддерживающихся в драйверах NVIDIA разных версий:
|
ВерсияCUDA |
Версия драйвера для видеокарт NVIDIA |
|
|
Windows x86_64 |
Linux x86_64 |
|
|
11 |
> = 451.22 |
>= 450.36.06 |
|
10,2 |
> = 441.22 |
>= 440.33 |
|
10,1 |
> = 418.96 |
>= 418.39 |
|
10,0 |
> = 411.31 |
>= 410.48 |
|
9,2 |
> = 397.44 |
>= 396.26 |
|
9,1 |
> = 391.29 |
>= 390.46 |
|
9,0 |
> = 385,54 |
>= 384.81 |
|
8,0 |
> = 369,30 |
>= 367.48 |
|
7,5 |
> = 353,66 |
>= 352.31 |
|
7,0 |
> = 347,62 |
>= 352.31 |
Библиотеки разработки (CUDA SDK) на практике реализуют выполнение математических операций и крупномасштабных задач параллельных вычислений.
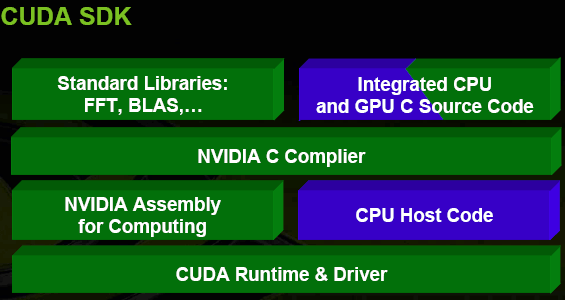
Среда выполнения CUDA — это интерфейс разработчика плюс компоненты выполнения программного кода. Она определяет основные типы данных и функций для проведения вычислений, преобразований, управления памятью, позволяет реализовать доступ к устройствам и спланировать выполнение команд.
Программный код CUDA на практике обычно состоит из двух частей, одна из которых выполняется на CPU, а другая на GPU.
Ядро CUDA имеет три важных абстрактных понятия:
- иерархия групп потоков;
- разделяемая память;
- синхронизация барьеров,
которые могут быть достаточно легко представлены и использованы на языке программирования Си.
Программный стек CUDA состоит из нескольких уровней, аппаратного драйвера, интерфейса прикладного программирования (API) и среды его выполнения, а также двух расширенных математических библиотек общего назначения, CUFFT и CUBLAS.
Теоретически каждое новое поколение CUDA должно демонстрировать более высокую производительность за счет устранения выявленных ошибок, оптимизации кода, добавления новых алгоритмов и прочих новшеств. К сожалению, на практике это не всегда соответствует реалиям. В особенности это связано с постоянным ростом аппетита программ по отношению аппаратным ресурсам. Это касается не только программных пакетов CUDA, но затрагивает даже такие, казалось бы, независимые операционные системы, как Linux.
Miscellaneous
- CUDA Samples
- This document contains a complete listing of the code samples that are
included with the NVIDIA CUDA Toolkit. It describes each code sample,
lists the minimum GPU specification, and provides links to the source
code and white papers if available. - CUDA Demo Suite
- This document describes the demo applications shipped with the CUDA Demo Suite.
- CUDA on WSL
- This guide is intended to help users
get started with using NVIDIA CUDA on Windows Subsystem for Linux (WSL 2).
The guide covers installation and running CUDA applications and containers
in this environment. - Multi-Instance GPU (MIG)
- This edition of the user guide describes the Multi-Instance GPU feature of the NVIDIA A100 GPU.
- CUPTI
- The CUPTI-API. The CUDA Profiling Tools Interface (CUPTI)
enables the creation of profiling and tracing tools that target CUDA applications. - Debugger API
- The CUDA debugger API.
- GPUDirect RDMA
- A technology introduced in Kepler-class GPUs and CUDA 5.0,
enabling a direct path for communication between the GPU and a third-party peer
device on the PCI Express bus when the devices share the same upstream
root complex using standard features of PCI Express. This document
introduces the technology and describes the steps necessary to enable a
GPUDirect RDMA connection to NVIDIA GPUs within the Linux device
driver model. - vGPU
- vGPUs that support CUDA.
Влияет ли на хешрейт версия CUDA, установленная на компьютере?
Практические опыты с майнерами на разных версиях CUDA показывают, что новые версии особого прироста в хешрейте не дают.
Использование новых драйверов Nvidia обычно сопряжено с увеличением требований к аппаратному обеспечению и часто влечет рост потребления видеопамяти, что не всегда положительно сказываются на производительности видеокарт при майнинге.
Это особенно проявляется в быстродействии и потреблении видеопамяти при майнинге на алгоритме Ethash/DaggerHashimoto. Как правило, старые версии драйверов потребляют меньше видеопамяти при одинаковой производительности на Ethash.
Для обычных пользователей нет необходимости заботиться о версии CUDA, если только этого не требуют последние версии майнеров с новыми поддерживающимися алгоритмами.
Тем не менее, нужно учитывать, что технология CUDA постоянно совершенствуется, в нее добавляются новые возможности, которые требуют адаптации программ-майнеров. Поэтому современные майнеры иногда имеют разные версии, которые поддерживают работу с разными версиями CUDA 8.0, 9.1/9.2, а также 10.0, 10.1 и 10.2.
White Papers
- Floating Point and IEEE 754
- A number of issues related to floating point accuracy and compliance are
a frequent source of confusion on both CPUs and GPUs. The purpose of this
white paper is to discuss the most common issues related to NVIDIA GPUs
and to supplement the documentation in the CUDA C Programming Guide. - Incomplete-LU and Cholesky Preconditioned Iterative Methods
- In this white paper we show how to use the
cuSPARSE and cuBLAS libraries to achieve a 2x speedup over CPU in the
incomplete-LU and Cholesky preconditioned iterative methods. We focus on
the Bi-Conjugate Gradient Stabilized and Conjugate Gradient iterative
methods, that can be used to solve large sparse nonsymmetric and
symmetric positive definite linear systems, respectively. Also, we
comment on the parallel sparse triangular solve, which is an essential
building block in these algorithms.
Tools
- NVCC
-
This is a reference document for nvcc,
the CUDA compiler driver.
nvcc accepts a range of conventional compiler options,
such as for defining macros and include/library paths, and for steering
the compilation process. - CUDA-GDB
- The NVIDIA tool for debugging CUDA applications running on Linux and QNX, providing developers with a mechanism for debugging
CUDA applications running on actual hardware. CUDA-GDB is an extension to the x86-64 port of GDB, the GNU Project debugger. - CUDA-MEMCHECK
- CUDA-MEMCHECK is a suite of run time tools capable of precisely detecting
out of bounds and misaligned memory access errors, checking device
allocation leaks, reporting hardware errors and identifying shared memory data
access hazards. - Compute Sanitizer
- The user guide for Compute Sanitizer.
- Nsight Eclipse Plugins Installation Guide
- Nsight Eclipse Plugins Installation Guide
- Nsight Eclipse Plugins Edition
- Nsight Eclipse Plugins Edition getting started guide
- Nsight Compute
- The NVIDIA Nsight Compute is the next-generation interactive kernel profiler for CUDA applications. It provides detailed performance
metrics and API debugging via a user interface and command line tool. - Profiler
- This is the guide to the Profiler.
- CUDA Binary Utilities
- The application notes for cuobjdump, nvdisasm, and nvprune.
Пример [ править | править код ]
Этот пример кода на C++ загрузки текстур из изображения в массив на GPU:
Пример программы на языке Python, перемножающий элементы массива средствами GPU. Взаимодействие идёт с использованием PyCUDA
Уже долгое время технология CUDA является одной из главных особенностей видеокарт GeForce. Однако не все понимают, что это за технология и как она влияет на игры.
В этой статье расскажу и дам короткое объяснение. Так же рассмотрим и другие вопросы, которые могут возникнуть у пользователей.
CUDA это аббревиатура технологии запатентованной Nvidia, означает Compute Unified Device Architecture (Вычислительная Унифицированная Архитектура Устройства). То есть это архитектура — такая форма организации внутреннего устройства ядер в видеокарте. Какая же цель этой технологи? Эффективные параллельные (одновременные) вычисления.
Одно ядро CUDA аналогично процессорному, с той лишь разницей, что оно проще по своей структуре, однако их количество очень большое. Типичный игровой процессор имеет от 2 до 16 ядер, а ядер CUDA в видюхе — сотни, даже в бюджетных видеокартах Nvidia. А высокопроизводительные решения и вовсе насчитывают тысячи.
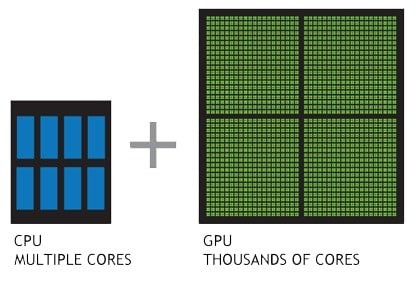
Работа видеокарты во многом отличается от работы центрального процессора — процессор выступает в роли администратора, который управляет необходимыми операциями, а видеокарта берет на себя выполнения всех тяжелых задач.
Обработка графики требует одновременного выполнения сложных вычислений, именно одновременного. Поэтому в видеокартах и реализовано такое огромное количество ядер CUDA. Учитывая факт оптимизации видеокарт специально для работы с графикой, их ядра намного меньше и проще, чем у более универсальных ядер центрального процессора.


В отличии от Nvidia с технологией CUDA, их главный конкурент AMD, использует другую технологию — Потоковые процессоры (Stream Processors)
Обе технологии являются собственной разработкой компаний и в них есть различия, однако для обычного пользователя большой разницы между ними нет.
Это достаточно сложный вопрос, ответ на который не стоит искать в сухих цифрах характеристик графического адаптера. Количество не даст никаких представлений о производительности.
Многие другие характеристики, например, объем видеопамяти, поколение и скорости шины видеокарты намного важнее, для пользователя, чем данные о ядрах CUDA. Так же не стоит забывать об оптимизации в самих играх.
Лучшим способом выбора графического адаптера является все таки просмотр тестов производительности, просмотр отзывов людей, которые уже пользуются конкретной видеокартой, анализ рынка в целом, чтобы понять что выбирают покупатели. И конечно подбор по системным требованиям и fps под конкретную игру, в которую вы хотите зарубиться
Надеюсь, что помог ответить на вопрос о назначении ядер CUDA и развеять все сомнения и заблуждения о данной технологии. Теперь вы знаете что они делают и насколько важны.
Аппаратные компоненты бортовой МПС унифицированного ударного истребителя F-35
Приоритеты современной военной авиации сосредоточены на качественной ситуационной осведомлённости, поэтому современный истребитель представляет собой летающий рой высокотехнологичных сенсоров. Сбор информации с этих сенсоров, её обработку и представление пользователю осуществляет бортовая микропроцессорная система (МПС). Вчера для её реализации использовались HPEC-гибриды (включающие в себя CPU, GPU и FPGA). Сегодня для её реализации используются однокристальные SoC-системы, которые помимо того, что все компоненты на один чипсет собирают, так ещё и внутричиповую сеть организуют (NoC), как альтернативу традиционной магистрали передачи данных. Завтра, когда SoC-системы станут ещё более зрелыми, ожидается приход полиморфной наноэлектроники, которая даст существенный прирост производительности и снизит темп своего морального устаревания.
Оборудование [ править | править код ]
Платформа CUDA впервые появились на рынке с выходом чипа NVIDIA восьмого поколения G80 и стала присутствовать во всех последующих сериях графических чипов, которые используются в семействах ускорителей GeForce, Quadro и NVidia Tesla.
Первая серия оборудования, поддерживающая CUDA SDK, G8x, имела 32-битный векторный процессор одинарной точности, использующий CUDA SDK как API (CUDA поддерживает тип double языка Си, однако сейчас его точность понижена до 32-битного с плавающей запятой). Более поздние процессоры GT200 имеют поддержку 64-битной точности (только для SFU), но производительность значительно хуже, чем для 32-битной точности (из-за того, что SFU всего два на каждый потоковый мультипроцессор, а скалярных процессоров — восемь). Графический процессор организует аппаратную многопоточность, что позволяет задействовать все ресурсы графического процессора. Таким образом, открывается перспектива переложить функции физического ускорителя на графический ускоритель (пример реализации — PhysX). Также открываются широкие возможности использования графического оборудования компьютера для выполнения сложных неграфических вычислений: например, в вычислительной биологии и в иных отраслях науки.
Windows
When installing CUDA on Windows, you can choose between the Network Installer and the Local Installer. The Network Installer
allows you to download only the files you need. The Local Installer is a stand-alone installer with a large initial download.
For more details, refer to the Windows Installation Guide.
Perform the following steps to install CUDA and verify the installation.
- Launch the downloaded installer package.
- Read and accept the EULA.
- Select «next» to download and install all components.
- Once the download completes, the installation will begin automatically.
- Once the installation completes, click «next» to acknowledge the Nsight Visual Studio Edition installation summary.
- Click «close» to close the installer.
- Navigate to the CUDA Samples’ nbody directory.
- Open the nbody Visual Studio solution file for the version of Visual Studio you have installed.
- Open the «Build» menu within Visual Studio and click «Build Solution».
- Navigate to the CUDA Samples’ build directory and run the nbody sample.
Сколько ядер CUDA вам нужно?
И вот сложный вопрос. Как часто бывает с бумажными спецификациями, они просто не являются хорошим индикатором того, какую производительность вы можете ожидать от аппаратного обеспечения.
Многие другие спецификации, такие как пропускная способность VRAM, более важны для рассмотрения, чем количество ядер CUDA, а также вопрос оптимизации программного обеспечения.
Поэтому лучший способ определить производительность видеокарты — взглянуть на некоторые тесты. Таким образом, вы можете точно знать, какой тип производительности вы можете ожидать в определенной игре.
Для общего представления о том, насколько мощен графический процессор, мы рекомендуем проверить UserBenchmark. Однако, если вы хотите увидеть детальное и всестороннее тестирование, есть несколько надежных сайтов, таких как GamersNexus, TrustedReviews, Tom’s Hardware, AnandTech и ряд других.
Посторонись, CUDA — Intel анонсировала 7-нанометровый GPU для дата-центров
По прогнозам аналитиков, рынок дата-центров в ближайшие годы будет расти на 38% в год и за пять лет вырастет до $35 млрд, а самая ресурсоёмкая ниша (по интенсивности вычислений) — глубокое обучение, нейросети и задачи AI.
Конечно, Intel не собирается равнодушно смотреть, как Nvidia (и AMD, в меньшей степени) со своими GPU захватывают этот рынок, включая самый быстрорастущий сектор. На прошлой неделе гигант микроэлектронной промышленности сделал сразу несколько громких анонсов:
- процессоры для нейросетей Nervana NNP-T1000 и NNP-I1000 (NNP: neural network processors), а также чип Movidius VPU;
- 10-нанометровые процессоры Xeon Scalable (кодовое название Sapphire Rapids);
- унифицированные программные интерфейсы oneAPI (для CPU, GPU, FPGA) — конкурента Nvidia CUDA;
- 7-нанометровый GPU для дата-центров с кодовым названием Ponte Vecchio на новой архитектуре Xe.
Notices
Notice
ALL NVIDIA DESIGN SPECIFICATIONS, REFERENCE BOARDS, FILES, DRAWINGS, DIAGNOSTICS, LISTS, AND OTHER DOCUMENTS (TOGETHER AND
SEPARATELY, «MATERIALS») ARE BEING PROVIDED «AS IS.» NVIDIA MAKES NO WARRANTIES, EXPRESSED, IMPLIED, STATUTORY, OR OTHERWISE
WITH RESPECT TO THE MATERIALS, AND EXPRESSLY DISCLAIMS ALL IMPLIED WARRANTIES OF NONINFRINGEMENT, MERCHANTABILITY, AND FITNESS
FOR A PARTICULAR PURPOSE.
Information furnished is believed to be accurate and reliable. However, NVIDIA Corporation assumes no responsibility for the
consequences of use of such information or for any infringement of patents or other rights of third parties that may result
from its use. No license is granted by implication of otherwise under any patent rights of NVIDIA Corporation. Specifications
mentioned in this publication are subject to change without notice. This publication supersedes and replaces all other information
previously supplied. NVIDIA Corporation products are not authorized as critical components in life support devices or systems
without express written approval of NVIDIA Corporation.
Trademarks
NVIDIA and the NVIDIA logo are trademarks or registered trademarks of NVIDIA Corporation
in the U.S. and other countries. Other company and product names may be trademarks of
the respective companies with which they are associated.
Copyright
2015-2020 NVIDIA
Corporation. All rights reserved.
This product includes software developed by the Syncro Soft SRL (http://www.sync.ro/).
Что делают ядра CUDA в играх?
GPU во многих отношениях отличается от CPU, но, если говорить об этом с точки зрения непрофессионала: CPU — это скорее администратор, отвечающий за управление компьютером в целом, а GPU лучше всего подходит для выполнения тяжелых работ.
Обработка графики требует одновременного выполнения множества сложных вычислений, поэтому такое огромное количество ядер CUDA реализовано в видеокартах. И учитывая, как графические процессоры разрабатываются и оптимизируются специально для этой цели, их ядра могут быть намного меньше, чем у гораздо более универсального CPU.
И как ядра CUDA влияют на производительность в игре?
По сути, любые графические настройки, которые требуют одновременного выполнения вычислений, значительно выиграют от большего количества ядер CUDA. Наиболее очевидными из них считается освещение и тени, но также включены физика, а также некоторые типы сглаживания и окклюзии окружающей среды.
Программная архитектура [ править | править код ]
Первоначальная версия CUDA SDK была представлена 15 февраля 2007 года. В основе интерфейса программирования приложений CUDA лежит язык Си с некоторыми расширениями. Для успешной трансляции кода на этом языке в состав CUDA SDK входит собственный Си-компилятор командной строки nvcc компании Nvidia. Компилятор nvcc создан на основе открытого компилятора Open64 и предназначен для трансляции host-кода (главного, управляющего кода) и device-кода (аппаратного кода) (файлов с расширением .cu) в объектные файлы, пригодные в процессе сборки конечной программы или библиотеки в любой среде программирования, например, в NetBeans.
В архитектуре CUDA используется модель памяти грид, кластерное моделирование потоков и SIMD-инструкции. Применима не только для высокопроизводительных графических вычислений, но и для различных научных вычислений с использованием видеокарт nVidia. Учёные и исследователи широко используют CUDA в различных областях, включая астрофизику, вычислительную биологию и химию, моделирование динамики жидкостей, электромагнитных взаимодействий, компьютерную томографию, сейсмический анализ и многое другое. В CUDA имеется возможность подключения к приложениям, использующим OpenGL и Direct3D. CUDA — кроссплатформенное программное обеспечение для таких операционных систем, как Linux, Mac OS X и Windows.
22 марта 2010 года nV >
CUDA API References
- CUDA Runtime API
- The CUDA runtime API.
- CUDA Driver API
- The CUDA driver API.
- CUDA Math API
- The CUDA math API.
- cuBLAS
- The cuBLAS library is an implementation of BLAS (Basic Linear Algebra Subprograms) on top of the NVIDIA CUDA runtime. It allows
the user to access the computational resources of NVIDIA Graphical Processing Unit (GPU), but does not auto-parallelize across
multiple GPUs. - NVBLAS
- The NVBLAS library is a multi-GPUs accelerated drop-in BLAS (Basic Linear Algebra Subprograms) built on top of the NVIDIA
cuBLAS Library. - nvJPEG
- The nvJPEG Library provides high-performance GPU accelerated JPEG
decoding functionality for image formats commonly used in deep learning and hyperscale
multimedia applications. - cuFFT
- The cuFFT library user guide.
- cuRAND
- The cuRAND library user guide.
- cuSPARSE
- The cuSPARSE library user guide.
- NPP
- NVIDIA NPP is a library of functions for performing CUDA accelerated
processing. The initial set of functionality in the library focuses on
imaging and video processing and is widely applicable for developers in
these areas. NPP will evolve over time to encompass more of the compute
heavy tasks in a variety of problem domains. The NPP library is written
to maximize flexibility, while maintaining high performance. - NVRTC (Runtime Compilation)
-
NVRTC is a runtime compilation library for CUDA C++.
It accepts CUDA C++ source code in character string form and creates
handles that can be used to obtain the PTX.
The PTX string generated by NVRTC can be loaded by cuModuleLoadData and
cuModuleLoadDataEx, and linked with other modules by cuLinkAddData of
the CUDA Driver API.
This facility can often provide optimizations and performance not
possible in a purely offline static compilation. - Thrust
- The Thrust getting started guide.
- cuSOLVER
- The cuSOLVER library user guide.
GPU Bound. Как перенести на видеокарту все и немножко больше. Анимации
Когда-то давно, было огромным событием появления на GPU блока мультитекстурирования или hardware transformation & lighting (T&L). Настройка Fixed Function Pipeline была магическим шаманством. А те кто умел включать и использовать расширенные возможности конкретных чипов через D3D9 API hacks, считали себя познавшими дзен. Но время шло, появились шейдеры. Сначала, сильно лимитированные как по функционалу, так и по длине. Далее все больше возможностей, больше инструкций, больше скорость выполнения. Появился compute (CUDA, OpenCL, DirectCompute), и область применения мощностей видеокарт стала стремительно расширяться.
В этом цикле (надеюсь) статей я постараюсь расказать и показать, как «необычно» можно применить возможности современного GPU, при разработке игр, помимо графических эффектов. Первая часть будет посвящена анимационной системе. Все что описано, основано на практическом опыте, реализовано и работает в реальных игровых проектах.
Видеокарта и типы памяти
- Регистровая память (register) является самой быстрой из всех видов. Определить количество регистров доступных GPU можно с помощью уже хорошо известной функции cudaGetDeviceProperties. Рассчитать количество регистров, доступных одной нити GPU, так же не составляет труда, для этого необходимо разделить общее число регистров на произведение количества нитей в блоке и количества блоков в гриде. Все регистры GPU 32 разрядные. В CUDA нет явных способов использования регистровой памяти, всю работу по размещению данных в регистрах берет на себя компилятор.
- Локальная память (local memory) может быть использована компилятором при большом количестве локальных переменных в какой-либо функции. По скоростным характеристикам локальная память значительно медленнее, чем регистровая. В документации от nVidia рекомендуется использовать локальную память только в самых необходимых случаях. Явных средств, позволяющих блокировать использование локальной памяти, не предусмотрено, поэтому при падении производительности стоит тщательно проанализировать код и исключить лишние локальные переменные.
- Глобальная память (global memory) – самый медленный тип памяти, из доступных GPU. Глобальные переменные можно выделить с помощью спецификатора __global__, а так же динамически, с помощью функций из семейства cudMallocXXX. Глобальная память в основном служит для хранения больших объемов данных, поступивших на device с host’а, данное перемещение осуществляется с использованием функций cudaMemcpyXXX. В алгоритмах, требующих высокой производительности, количество операций с глобальной памятью необходимо свести к минимуму.
- Разделяемая память (shared memory) относиться к быстрому типу памяти. Разделяемую память рекомендуется использовать для минимизации обращение к глобальной памяти, а так же для хранения локальных переменных функций. Адресация разделяемой памяти между нитями потока одинакова в пределах одного блока, что может быть использовано для обмена данными между потоками в пределах одного блока. Для размещения данных в разделяемой памяти используется спецификатор __shared__.
- Константная память (constant memory) является достаточно быстрой из доступных GPU. Отличительной особенностью константной памяти является возможность записи данных с хоста, но при этом в пределах GPU возможно лишь чтение из этой памяти, что и обуславливает её название. Для размещения данных в константной памяти предусмотрен спецификатор __constant__. Если необходимо использовать массив в константной памяти, то его размер необходимо указать заранее, так как динамическое выделение в отличие от глобальной памяти в константной не поддерживается. Для записи с хоста в константную память используется функция cudaMemcpyToSymbol, и для копирования с device’а на хост cudaMemcpyFromSymbol, как видно этот подход несколько отличается от подхода при работе с глобальной памятью.
- Текстурная память (texture memory), как и следует из названия, предназначена главным образом для работы с текстурами. Текстурная память имеет специфические особенности в адресации, чтении и записи данных. Более подробно о текстурной памяти я расскажу при рассмотрении вопросов обработки изображений на GPU.
Преимущества [ править | править код ]
По сравнению с традиционным подходом к организации вычислений общего назначения посредством возможностей графических API, у архитектуры CUDA отмечают следующие преимущества в этой области:
- Интерфейс программирования приложений CUDA (CUDA API) основан на стандартном языке программирования Си с некоторыми ограничениями. По мнению разработчиков, это должно упростить и сгладить процесс изучения архитектуры CUDA
- Разделяемая между потоками память (shared memory) размером в 16 Кб может быть использована под организованный пользователем кэш с более широкой полосой пропускания, чем при выборке из обычных текстур
- Более эффективные транзакции между памятью центрального процессора и видеопамятью
- Полная аппаратная поддержка целочисленных и побитовых операций
- Поддержка компиляции кода GPU средствами открытого проекта LLVM
Mac OSX
When installing CUDA on Mac OSX, you can choose between the Network Installer and the Local Installer. The Network Installer
allows you to download only the files you need. The Local Installer is a stand-alone installer with a large initial download.
For more details, refer to the Mac Installation Guide.
Perform the following steps to install CUDA and verify the installation.
- Launch the installer.
- Read and accept the EULA.
- Select «next» to download and install all components.
- Once the downloads and installations complete, click «next» to move to the install finished screen.
- Click «close» to close the installer.
- Open a terminal.
-
Set up the development environment by modifying the PATH and DYLD_LIBRARY_PATH variables:
$ export PATH=/Developer/NVIDIA/CUDA-11.0/bin${PATH:+:${PATH}} $ export DYLD_LIBRARY_PATH=/Developer/NVIDIA/CUDA-11.0/lib\ ${DYLD_LIBRARY_PATH:+:${DYLD_LIBRARY_PATH}} - Install Xcode via the App Store.
-
Install Xcode command-line tools:
$ xcode-select --install
-
Install a writable copy of the samples then build and run the nbody sample:
$ cuda-install-samples-11.0.sh ~ $ cd ~/NVIDIA_CUDA-11.0_Samples/5_Simulations/nbody $ make $ ./nbody
Вывод
Надеемся, что это помогло пролить некоторый свет на то, чем на самом деле являются ядра CUDA, что они делают и насколько они важны. Прежде всего, мы надеемся, что помогли развеять любые ваши заблуждения по этому поводу.
CUDA (изначально аббр. от англ. Compute Unified Device Architecture ) — программно-аппаратная архитектура параллельных вычислений, которая позволяет существенно увеличить вычислительную производительность благодаря использованию графических процессоров фирмы Nvidia.
CUDA SDK позволяет программистам реализовывать на специальных упрощённых диалектах языков программирования Си, C++ и Фортран алгоритмы, выполнимые на графических и тензорных процессорах Nv > . Архитектура CUDA даёт разработчику возможность по своему усмотрению организовывать доступ к набору инструкций графического или тензорного ускорителя и управлять его памятью. Функции, ускоренные при помощи CUDA, можно вызывать из различных языков, в т.ч. Python , MATLAB и т.п.






